NLP-词和文档向量化方法
0 为什么要向量化?
向量化文本就可以将一些文本处理问题转换为机器学习问题:
0.1 机器学习问题:文本分类,文本聚类,情感分析等,输入到seq2seq等模型需要数字化的词的表示形式。
0.2 文本、关键词检索问题(算相似度):关键词搜索,文档检索等
计算机去理解文本的语义核心在于通过词和上下文统计词的分布去表示文本,或通过几何的视角通过词上下文去找到词在空间中的几何表示(深度学习方法)。
这也引出另一个问题,为何要进行文本的数据清洗?因为很多要向量化文本的算法都是基于词的统计表示的,所以尽可能将相似或同样意思的词表示为同一个词,防止对后面模型产生噪声。
1 词向量化
1.1 Encoding方式:
1.1.1 Dic词典形式
为什么要词典表示?在Seq2Seq等模型需要文本的数字化表示。
每一个词有一个唯一的ID表示。生成ID可以靠Hash或遇到词的顺序等。
缺点:不能表示词的相似性(没有语义信息)
1.1.2 Onehot encoding
One-hot Representation 就是用一个很长的向量来表示一个词,向量长度为词典的大小N,每个向量只有一个维度为1,其余维度全部为0,为1的位置表示该词语在词典的位置。
举个常见例子:
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁,也就是给每个词分配一个数字 ID。但这种表示方式有两个缺点:
(1)容易受维数灾难的困扰,每个词语的维度就是语料库字典的长度。
(2)词语的编码往往是随机的,导致不能很好地刻画词与词之间的相似性
参考:https://www.cnblogs.com/zeze/p/8178836.html
1.2 分布式表示
Distributed representation 最早由 Hinton在1986 年提出。其依赖思想是:词语的语义是通过上下文信息来确定的,即相同语境出现的词,其语义也相近。
Distributed Representation与one-hot representation对比
- 在形式上,one-hot representation 词向量是一种稀疏词向量,其长度就是字典长度,而Distributed Representation是一种固定长度的稠密词向量。一般长这样:[0.792, −0.177, −0.107, 0.109, −0.542, …]
- 在功能上,Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。
关于生成 Distributed representation 形式的词向量,除了word2vec外,还有其他生成的方式。如:LSA矩阵分解模型、 PLSA 潜在语义分析概率模型、LDA 文档生成模型。但本文只关注 word2vec 这种方式,其他不做介绍。
参考:https://www.cnblogs.com/zeze/p/8178836.html
1.2.0 统计系列:LDA等
LDA等主题模型的输入是文档-词矩阵,算法输出的结果是能获得,文档-主题矩阵和主题-词矩阵。其中的主题-词矩阵就可以用来获取到词的向量表示,每个向量代表这个词的主题,每个维度代表主题。
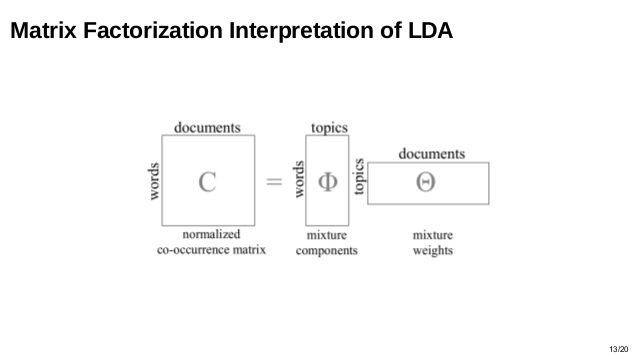
参考:https://www.cnblogs.com/pinard/p/6831308.html
1.2.1 深度学习系列:cbow / skip gram等
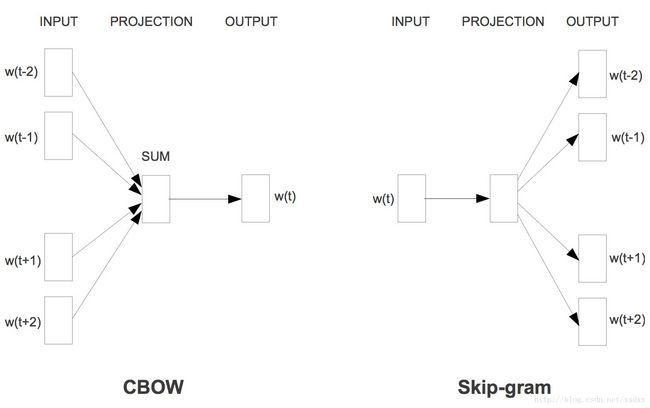
将文本中的某个词编码在深度学习模型的输入和输出中,然后将词通过模型编码成的向量代表最后词的向量化表示。
参考:Vector Representations of Words
2 文本向量化
2.1 词频统计形式
2.1.1 词袋
一篇文档里面有很多很多句子,每个句子又是由一个个的词组成。词袋模型,通俗地讲,就是:把一篇文档看成词袋,里面装着一个个的词。
从而,将一篇文档转化成了一个个的词(或者称之为 term),显然地,文档转化成一个个的词之后,词与词之间的顺序关系丢失了。
词频统计技术是很直观的,文本被分词之后。 用每一个词作为维度key,有单词对应的位置为1,其他为0,向量长度和词典大小相同。然后给每个维度使用词频当作权值。词频统计技术默认出现频率越高的词权重越大。
举例说明:
原文:
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
分词结果:
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
列出维度:我,喜欢,看,电视,电影,不,也.
统计词频:
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
转换为向量:
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
可以看出:词频统计技术直观、简单。但是有明显的缺陷:中文中有的词汇,如:“我”,“的”出现频率很高,因此会赋予较高的权值,但是这些词汇本身无意义。因此若要使用词频统计技术,必须要引入停用词将这些无意义的词汇进行过滤。
参考:https://www.cnblogs.com/chengyuanqi/p/7363909.html
2.1.2 tf-idf
在给定的文档集合C和词典D的情况下,如何来衡量一个词(term)的权重呢?即如何计算这个实数值呢?
3.2.1 tf值
tf(term frequency),是指 term 在某篇文档中出现的频率。假设文档集合中共有10篇文章,词:''国家'',在文档1中出现了6次,那么对于文档1而言,'国家'这个词的tf值为6。因此,tf 是针对单篇文档而言的,即:某个词在这篇文档中出现了多少次。
3.2.2 idf值
'国家'这个词在文档1中的idf值 由 词(term) 出现在各个文档中数目来决定,比如'国家'一共在8篇文档中出现了,那么对于文档1而言,'国家'这个词的idf值由如下公式计算:
idft=logNdft
其中,N=10 表示文档集合中共有10篇文章。dft=8dft=8,表示 term 国家 在8篇文档中出现了。因此,idf 值是针对所有文档(文档集合)而言的,即:数一数这个词都出现在哪些文档中。
而TF-IDF,就是将tf值乘以idf值:
TF−IDF=tf∗idf
前面提到,将文档向量化,需要给文档中的每个词赋一个实数值,这个实数值,就是通过tf*idf得到。
2.2 分布式表示
解释参考:词向量中的分布式表示
2.2.1 lda系列
参考:1.2.0 词向量化表示中的LDA方法
2.2.2 deep learning
将文档id和文档内容编码在深度学习模型的输入和输出中,然后将文章通过模型编码成的向量代表最后文档的向量化表示。
模型结构,编码方式有多种。
参考:Distributed Representations of Sentences and Documents
友情推荐:ABC技术研习社
为技术人打造的专属A(AI),B(Big Data),C(Cloud)技术公众号和技术交流社群。
