人工智能里的数学修炼 | 概率图模型 : 隐马尔可夫模型
人工智能里的数学修炼 | 概率图模型 : 隐马尔可夫模型
人工智能里的数学修炼 | 隐马尔可夫模型:前向后向算法
人工智能里的数学修炼 | 隐马尔可夫模型 : 维特比(Viterbi)算法解码隐藏状态序列
人工智能里的数学修炼 | 隐马尔可夫模型:基于EM的鲍姆-韦尔奇算法求解模型参数
概率图模型(probabilistic graphical model)是一类用图来表达变量相关关系的概率模型。它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即“变量关系图”。根据边的性质不同,概率图模型可大致分为两类:
第一类是使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网(Bayesian network);
第二类是使用无向图表示变量间的相关关系,称为无向图模型或马尔可夫网(Markov network)
隐马尔可夫(hidden markov model, HMM)是结构最简单的动态贝叶斯网,这是一种著名的有向图模型,主要用于时序建模,在语音识别、自然语言处理等领域有着广泛的应用
一、隐马尔可夫模型
隐马尔可夫模型中的变量可以分为两组。
第一组是状态变量 y 1 , y 2 , . . . , y n {y_{1},y_{2},...,y_{n}} y1,y2,...,yn, 其中 y i ϵ Y y_{i}\epsilon Y yiϵY表示第 i i i个时刻系统的状态。通常假定状态变量是隐藏的、不可被观测的,因此状态变量又被称为隐变量。在隐马尔可夫模型中,系统通常在多个状态 s 1 , s 2 , . . . , s N {s_{1},s_{2},...,s_{N}} s1,s2,...,sN之间转换,因此状态变量 y i y_{i} yi的取值范围是有 N N N个可能取值的离散空间。
第二组是观测变量 x 1 , x 2 , . . . , x n {x_{1},x_{2},...,x_{n}} x1,x2,...,xn, 其中 x i ϵ X x_{i}\epsilon X xiϵX表示第 i i i时刻的观测值。观测变量通常是可以是连续型也可以是离散型,这里仅考虑离散型观测变量,并假定其取值范围为 X X X为 o 1 , o 2 , . . . , o M {o_{1},o_{2},...,o_{M}} o1,o2,...,oM。
隐马尔可夫模型的状态变量与观测变量的基本结构如下图所示
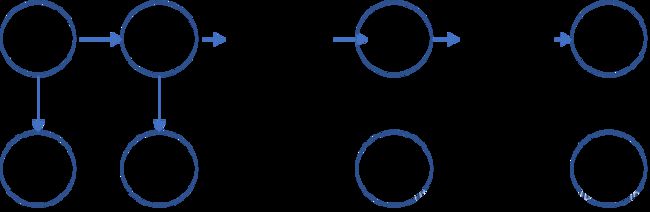
上图中的箭头表示了变量间的依赖关系,同时也解释了隐马尔可夫模型的两个重要假设
- 齐次马尔可夫链假设: t t t时刻的状态 y t y_{t} yt 仅依赖于 t − 1 {t-1} t−1时刻的状态 y t − 1 y_{t-1} yt−1,与其余状态无关,即系统下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态
- 观测独立性假设: 在任一时刻,观测变量的取值仅依赖于状态变量,即 x t {x_{t}} xt由 y t {y_{t}} yt确定,与其他状态变量和观测变量无关
这两个假设大大简化了隐马尔可夫模型的复杂度,使其得到广泛应用
二、隐马尔可夫模型的三组参数
第一小节介绍了隐马尔可夫模型的基本图结构,但确定一个隐马尔可夫模型还需要三组参数
-
状态转移概率:模型在各个状态之间转移的概率,记为矩阵 A = [ a i j ] N × N A=[a_{ij}]_{N \times N} A=[aij]N×N, 其中
a i j = P ( y t + 1 = s j ∣ y t = s i ) , 1 ⩽ i , j ⩽ N a_{ij}=P(y_{t+1}=s_{j}|y_{t}=s_{i}), 1 \leqslant i,j \leqslant N aij=P(yt+1=sj∣yt=si),1⩽i,j⩽N 表示在任一时刻 t t t,若当前状态为 s i s_{i} si,下一时刻状态为 s j s_{j} sj的概率 -
输出观测概率:模型根据当前状态获得各个观测值的概率,记为矩阵 B = [ b i j ] N × M B=[b_{ij}]_{N \times M} B=[bij]N×M, 其中
b i j = P ( x t = o j ∣ y t = s i ) , 1 ⩽ i ⩽ N , 1 ⩽ j ⩽ M b_{ij}=P(x_{t}=o_{j}|y_{t}=s_{i}), 1 \leqslant i \leqslant N, 1 \leqslant j \leqslant M bij=P(xt=oj∣yt=si),1⩽i⩽N,1⩽j⩽M表示在任一时刻 t t t,若状态为 s i {s_{i}} si,则观测值 o j {o_{j}} oj被获取的概率 -
初始状态概率:模型在初始时刻各状态出现的概率,通常记为 π = ( π 1 , π 2 , . . . , π N ) \pi=(\pi_{1},\pi_{2},...,\pi_{N}) π=(π1,π2,...,πN), 其中
π i = P ( y 1 = s i ) \pi_{i}=P(y_{1}=s_{i}) πi=P(y1=si)即模型的初始状态为 s i s_{i} si的概率
通过指定上述三组参数 λ = { A , B , π } \lambda=\{A,B,\pi\} λ={A,B,π},就能确定一个隐马尔可夫模型,它按照如下过程产生观测序列 x 1 , x 2 , . . , x n {x_{1},x_{2},..,x_{n}} x1,x2,..,xn:
- 设置 t = 1 t=1 t=1,并根据初始状态概率 π \pi π选择初始状态 y 1 y_{1} y1;
- 根据状态 y t y_{t} yt和输出观测概率 B B B选择观测变量取值 x t x_{t} xt;
- 根据 y t y_{t} yt和状态转移矩阵 A A A转移模型状态,确定 y t + 1 y_{t+1} yt+1;
- 若 t < n t<n t<n,设置 t = t + 1 t=t+1 t=t+1, 并转到第2步,否则停止
三、 隐马尔可夫模型的三个基本问题
在实际应用中,人们常关注隐马尔可夫模型的三个基本问题:
- 生成观察序列概率:给定模型 λ = { A , B , π } \lambda=\{A,B,\pi\} λ={A,B,π}, 如何有效计算其产生观测序列 x = x 1 , x 2 , . . , x n x={x_{1},x_{2},..,x_{n}} x=x1,x2,..,xn的概率 P ( x ∣ λ ) P(x|\lambda) P(x∣λ)?换而言之,如何评估模型与观测序列之间的匹配程度。这个问题的求解需要用到前向后向算法,是HMM模型三个问题中最简单的
- 预测问题:给定模型 λ = { A , B , π } \lambda=\{A,B,\pi\} λ={A,B,π}和观测序列,如何找到与此观测序列最匹配的状态序列 y = y 1 , y 2 , . . . , y n y={y_{1},y_{2},...,y_{n}} y=y1,y2,...,yn?换言之,如何根据观测序列推断出隐藏的模型状态?这个问题的求解需要用到基于动态规划的维特比算法,这个问题是HMM模型三个问题中复杂度居中的算法
- 模型参数学习问题:给定观测序列 x = x 1 , x 2 , . . . , x n x={x_{1},x_{2},...,x_{n}} x=x1,x2,...,xn, 如何调整模型参数 λ = { A , B , π } \lambda=\{A,B,\pi\} λ={A,B,π}使得该序列出现的概率 P ( X ∣ λ ) P(X| \lambda) P(X∣λ)最大?即如何训练模型使得其能最好的描述观测数据?这个问题的求解需要用到基于EM算法的鲍姆-韦尔奇算法, 这个问题是HMM模型三个问题中最复杂的。
上述三个问题在实际应用中都有重要意义。例如许多任务需根据以往的观测序列 x = x 1 , x 2 , . . . , x n − 1 x={x_{1},x_{2},...,x_{n-1}} x=x1,x2,...,xn−1来推测当前时刻最有可能的观测值 x n x_{n} xn,这显然可以转化为求取概率 P ( x ∣ λ ) P(x|\lambda) P(x∣λ), 即上述第一个问题;在语音识别等任务中,观测值为语音信号,隐藏状态为文字,目标就是根据观测信号来推断最有可能的状态序列,即对应上述的第二个问题;至于第三个问题,则是对应于绝大多数机器学习模型所存在的训练模型参数的问题。
reference
[1] 机器学习,周志华