Flink实战--实战案例
本文以flink本地模式 进行各个场景的实战开发
flink本地运行模式
Flink支持两种不同的本地运行机制:
- LocalExecutionEnvironment启动完整的Flink运行环境,包括一个JobManager和一个TaskManager。这些包含了内存管理以及在集群模式下运行时所运行的所有内部算法。 LocalEnvironment也可以向Flink传入用户自定义配置。
Configuration conf = new Configuration(); conf.setFloat(ConfigConstants.TASK_MANAGER_MEMORY_FRACTION_KEY, 0.5f); final ExecutionEnvironment env = ExecutionEnvironment.createLocalEnvironment(conf); - CollectionEnvironment在Java集合上运行Flink程序(executing the Flink program on Java collections)。这种模式不会启动完整的Flink运行环境,因此运行开销比较低以及轻量级。例如,DataSet的map转换操作将map()函数应用于Java列表中的所有元素上。
环境获取
Flink 批处理环境
val env = ExecutionEnvironment.getExecutionEnvironment
Flink 流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
实战案例
基于文件(本地,hdfs)的wordcount
public class FunctionTest {
public static void main(String[] args) throws Exception {
//创建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//读取文本文件中的数据
DataStreamSource streamSource = env.readTextFile("C:/flink_data/1.txt");
//进行逻辑计算
SingleOutputStreamOperator> dataStream = streamSource
.flatMap(new Splitter())
.keyBy(0)
.sum(1);
dataStream.print();
//设置程序名称
env.execute("Window WordCount");
}
}
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class Splitter implements FlatMapFunction> {
@Override
public void flatMap(String sentence, Collector> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2(word, 1));
}
}
}
二、基于socket的wordcount(scala版本)
1.发送数据
在linux机器上执行 nc-lk发送数据
nc -lk 9999
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object ScortWc {
def main(args: Array[String]): Unit = {
//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("127.0.0.11", 9999)
//3.进行wordcount计算
val counts = text.flatMap(_.toLowerCase.split(" ") filter (_.nonEmpty))
.map((_, 1))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
//4.打印结果
counts.print
//触发计算
env.execute("Window Stream WordCount")
}
}
执行效果

三.基于kafka的wordcount
添加maven依赖
org.apache.flink
flink-connector-kafka-0.9_2.10
1.1.3
程序代码
object DataFkafka {
def main(args: Array[String]): Unit = {
//设置kafka连接参数
val properties = new Properties()
properties.setProperty("bootstrap.servers", "ip1:9092,ip2:9092,i:9092");
properties.setProperty("zoo3pkeeper.connect", "ip4:2181,ip5:2181");
properties.setProperty("group.id", "res");
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置时间类型
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置检查点时间间隔
env.enableCheckpointing(1000)
//设置检查点模式
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//创建kafak消费者,获取kafak中的数据
val myConsumer: FlinkKafkaConsumer010[String] = new FlinkKafkaConsumer010[String]("flink", new SimpleStringSchema(), properties)
val kafkaData: DataStream[String] = env.addSource(myConsumer)
kafkaData.print()
//数据保存到hdfs
kafkaData.writeAsText("hdfs://ip6:9000/output/flink.txt")
print("kafka")
//设置程序名称
env.execute("data_from_kafak_wangzh")
}
}
四,事件时间的使用 event time
数据准备
准备一组时间乱序的数据 然后使用 nc -lk 9999 这个指令模拟实时数据流
67000,boos2,pc1,200.0
62000,boos2,pc2,500.0
78000,boos2,pc2,600.0
71010,boos2,pc2,700.0
62010,boos2,pc2,500.0
67000 6200 是时间的毫秒值 正好差5s
需求
计算真实数据流,五秒钟之内的价格总和
显然如果不使用事件时间,是无法区分事件真实时间的,因此这个这种需求下必须使用event time、也就是处理乱序的数据流。
代码实现
/**
* Created by ${WangZhiHua} on 2018/10/31
*/
object EventTime_test {
def main(args: Array[String]) {
import org.apache.flink.api.scala._
//1.创建执行环境,并设置为使用EventTime
val env = StreamExecutionEnvironment.getExecutionEnvironment
//置为使用EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//2.创建数据流,并进行数据转化
val source = env.socketTextStream("127.0.0.11", 9999)
//定义一个样例类去封装数据
case class SalePrice(time: Long, boosName: String, productName: String, price: Double)
val dst1: DataStream[SalePrice] = source.map(value => {
val columns = value.split(",")
SalePrice(columns(0).toLong, columns(1), columns(2), columns(3).toDouble)
})
//3.使用EventTime进行求最值操作
val dst2 = dst1
//提取消息中的时间戳属性
.assignAscendingTimestamps(_.time)
.keyBy(_.productName)
//.timeWindow(Time.seconds(5))//设置window方法一
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(3)
//设置window方法二
// .max("price")
//4.显示结果
dst2.print()
//5.触发流计算
env.execute()
}
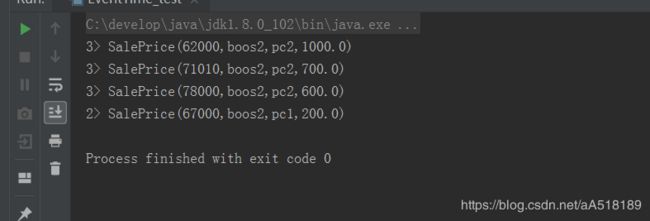
打印结果
五.生成并跟踪watermark代码
我们从socket接收数据,然后经过map后立刻抽取timetamp并生成watermark,之后应用window来看看watermark和event time如何变化,才导致window被触发的
package com.missfresh.flinkCore
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object WaterMarks_test {
def main(args: Array[String]): Unit = {
import org.apache.flink.api.scala._
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//获取实时流
val input = env.socketTextStream("127.0.0.11", 9999)
val inputMap = input.map(f => {
val arr = f.split(",")
val code = arr(0)
val time = arr(1).toLong
(code, time)
})
val watermark = inputMap.
//获取时间戳和水印
assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] {
var currentMaxTimestamp = 0L
val maxOutOfOrderness = 10000L
//最大允许的乱序时间是10s
var a: Watermark = null
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
//获取水印
override def getCurrentWatermark: Watermark = {
a = new Watermark(currentMaxTimestamp - maxOutOfOrderness)
a
}
//获取时间戳
override def extractTimestamp(t: (String, Long), l: Long): Long = {
val timestamp = t._2
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp)
println("timestamp:" + t._1 + "," + t._2 + "|" + format.format(t._2) + "," + currentMaxTimestamp + "|" + format.format(currentMaxTimestamp) + "," + a.toString)
timestamp
}
})
val window = watermark
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply(new WindowFunctionTest)
window.print()
env.execute()
}
class WindowFunctionTest extends WindowFunction[(String, Long), (String, Int, String, String, String, String), String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[(String, Int, String, String, String, String)]): Unit = {
val list = input.toList.sortBy(_._2)
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
out.collect(key, input.size, format.format(list.head._2), format.format(list.last._2), format.format(window.getStart), format.format(window.getEnd))
}
}
}
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
