《spring boot2精髓》读书笔记
As always,福利置顶,PDF资源下载地址:链接
https://pan.baidu.com/s/1aXh8AAteJL_Hd5DqEEDQtw 提取码:4yhz
第一章 Java EE简介
Java EE 有相应的规范实现,包括但不限于:
Web 支持
事务支持
消息服务
数据库持久层
Container
JWS
JAX-RS
JNDI
JAXP/JAXB
JAX-RPC
JACC
Java EE Application Server
所有这些规范和技术组成Java EE架构:
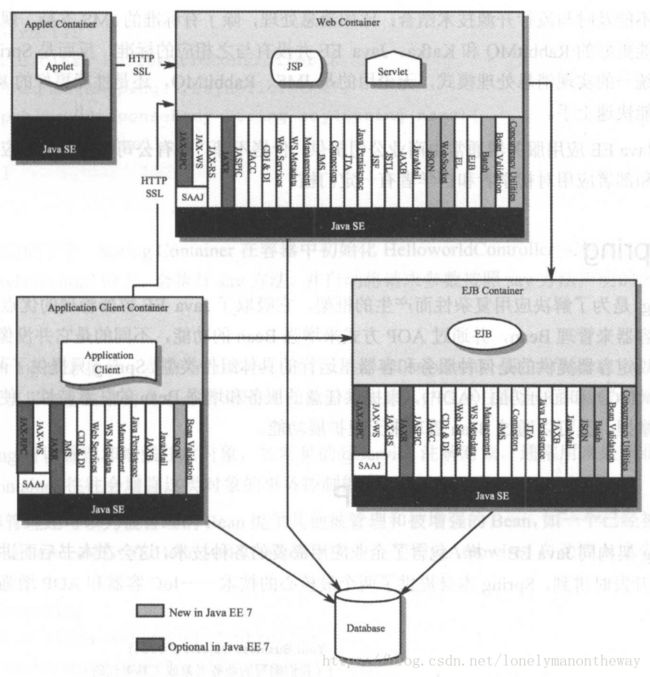
Java EE的缺点:
- 过于复杂;
- 追求分布式;
- 不能及时与流行开源技术结合;
- Java EE 应用服务器收费。
spring的提出,核心功能仅仅只是Aop和IoC,发展如火如荼之后也有缺点,spring boot应运而生。
第二章 spring boot基础
JDK安装、maven配置、IoC与bean容器、注解、AOP示例。
第三章 MVC框架
Ant通配符:
*: 匹配任意字符;
**:匹配任意路径;
?:匹配单个字符;
如果一个请求,有多个@RequestMapping可以匹配,通常是更具体的匹配会去响应这个请求:
有通配符的优先级低于没有通配符的;
有'**'低于有'*';
consumes & produces
consumes 意味着请求的HTTP头的content-type的媒体类型,带错content-typ的请求会报错:
there was an unexpected error(type=unsupported content type, status=415), content type ‘’ not supported.
produces 属性对应于 HTTP 请求 的 Accept 字段,通常浏览器都会将 Accept 设置为*.*
验证框架:
sb支持JSR-303、bean框架
第四章 视图技术
第五章 数据库访问
java里有两类数据库访问方式:
- 如mybatis、作者自研的BeetlSQL、Spring JDBC template这一类,以SQL为核心。灵活,学习门槛较低,更能适应大型的互联网和企业应用。
- hibernate、spring data以对象为核心,以 Java Entity 为 中心, 将实体和实体关系对应到数据库 的表和表关系,对实体和实体关系的操作会映射到数据库操作。
Spring JDBC Template,复杂的结果集通过实现 RowMapper 接口来映射到 Java 对象。
JdbcTemplate 允许查询结果返回 一个 Map 而不是 POJO ,这样免去 RowMapper 的工作,数据库的字段名就是 Map 的 key:
String sql = "select * from user where id=?";
Map map= jdbcTempalte.queryForMap(sql, userid);
缺点:使用 Map 作为查询结果有非常多的弊端,很难通过 Map 了解查询结果集;鉴于泛型擦除,返回结果类型未知;以及数据库不一样,同样的词,有可能返回不同的数据类型,导致数据库平台不兼容。
数据库插入,对于 MySQL、SQL Server等数据库,含有自增序列 , 则需要提供一个 KeyHolder 来放置返回的序列。
NamedParameterJdbcTemplate 继承 JdbcTemplate,不同于 JdbcTemplate , 对 SQL 中的参数只支持传统的"?"占位符。 NamedParameterJdbcTemplate 允许 SQL 中使用参数的名字作为占位符:
String sql = "select count(1) from user where department_id=:deptId";
MapSqlParameterSource namedParameters = new MapSqlParameterSource();
namedParameters.addValue("dept Id", departmentId);
BeetlSQL 介绍
第六章 spring data jpa
Spring Data JPA, 基于hibernate,两个重要的特性:
spring.jpa.hibernate.ddl-auto,自动建库。
spring.jpa.show-sql,打印SQL。
自动建表是个很酷的特性,但对于常规项目用处井不大,因为大多数项目都是在需求分析后建立物理模型 。 也就是先有数据库表设计,随后才是 Spring Boot 应用,因此数据库的 DDL 语句早已经具备 。 从另一方面讲,项目数据库管理人员、需求分析人员,甚至是项目经理并不喜欢 Hibernate 创建的表结构,比如,它的外键命名就很随机,不符合命名规范 。 自动建表对于小型项目或者工具类项目(如工作流引擎)还是很方便的 。
一个部门拥有多个用户 ,使用 Set 而不是 List,是因为 Set 结构是存放不同元素的集合,这也是 JPA 要求的。
Repository:
CrudRepository
PagingAndSortingRepository
JpaRepository
自定义Repository
Repository 提供 save 方法来保存或者更新一个实体,默认情况下,如果 Entity 主键属性为空,则认为是新的实体,保存实体;反之,如果 Entity 主键属性不为空,则更新实体 。
Spring Data 提供另外一个判断实体是否是“新的实体”的方法一Entity 实现Persistable 接口的 isNew 方法。
Hibernate 的 showSql 配置只打印 SOL,并未像 BeetlSQL 那样同时打印 SOL参数、执行时间等信息,如果需要这些信息,可以使用第三方工具 log4jdbc 来完成 。
无论是 JPQL , 还是 SQL 语句,都支持 “命名参数” :
@Query(value="select * from user where name=:name and department_id=:departmentId", nativeQuery=true)
public User nativeQuery2 (String name, Integer departmentId);
查询时可以使用 Pageable 和 Sort 来对协助“ JPQL ” 完成翻页和排序:
@Query(value="select u from User u where u.department.id=?1")
public Page<User> queryUsers(Integer departmentid, Pageable page );
@Query 还允许 SQL 更新、删除语句,此时必须搭配@Modifying 使用,比如:
@Modifying
@Query("update User u set u.name= ?1 where u.id=?2")
int updateName(String name, Integer id) ;
第十一章 MongoDB
模式自由,不需要事先定义文档格式,可以任意改变文档格式。
MongoDB 以下面线开头的字段都有特殊意义,表示文档主键,如果文档没有提供此主键,则系统自动生成一个 ObjectID 类型的主键。推荐在SB应用中,由应用来定义一个主键而不是由 MongoDB 生成。用12字节存储,分别是4字节时间戳,3字节机器唯一标识,2 字节的进程标识,以及最后 3 字节的自增, ObjectID 转成可读的 16 进制看起来是这个样子:4e7020cb7cac8laf7136236b。
replaceOne 与 updateOne,前者是替换整个文档,而后者是更新部分文档 。这两个方法都只替换匹配的第一条记录,如果有多条记录匹配,可以使用 updateMany。options 有如下属性可 以控制更新特性:
upsert,默认为 false , 如果设置成 true ,未匹配的文档会 insert 到数据库中 。
writeConcern ,对写入进行配置 ,包含以下属性 。
- w , 默认是{w:0}, 表示写入后不需要数据库发送确认(ACK ), 这样性能很高 ;{w:1},数据写入到主库就向客户端发送确认;{w:“majority”},数据写入到所有节点后向客户端发送确认。
- wtimeout , 当 w 大于1的时候,设置一个等待时间,单位为毫秒,超过这个时间,即使数据成功写入到库中,客户端也得到一个错误信息 。
"%"字符在 URI 中使用 %25,这是URI Encode 的结果。
mongoTemplate底层使用 mongo-driver,可以使用 execute 方法来直接操作 MongoDB:
publicT execute (DbCallback action)
DbCallback 提供底层驱动的 MongoDatabase 类来访问MongoDB。
第十二章 Redis
Redis 在内存中存储数据,因此原则上,存放在 Redis 中的数据不应该大于内存容量,否则会因为操作系统虚拟内存导致性能降低 。Redis 一共有 14 个命令组、两百多个命令。
DECRBY/INCRBY , 数字类型数据减去某个指定的整数或者增加某个指定整数。
INCRBYFLOAT , 数字增加一个浮点数,负数表示减去。
Redis List 类型类似 Java 的 LinkedList,通过链表来完成,向其添加元素速度非常快,按照索引方式获取元素比较慢。
rpush,将多个值放入 list 尾部;
Ipush,将多个值放入 list 头部;
todo
第十三章 elastic-search
第十五章 Spring Session
第十六章 Spring Boot 和 ZooKeeper
zk,分布式应用可以基于它实现协调服务,比如同步、集群、领导选取,以及分布式系统的配置管理、命名服务。使用文件系统目录树作为数据模型。能够保证操作的时序性:zk 对每次更新都有时间戳记录,从而保证操作的时序性,保证可以完成更高层次的协调服务,如分布式锁。zk 提供的命名空间 ( name space )类似文件系统,每一个节点都是通过路径来表示的,不同的是,节点可以包含一定的数据(2MB 字节),这些节点可以用来存放业务信息,节点还包含更新的版本、时间戳。
节点类型:临时节点,创建节点的会话存在,节点就存在, 一旦会话结束,如客户端创建的连接断掉,或者客户端主动关 闭此会话,则节点会被删除 。 还可以指定节点为顺序节点,创建节点的时候,自动为节点增加一个序列号,并且序列号递增 。
节点可以被监控, 一旦节点变化,如删除节点,或者节点数据变化,客户端就会收到此事件,此监控失效 。 客户端可以调用 API 继续监控这个节点 。
心跳包通常用于长连接 , 如果长连接没有心跳包,会导致服务器或者防火墙主动断开 。 心跳包通常就是内容为空的包 。
命令:
create -e,创建临时节点;
create -s,创建带有序列号的节点;
get 操作返回节点内部使用的数据:
- cZxid,节点创建时的 zxid;
- mZxid ,节点最新一 次更新发生时的 zxid;
- ctime,节点创建时的时间戳;
- mtime ,节点最新一 次更新发生时的 时间戳;
- dataVersion , 节点数据的更新次数;
- cversion , 其子节点的更新次数;
- aclVersion , 节点 ACL (授权信息) 的更新次数;
- ephemeralOwner,如果该节点为临时节点, ephemeralOwner值表示与该节点绑定的会话 ID,如果该节点不是临时节点, ephemeralOwner值为 0;
- dataLength , 节点数据的字节数;
- numChildren,子节点个数 。
watch 操作 , ls 命令和 get 命令都可以增加一个 watch 操作, 节点变化的时候会通知客户端。通知完毕后,还需要再次调用 ls 或者 get 才能监昕此节点变化。
选举领导者以及候选过程
每个候选者使用 zk 创建一个节点的时候,都会知道自己创建的节点名,在选举过程中,用自己的节点名同/election 目录下所有节点进行比较,如果自己的序列号就是最小的序列号,那自己就是当仁不让的领导者节点 。
其他节点同时还需要 watch 领导节点,即序列号最小的节点,如果领导节点被删除/退出或者意外岩机,则所有候选者都会收到消息,再次进行如上所述的选举过程 。
这种选举过程比较简单,唯一的问题是如果有大量候选者,节点变化同时通知其他大量的候选者再次进行选举会对 zk 有一定的性能影响,因此,一般改进的方式是每个候选者仅监听比自己序列号小的那个候选者。这样,如果领导节点被删除,则序列号较大的候选者能收到领导节点变化事件,只有这一个节点完成选举过程,确认自己是领导节点。
分布式锁
实现分布式锁可以利用节点唯一性,比如创建一个/locks/xxx 的节点,xxx可以对应到业务逻辑的合同号等。如果创建节点成功,则认为自己获得锁,可以进行业务操作,如果创建失败,则监听此节点,等待节点被删除。
业务操作完毕后,可以删除此节点 。 这时候其他客户端将得到 watch 事件,再次创建/locks/xxx ,成功则意味着再次获得这个锁。
缺点:
- 同领导选举一样,一旦节点被删除 ,则会广播监听事件,并且所有候选者都会争相创建节点,性能较差。
- 不能随时查看有多少客户端在等待这个锁,以及到底是哪个客户端获取到这个锁。
故而,更好的方式:
类似领导选举那样的算法来实现分布式锁,谁是领导节点,谁就相当于获得锁。 释放锁,将自己创建的节点删除就可以;需要查看有多少客户端在等待锁,只需要查看有多少节点就可以 。
服务注册和服务发现
通过 zk 可以实现服务注册和服务发现。
Curator
Curator 实现 ZooKeeper 提供的所有应用场景(除了两阶段提交〉,有以下实现:
- 领导节点选取;
- 分布式锁;
- 分布式读写锁;
- 共享信号量;
- 栅栏和双重 Double Barrier;
- 分布式计数器,支持 integer 和 long;
- 分布式队列和分布式优先级队列;
- 服务注册和发现。
RetryPolicy接口用于重连策略,实现类有以下:
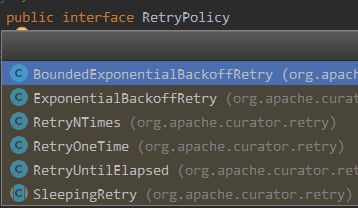
Curator API 是链式调用风格,遇到 forPath 接口就触发 ZooKeeper 调用,delete删除节点,以 forPath 结尾,如果节点不存在,将抛出 NoNodeException,如果节点是非空节点,则抛出 NotEmptyException。
Curator 提供 InterProcessMutex 来实现分布式锁,用 acquire 方法获取锁,以及用 release释放锁。
Curator 提供一个服务注册与发现的封装库curator-x-discovery。通过 ServicelnstanceBuilder 构造一个服务描述,以及通过 ServiceDiscovery 注册服务,还允许设置 payload,可以是任何类,用来放置额外的信息,也可以采用自定义类。
第十七章 监控 spring boot 应用
能查看和监控以下信息 :
- Spring Boot 的配置信息;
- Spring Boot 配置的 Bean 信息;
- 最近请求的 HTTP 信息;
- 数据源,NoSQL 等数据状态;
- 在线查看日志内容,在线日志配置修改;
- 所有@RequestMapping 注解的 URL 路径;
- 自动装配信息汇总;
- 打印虚拟机的线程栈;
- Dump 内存;
- 应用的各种指标、汇总;
- 自定义监控指标。
trace 是通过 InMemoryTraceRepository 类来实现的,默认保留最后 100 条访问数据,可以自己配置InMemoryTraceRepository 或者实现 TraceRepository 接口,可以修改保留数据的条数。
Actuator 允许查看日志配置 ,还允许修改日志等级配置, Actuator 也可以在线查看日志内容 。
http://localhost:8081/application/loggers
可以通过提交以下 POST 片段来动态改变日志等级。
http://127.0.0.1:8081/application/dump 获得线程的堆栈信息
http://127.0.0.1:8081/application/dump 获得内存镜像信息,内存镜像通常是查看内存溢出最好的办法,获得内存镜像更通用的方法是使用 JDK 提供的 jmap 命令,还可以在 Spring Boot 应用启动的时候增加如下参数:
XX:+HeapDumpOnOutOfMemoryError XX:HeapDumpPath=/xxx/file.hprof
jhat 来读取内存镜像文件 , 井通过 OQL 对象查询语言来分析内存。
参数-port 指示 jhat 的访问地址,可以通过浏览器访 问 该地址, 进入内存分析界面。
OQL语句示例:
select s from java.util.ArrayList s where s.size >= 400
其他endpoint:
configprops : 所有@ConfigurationProperties 注解的配置信息,如文件上传的最大允许配置等。
Healthlndicator 接口实现监控信息显示,默认有如下类实现 Healthlndicator 接口:
DiskSpaceHealthlndicator
DataSourceHealthlndicator
XXXHealthlndicator: Elasticsearch 、几恒、 Mail 、 MongoDB 、 Rabbit 、 Redis 、Solr。
自定义监控指标,实现接口Healthlndicator,重写方法health,返回一个 Health 对象。