Faster R-CNN的好文
编程实现http://www.sohu.com/a/215920394_71721
自己实现faster rcnnhttp://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
---------------------------------------------------
(ROI pooling)一文读懂Faster R-CNN https://zhuanlan.zhihu.com/p/31426458
(ROIpooling)ROIALigned https://blog.csdn.net/u011918382/article/details/79455407
决定直接把知乎链接贴过来不贴文章了。。这篇是我看到的讲解比较到位的,比起别人还解析了代码
【详述目标检测最常用的三个模型:Faster R-CNN、SSD和YOLO】里面有三个检测网络的性能比较https://blog.csdn.net/weixin_42273095/article/details/81699352
https://zhuanlan.zhihu.com/p/39579528【这个也有性能比较】
【详解RPN网络,bounding box regression里面有个链接可以理解下】
(里面的某个链接bounding box regression)https://blog.csdn.net/qq_36269513/article/details/80421990
--------------------------------------------------
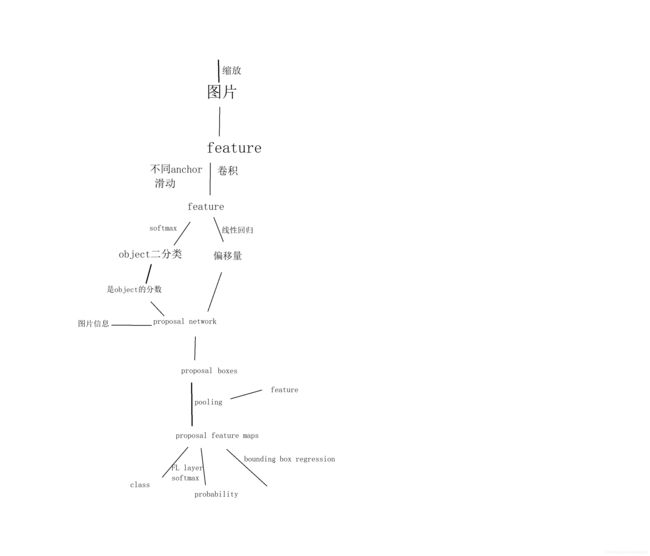
这个是自己画的,总体Faster RCNN流程图
========================================================代码部分=
代码解析https://blog.csdn.net/u012457308/article/details/79566195
主要是网络结构的代码
----------------------------------
代码中imbd与roidb的解释好文:https://blog.csdn.net/sloanqin/article/details/51537713
很详细甚至啰嗦的代码解读:https://blog.csdn.net/qq_41576083/article/details/82966489
imdb就是数据集信息即数据集类的一个实例,这个数据集类含有图片的名字,位置,类别,图片后缀名等
roidb是一个字典列表,字典里是每个数据的信息比如bbox,gt_overlaps,gt_classes,flipped(是否由fipped得来)
================================================
记录自己关于faster rcnn的问题
Q:RPN的判断全景后景,分配RPN标签的时候,为什么不分配负标签(background)给IOU为0的anchor?
A:RPN的判断前景后景,即一个两类的分类,分配标签为了担保正负样本均衡,不能背景全标负,而应该是实验发现负样本标给IOU<.3的效果比标给后景的效果好
==============================================
MAP。。这个要把自己搞晕了
mAP(Mean Average Precision)是什么意思呢,目标分类中多个类,每个类的AP加起来的平均就是mAP了
所以什么是AP呢?AP可以说就是PR曲线的面积(也不全是),PR曲线(Precision Recall)怎么画呢?
有两种方法,一种方法是VOC2010前用的,后来有一种取代了前面的。
第一种:2010年前的,选0.0,0.1,0.2.。。1.0,这十一个值,找recall=这些值的时候Precision的最大值(等等,Precision和recall怎么算,后面再说)
if use_07_metric:
ap = 0.
# 2010年以前按recall等间隔取11个不同点处的精度值做平均(0., 0.1, 0.2, …, 0.9, 1.0)
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
# 取最大值等价于2010以后先计算包络线的操作,保证precise非减
p = np.max(prec[rec >= t])#prec所有符合在recall值大于t条件的值就是prec[rec>=t],(百度下numpy 的where),加上个最大值。就是所谓的“在recall等于0.1到1.0这11个值的时候precision最大值”
ap = ap + p / 11.
在VOC2010及以后,需要针对每一个不同的Recall值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值。
PR怎么计算:这个回答里面的MAP计算示例里看,原来是每个样本对应一个Precision和Recall值
问题结束,说说为啥这个把我绕晕了,我调整IOU的阈值,得到不同的Precision和Recall,还以为这个PR是最终结果的PR,还以为这个是PR图,还以为PR图是不同IOU对应的PR值的积分,结果得到一个这样的图;实际的阈值是:对于某类下全部的真实目标,将IOU>=0.5 的作为检测出来的目标,取不同的confidence 阈值计算对应的precision 和recall,对于每个recall,取其对应的最大precision,对这些precision 求平均即为该类的AP 值。所有类的AP 值求平均即为mAP,不知道这种说法和上面的计算是否等价。。
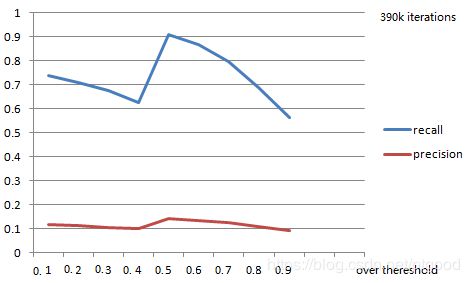 recall和precision不是真的,应该是采样中排行最大/最小的
recall和precision不是真的,应该是采样中排行最大/最小的
thereshold设为0.5的时候MAP最高,估计是网络是在IOU>0.5为标准的时候训练的
| map | ovtheres |
| 0.6692 | 0.1 |
| 0.6413 | 0.2 |
| 0.6059 | 0.3 |
| 0.5596 | 0.4 |
| 0.8473 | 0.5 |
| 0.7989 | 0.6 |
| 0.7156 | 0.7 |
| 0.5982 | 0.8 |
| 0.4968 | 0.9 |
MAP和AUC的含义与对比。。对比在最后一句
====================================================
Q:anchor与RPN的3x3conv之前的feature map对应关系?
A:feature map里的一个点对应resize后原图的proposal区域的中心点,换句话来说:其实featuremap对于anchorbox的生成的贡献就是提供了一个中心点而已(quote from here)
RPN中这两个层的具体过程: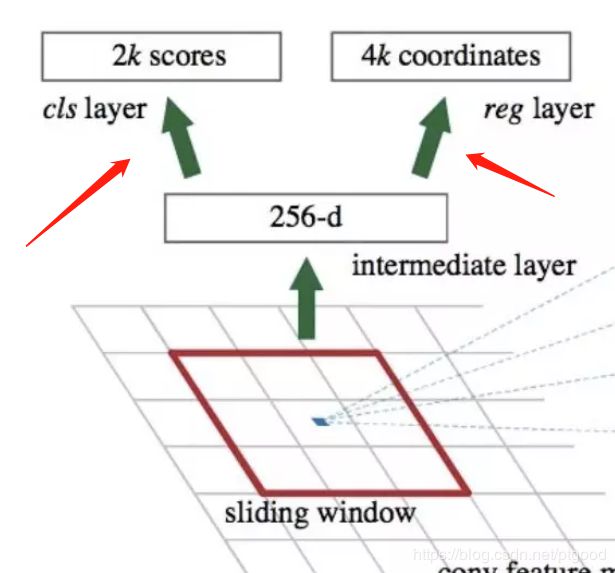
可以把过程看成这样:
wxhx256d的feature map(为什么是256dim?)----滑窗-->3x3x256d--3x3x256x256conv-->1x1x256,再分两路:
1.classification:经过1x1x256dimx18conv,生成9个anchor所对应的是否是前景的probability
2.Regression:经过1x1x256x36的卷积核,得到1x1x36的特征向量,分别代表9个proposals的(长宽及中心点坐标)。
Q:为什么k个anchor box的值未加入卷积计算
A:regression中的dw,dh等的监督标签是每个proposal的值与它分配到的gt框的差值,,每个regression的卷积代表一个形状anchor的结果,所以训练的时候也会对他们进行监督,bp