编译原理归纳学习——去除晦涩
小崔考点记录:
1、编译程序总框图 前端 后端
2、文法产生句型 推导 文法四种形式 会写简单文法(三型、二型)
3、正规式->NFA->DFA(不要忘记化简DFA)
4、5、语法分析:自上而下->递归、预测分析、LL(1):消除左递归、消除回溯、FIRST、FOLLOW、预测分析表
自下而上->句柄概念 LR方法: LR(0),LR(1),SLR(1),LALR,二义文法
6、S属性文法,L属性文法 概念
7、什么是中间代码?哪几种?优缺点
语法制导翻译成中间代码(独立的四元式表,语法分析过程的描述,遗留问题存于nextlist?)
8、活动记录 参数传递
优化:局部、循环、全局
DAG算法(局部优化)
无用赋值
从右向左运算效率高 注意活跃信息
目标代码的生成:目标代码生成算法 待用信息 活跃信息 地址描述 寄存器信息 块与块之间(寄存器不能传值)
编译程序总框图:

NFA
1. (a|b)*ab的NFA


3.

DFA
1. (a|b)*ab的DFA ?

NFA到DFA的变换
从NFA构造等价的DFA的一般思想是让新构造的DFA的每个状态代表NFA的一个状态集,这个DFA用它的状态去记住该NFA在读入符号后能到达的所有状态。
1、
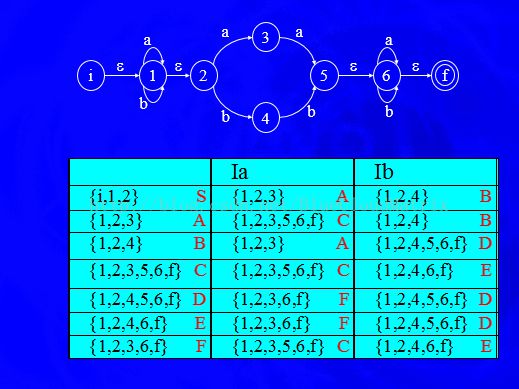

2、一篇很详细讲解NFA如何转化DFA的CSDN博客:http://blog.csdn.net/lovesummerforever/article/details/9060887
3、[例子] 构造下列正规式相应的最简DFA。
(a|b)*a(a|b)
解:(1)由正规式到NFA

(2)
| a | b | |
| {0} | {0,1} | {0} |
| {0,1} | {0,1,2} | {0,2} |
| {0,1,2} | {0,1,2} | {0,2} |
| {0,2} | {0,1} | {0} |
生成此表的方法:初始为{0},因为0和1之间就需要a了。{0}和a结合能到达0和1,所以在<{0}, a>处填{0, 1},同理,对于{0, 1, 2}和a结合(0,1,2分别和a结合)能到达0,1,2,所以在<{0,1,2}, a>处填{0,1,2},而{0, 1, 2}和b结合,0与b结合到达0,1与b结合到达2,2与b结合到达空,所以在<{0,1,2}, b>处填{0,2}。
(3)

(4)DFA最小化
初始划分:{0,1}(非终态) {2,3}(终态)
因为{0,1}a = {1,2}不属于上面任意一个子集,所以分开:{0},{1}
因为{2,3}a = {1,2}不属于上面任意一个子集,所以分开:{2},{3}
所以已经是最简
写一个文法 ,使其语言是奇数集,且每个奇数不以0开头。
解:文法G(N):
N→AB|B
A→AC|D
B→1|3|5|7|9
D→B|2|4|6|8
C→0|D
First集合的求法:
First集合最终是对产生式右部的字符串而言的,但其关键是求出非终结符的First集合,由于终结符的First集合就是它自己,所以求出非终结符的First集合后,就可很直观地得到每个字符串的First集合。
1. 直接收取:对形如U-a„的产生式(其中a是终结符),把a收入到First(U)中。
2. 反复传送:对形入U-P„的产生式(其中P是非终结符),应把First(P)中的全部内容传送到First(U)中。
3. 见下面给出的例1。
Follow集合的求法:
Follow集合是针对非终结符而言的,Follow(U)所表达的是句型中非终结符U所有可能的后随终结符号的集合,特别地,“#”是识别符号的后随符。
1. 直接收取:注意产生式右部的每一个形如“„Ua„”的组合,把a直接收入到Follow(U)中。
2. 直接收取:对形如“„UP„”(P是非终结符)的组合,把First(P)除ε直接收入到Follow(U)中。
3. 反复传送:对形如P-„U的产生式(其中U是非终结符),应把Follow(P)中的全部内容传送到Follow(U)中。(或 P-„UB且First(B)包含ε,则把First(B)除ε直接收入到Follow(U)中,并把Follow(P)中的全部内容传送到Follow(U)中)
例1:判断该文法是不是LL(1)文法,说明理由 S→ABc A→a|ε B→b|ε?
First集合求法就是:能由非终结符号推出的所有的开头符号或可能的ε,但要求这个开头符号是终结符号。如此题A可以推导出a和ε,所以FIRST(A)={a,ε};同理FIRST(B)={b,ε};S可以推导出aBc,还可以推导出bc,还可以推导出c,所以FIRST(S)={a,b,c}。
Follow集合的求法是:紧跟随其后面的终结符号或#。但文法的识别符号包含#,在求的时候还要考虑到ε。具体做法是把所有包含你要求的符号的产生式都找出来,再看哪个有用。 Follow(S)={#} 如求A的,产生式:S→ABc A→a|ε ,但只有S→ABc 有用。跟随在A后年的终结符号是FIRST(B)={b,ε},当FIRST(B)的元素为ε时,跟随在A后的符号就是c,所以 Follow(A)={b,c} 同理Follow(B)={c}
消除左递归的例子:



提取公共左因子:

LL(1)文法:
一个文法满足下列条件:
(1)文法不含左递归
(2)对于文法中的每一个非终结符A的各个产生式的候选首符集两两不相交
(3)对于文法中的每个非终结符A,若它存在某个候选首符集包含ε,则
![]()
我们称这样的文法为LL(1)文法。

LL(1)文法预测分析法:
文法(4 1)'
1 E→TE′
2 E′→ATE′|ε
3 T→FT′
4 T′→MFT′|ε
5 F→(E)|i
6 A→+|-
7 M→*|/
再考虑文法(4 1)′,首先分别求出各个FIRST集和FOLLOW集如表41所示,再构造相应的LL(1)分析表如表42所示。现以输入符号串i+i*i为例,列出识别此符号串的过程如表43所示。
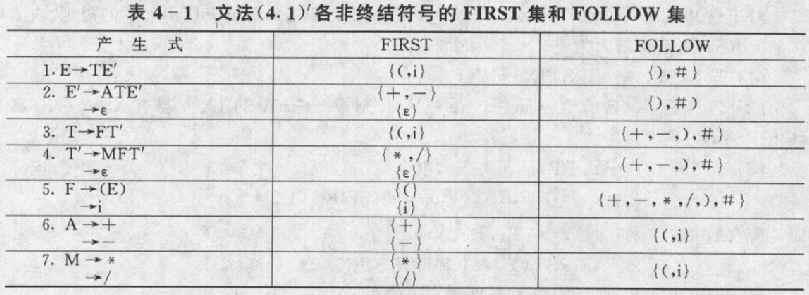


上面的算法对应课本上的晦涩讲解为:
(1) 若a∈FIRST(γi),则置M[A,a]=“A→γi”;
(2) 若ε∈FIRST(γj),且a∈FOLLOW(A),则置M[A,a]=“A→γj”;
(3) 除上述两种情况外,其余的一切表元素均置为“出错”。
注:M为LL(1)分析表
再来一个例子加深印象:
文法:
预测分析法,预测分析表) - 小镜子~ - 菜园子")
各个非终结符的first集合:
预测分析法,预测分析表) - 小镜子~ - 菜园子")
关于follow集合我们只要考虑有可能变成空转换的非终结符:
预测分析法,预测分析表) - 小镜子~ - 菜园子")
根据FIRST集和FOLLOW集可以生成一张LL(1)文法的预测分析表:
预测分析法,预测分析表) - 小镜子~ - 菜园子")
预测分析表法的分析过程:
要以表格的形式,列出分析栈的变化,输入,和输出动作:
以下是上面的文法对于id+id*id串的分析过程
预测分析法,预测分析表) - 小镜子~ - 菜园子")
(注:比如上表的第5行,T'本来可以表示成两种之一,但因为此时输入最左端是+,根据分析表T'应该取ε)
LR(0) LR(1) SLR(1) LALR(1):
一个通俗易懂的课件:http://wenku.baidu.com/view/a36388360b4c2e3f57276379.html
句柄:
先画出语法树,例:
S/ | \
( T )
/ | \
T d S
/ | \ |
T d S b
| /|\
S ( T )
短语就是树或者子树的叶子:S,(T),b,Sd(T),Sd(T)db,(Sd(T)db)
直接短语就是只有叶子的子树的叶子:S,(T),b
最左边的直接短语就是句柄:S

DAG图:

[例]试对以下基本块B1应用DAG进行优化。
B1: A:=B*C
D:=B/C
E:=A+D
F:=E*2
G:=B*C
H:=G*G
F:=H*G
L:=F
M:=L
并就以下两种情况分别写出优化后的四元式序列:
(1)假设G、L、M在基本块后面背引用;
(2)假设只有L在基本块后被引用。
解:对于B1其DAG图:

(1)若只有G、L、M在基本块后被引用,则优化为:
G :=B*C
H := G*G
L := H*G
M := L
(2) 若只有L在基本块后被引用,则优化为:
G:= B*C
H :=G*G
L := H*G
[例]
T1 := A+B
T2 := A- B
F := T1 * T2
T1 := A- B
T2 := A – C
T3 := B - C
T1 := T1 * T2
G := T1 * T3

(注意T1和T2的位置变化)
三地址:
表达式x+y*z的三地址代码为:
t1:=y*z
t2:=x+t1
其中t1和t2是编译时需要的临时变量
三地址代码是语法树或dag的一种线性表示
a:= (-b + c*d ) + c*d
语法树的代码 dag的代码
t1:= -b t1 := -b
t2:= c*d t2:= c*d
t3:= t1+ t2 t3:= t1+ t2
t4:= c*d t4:= t3 + t2
t5:= t3 + t4 a:= t4
a:= t5



[题]把语句
if X>0 ∨ Y<0
then while X>0 do X:=A*3
else Y:=B+3;
翻译成四元式序列。
(1) (j>, X, 0, (5))
(2) (j, _, _, (3))
(3) (j<, Y, 0, (5))
(4) (j, _, _, (11))
(5) (j>0, X, 0, (7))
(6) (j, _, _, (10)) ?
(7) (*, A, 3, T1)
(8) (:=, T1, _, X)
(9) (j, _, _, (5))
(10) (j, _, _, (13)) ?
(11) (+, B, 3, T2)
(12) (:=, T2, _, Y)
(13) ?
间接三元式
三元式,四元式的运算次序即为其代码表中语句的次序,在三元式代码表的基础上另设一张表,按运算次序列出相应三元式在三元式表的位置,这张表称为间接码表。因此三元式表只记录不同的三元式语句,而间接码表则表示由这些语句组成的运算次序
逆波兰:
也称后缀表达式,用它可以很轻松的计算表达式,对于开发一个简易的计算器是很重要的方法,给出表达式,转换为中缀表达式,再转换为逆波兰,再通过栈操作:
如果当前字符为变量或者为数字,则压栈,如果是运算符,则将栈顶两个元素弹出作相应运算,结果再入栈,最后当表达式扫描完后,栈里的就是结果。

三地址总结:
活动记录:
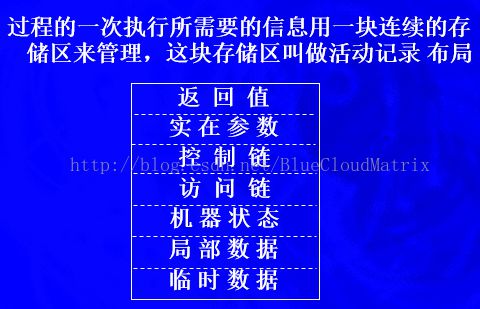
参数传递:?
值调用