关于数据架构岗的面试准备 v1.0
场景
又到了一年一度的跳槽旺季,是时候小涨一波工资了。
考虑到最近各大公司频繁爆出裁员的消息,因此,有必要好好复习与准备一下常见的面试题,做到心中有谱。
答题策略
一. 禁止瞎说
知之为知之,不知为不知,态度要真诚。
二. 核心原理与应用场景
所有问题尽量按如下两个方向靠拢 :
- 原 理 : 是什么
- 应用场景:在实际项目中的应用;在经典分布式开源框架 eg. spark、hdfs 与 spring cloud eureka 中的应用
技能点
一. 数据结构与算法篇
1】LinkedList与ArrayList的区别
答:1)原理:计算机中数据常用的存储方式有四种 : 顺序存储、链式存储、索引存储与散列存储。顺序存储的特点:逻辑上相邻的元素在物理位置上也相邻、适合随机读取多,删除与插入少的场景;链式存储的特点:不要求逻辑上相邻的元素在物理位置上也相邻、适合插入与更新操作比较频繁的场景。
2) 顺序表与链表在 java 语言中的一个经典实现就是ArrayList 与 LinkedList 。
LinkedList 是一个双向链表,这就意味着: a. 在往指定位置插入元素时,相对单向链表可以提升性能?判断 index 离头部还是尾部近,离头部近,则从头部开始遍历,找到待插入位置;b. LinkedList 天然可以用作栈或者队列。
ArrayList 内部基于数组实现,一般在时候的时候,最好能初步估计待放入集中的个数,给它一个初始值,避免插入元素的时候,出现频繁扩容,影响性能。
2】Stack与ArrayBlockQueue&ConcurrentLinkedQueue的应用
答:1)在项目开发中的应用 :
2 ) spark与spring cloud eureka 源码中的应用 :
答:
3】HashMap、LinkedHashMap与ConcurrentHashMap数据结构与性能优化亮点分析
答:A. 基本的数据结构与存储结构。
数据结构:
class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
}
class TreeNode extends LinkedHashMap.Entry {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev;
boolean red;
}
存储结构:数组 + 链表 + 红黑树。当存储元素时发生hash冲突,首先会将冲突的元素挂到链表上 - 这样有一个新的问题,链表的查询时间复杂度为O(n), 如果有大量的元素发生冲突的话,势必严重影响查询性能:因此,当链表长度大于8时,先转双向链表,再转为红黑树存储(O(logn)),提升查询性能。
B. hash寻址方式。
(h = key.hashCode()) ^ (h >>> 16)
为了降低hash冲突的概率,同时提升寻址效率,寻址不是简单的根据key获取hash值,然后对数组长度取余,而是:
1) 将 key 的hash值的高、低16位进行一个异或运算(这样在低 16 位里面,可以同时保留高、低16位的特征),得到 hash 值。
2) (n - 1) & hash : 用hash值与数组长度-1进行与运算,得到存储位置 - 这样做比 取模运算性能高 - 同时,只要后面数据扩容是以 2 的 n 倍来进行,就可以达到与取模一样的效果。
C. 数据元素扩容。
当元素个数达到 initiCap*0.75 = 12 个时,就会扩容,一次扩大一倍;扩容后,元素的位置要不变,要不后移 oldCap(默认16)位。
手写基本的排序算法
/**
* 冒泡排序
* 基本实现:n个元素,进行 n-1 趟排序;每趟对比次数:n-i,i = 1,2,...
* 优化点: 1) 一趟排序后,如何元素没有发生调换,则排序结束 2)
* 2) 记录发生交互的元素下标,该下标后的元素,下一趟迭代,无需对比
*
* @author PENGYC
*
*/
public class BasicSortAlg
{
public static void main(String[] args)
{
int[] arrays = new int[] {110,0,2,5,7,8,2,3,1};
// bubleSort2(arrays);
QuickSort.quickSort(arrays, 0, arrays.length -1);
Arrays.stream(arrays).forEach(System.out::println);
}
/**
* 冒泡排序
* @author PENGYC
*
*/
static class BubleSort
{
public static void bubleSort(int[] arrays)
{
int temp;
for(int i = 0; i< arrays.length; i++)
{
boolean exchangedFlag = false;
for(int j = 0; j< arrays.length -1 - i; j++)
{
if(arrays[j] > arrays[j+1])
{
temp = arrays[j];
arrays[j] = arrays[j + 1];
arrays[j + 1] = temp;
exchangedFlag = true;
}
}
if(!exchangedFlag)
{
break;
}
}
}
public static void bubleSort2(int[] arrays)
{
int temp;
int sortBorder = arrays.length - 1;
int lastChangeIndex = 0;
for(int i = 0; i< arrays.length; i++)
{
boolean exchangedFlag = false; // 一趟排序如果没有元素发生交换,则排序结束
for(int j = 0; j< sortBorder; j++)
{
if(arrays[j] > arrays[j+1])
{
temp = arrays[j];
arrays[j] = arrays[j + 1];
arrays[j + 1] = temp;
exchangedFlag = true;
lastChangeIndex = j; // 记录发生交换的位置,后面得元素为有序区,下一趟排序无需比较
}
}
if(!exchangedFlag)
{
break;
}
sortBorder = lastChangeIndex;
}
}
}
/**
* 快排
* @author PENGYC
*
*/
static class QuickSort
{
public static void quickSort(int[] arr, int startIndex, int endIndex)
{
if(startIndex >= endIndex)
{
return;
}
int pivotIndex = partition(arr, startIndex, endIndex);
quickSort(arr, startIndex, pivotIndex -1);
quickSort(arr, pivotIndex +1, endIndex);
}
public static int partition(int[] arr, int startIndex, int endIndex)
{
int left = startIndex, right = endIndex;
int pivot = arr[startIndex];
while(left != right)
{
while(leftpivot)
{
right--;
}
while(left 二. 核心基础篇 : JVM&HTTP&TCP&并发&网络IO
并发
synchronize 关键字:1. 一种重量级的线程同步实现方式,通过对象关联的monitor的计数器来实现,计数器初始值是 0 : 各个线程来尝试加锁的时候,只有那个读取到计数器值为 0 的线程能加锁成功,其他的线程加锁失败,放到阻塞队列里。2. 对应到两条 jvm 指令:moniterenter & moniterexit。
volatile 关键字:1. 解决什么问题?多个线程并发读写一个共享变量的时候,有可能某个线程修改了变量的值,但是其他线程看不到。这个是由 java的内存模型所决定的:为了提高执行性能,每个线程都有自己的工作内存(类似于本地的高速缓存),同时还有一个共享的主内存。问题来了,线程修改自己本地工作内存中的变量副本的值后,不会马上刷新到主内存中 - 这就导致其他线程看不到变量的最新的值,同步问题诞生了。 2. 解决办法?加 volatile 关键字,底层基于 MESI 协议,保证 A. 一个线程修改变量的值后,马上写回主内存 B. 其他线程工作内存中的变量缓存值失效。
CAS 机制
- 是什么?CAS即CompareAndSet 先比较再设置的意思,底层基于Unsafe类来实现的一种细粒度的或者说是无锁化的同步机制;
- 有什么用? 像常用的一些并发类: Atomic 相关、AQS组件,都是基于 CAS机制来实现的。以AtomicInteger类执行i++操作,来简单介绍一下CAS实现大致思路:简单来说,就是搞一个 state 变量,初始值为0。各个线程并发来修改 i 的值时,先读取 state的初始值0 ,然后执行一个原子的CAS操作,比较此时state的值是不是0,是 0 的话,那个幸运线程修改 i 值成功,CAS操作成功;其他的线程CAS操作失败,自旋、重复读取判断。
- 存在的问题?ABA问题,自旋问题。解决方式:LongAdder类。
AQS 组件 :AbstractQueuedSynchronizer 抽象队列同步器,就是一个并发包的基础组件,用来实现各种锁,各种同步组件的,比如说 ReentrantLock、ReentrantReadWriteLock都是依赖它来实现的。AQS主要的数据结构是一个双向链表实现的队列、标识同步状态的state变量,初始值为 0、标识当前加锁线程的 exclusiveOwnerThread 变量。
三. 设计模式篇
通过三个很常用的有意思的设计模式,介绍设计模式在项目实际开发、源码设计与系统架构层面的应用:
1】项目开发应用 之 代理模式 & 策略模式
一个稍稍复杂一点的系统,往往涉及到第三方系统调用,比方说我们调用推送平台的推送服务、短信服务以及IP地址服务等。这就是一个很典型的代理模式使用场景,搞一个代理类,实现与外部服务一样的接口,我们自己的系统针对代理类来操作,代理类代理对外部接口的访问 :
public interface Subject
{
void request();
}
/**
* 目标类
* @author PENGYC
*
*/
public class ConcreteSubject implements Subject
{
public void request()
{
System.out.println("执行功能");
}
}
/**
* 代理类与目标类实现一样的接口
* @author PENGYC
*
*/
public class Proxy implements Subject
{
private Subject subject;
public Proxy(Subject subject)
{
this.subject = subject;
}
public void request()
{
subject.request();// 可在前后加打印日志等功能增强
}
}
策略模式在项目中肯定会用,主要用来封装不同的算法实现,替代大段的 if-else逻辑,这个已经写进了阿里的编码规范,基本上在做Code review的时候,一看到多个大段的if-else语句,就可以将其用策略模式改造一下,提升代码的可读性与可扩展性。
2】spark源码中的应用之 访问者模式 & 构造器模式
构造器模式:主要用来构造复杂的对象,一般会以链式的形式出现,方便使用者调用。
spark 的 dataset 与 dataFrame 编程入口类 SparkSession 的构造就是一个经典的构造器模式应用场景 :
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.master("local[2]")
.appName("Spark SQL data sources example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
spark.stop()
}
1.SparkSession 本身的构建涉及到 SparkContext与SparkConf等复杂对象的构造
2.通过使用构造器模式,SparkSession 对象本身代码的可读性与易用性大大增强。
访问者模式 : 主要用于树形结构,对象只在 accept 方法里统一接收各种访问操作,做到将对象的结构与操作分离,提高树形结构访问的灵活性与可扩展性。
SQL-ON-Hadoop类大数据引擎的SQL编译器,一般是基于第三方的语法生成工具来编写的,像 spark sql 的编译器就是基于 ANTLR 4来编写的:这个语法工具可以很方便的把我们自定义的sql语法,通过词法分析、语法解释自动构建一颗语法分析树,并且自动生成基于访问者模式的树遍历器,用户只需要在具体的遍历器中实现相关的访问逻辑,即可完成 sql 逻辑的实现,非常灵活与方便。
3】系统设计层面的应用之 备忘录模式
备忘录模式 :说白了,就是一个类产生了一些中间数据,这些中间数据需要在一个地方保存起来,以给后面不同的操作使用这些数据。
系统业务日志与推送消息入库场景:一方面,我们的推送消息、业务日志等非业务信息也需要入库,方便后续数据分析用;另一方便,为了缩短响应时间,提升用户体验,一个非业务操作对应的业务日志:
A. 对于单机版的系统而言,我们一般不是直接在业务操作完了以后,马上就将日志写入数据库,而是先异步写入一个阻塞队列中。当队列中的日志达到一定量后,再批量入库 - 同时,当队列满了,我们需要将中间日志数据持久化到一个备忘录,比方说:mysql 中,队列空的时候,搞一个线程,再从备忘录中恢复数据到队列中来。
B. 当然,对于分布式系统而言,一般用 消息中间件,比方说 kafka ,而不是内存队列 - 但情况类似,当 kafka 集群宕机了,我们需要将 日志 持久化到 mysql 中保存,kafka起来后,再从 mysql中恢复。
代码片段 :
private ArrayBlockingQueue queue =
new ArrayBlockingQueue(QUEUE_MAX_SIZE);
/**
* 将一个消息放入队列
* @param message 消息
* @throws Exception
*/
public void put(Message message) throws Exception {
if(offlineStorageManager.getOffline()) {
offlineStorageManager.store(message);
if(queue.size() == 0) { // 队列为空,则启一个线程从备忘录中恢复数据到队列中来。
new OfflineResumeThread(offlineStorageManager, this).start();
}
return;
}
// 如果内存队列已经满了,此时就触发离线存储 : 将消息保存到备忘录中
if(QUEUE_MAX_SIZE.equals(queue.size())) {
offlineStorageManager.store(message);
offlineStorageManager.setOffline(true);
return;
}
queue.put(message);
}
四. Spark内核分析与性能调优篇
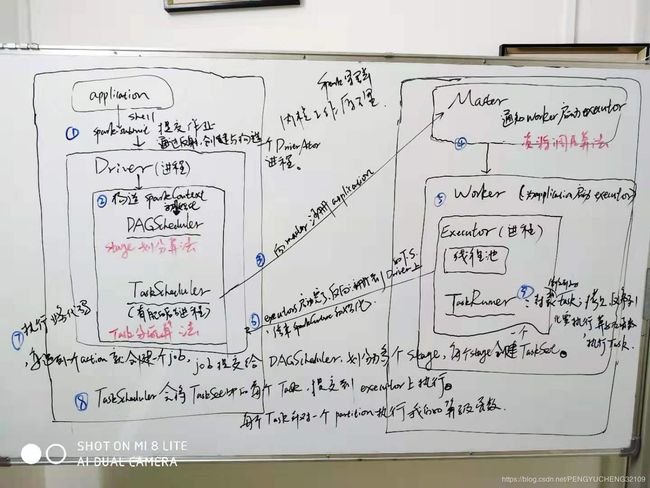
资源调度算法
场景:假设用户通过spark-submit提交了一个作业,相关参数如下:
/usr/local/spark/bin/spark-submit \
--class cn.spark.sparktest.core.WordCountCluster \
--num-executors 5
--driver-memory 100m
--executor-memory 1000m
--executor-cores 2
/usr/local/SparkTest-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
即应用程序申请 52 个cores,101G的内存;现在假设集群共有 5 个 worker可用;每个worker有 3 个core可用,内存充足。
问题:master会如何为作业分配资源? 每个worker分配几个core ?
/*** 资源调度算法:
* 1. driver的调度 : 即在某个资源充足的worker上,启动driver
* A.driver的调度只会发生在 yarn-cluster模式;对于client模式,会在本地启动driver,不涉及到多个driver的调度。
* B. 双重循环遍历 待调度的 drivers 与 可用的worker,找到合适的worker ,然后在其上启动 driver进程。
*
* 2. application 的调度 :
* A. 均匀分配:在 worker上尽可能的均分分配 cores;具体实现:
* 先得到按照可用cores倒排后的workers集合,然后依次遍历所有worker,并分配cores
* B. 如果一个worker上的资源已满足app应用运行需要,则只在这个worker上启动executor。
*/
private def schedule() {
if (state != RecoveryState.ALIVE) { return }
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
for (driver <- waitingDrivers.toList) { // 双重for循环,实现driver的调度
var launched = false
var numWorkersVisited = 0
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
launchDriver(worker, driver) // 在内存与逻辑cpu充足的worker上启动 driver
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
if (spreadOutApps) { // application 均匀调度机制 :在 worker上尽可能的均分分配 cores。
for (app <- waitingApps if app.coresLeft > 0) {
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(canUse(app, _)).sortBy(_.coresFree).reverse // 获取按照可用cpu数量排序后的workers
val numUsable = usableWorkers.length
val assigned = new Array[Int](numUsable) // Number of cores to give on each node
var toAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
var pos = 0
while (toAssign > 0) {
if (usableWorkers(pos).coresFree - assigned(pos) > 0) {
// assigned(pos) 代表第pos个worker上分配的cores数量
toAssign -= 1
assigned(pos) += 1
}
pos = (pos + 1) % numUsable
}
for (pos <- 0 until numUsable) {
if (assigned(pos) > 0) {
val exec = app.addExecutor(usableWorkers(pos), assigned(pos))
launchExecutor(usableWorkers(pos), exec) // 向workers发送启动executor请求
app.state = ApplicationState.RUNNING
}
}
}
} else { // 非均匀分配策略 : 如果一个worker上的资源已满足app应用需要,则只在这个worker上启动executor
for (worker <- workers if worker.coresFree > 0 && worker.state == WorkerState.ALIVE) {
for (app <- waitingApps if app.coresLeft > 0) {
if (canUse(app, worker)) {
val coresToUse = math.min(worker.coresFree, app.coresLeft)
if (coresToUse > 0) {
val exec = app.addExecutor(worker, coresToUse)
launchExecutor(worker, exec)
app.state = ApplicationState.RUNNING
}
}
}
}
}
}
Stage划分算法
- 封装最后一个 rdd,形成finalStage
- 对finalStage中的rdd的父子依赖关系进行判断:
a. 如果是窄依赖,则将父rdd的,压入栈中
b. 如果是宽依赖,则以父rdd为最后一个 rdd,生成新的 父stage - 父Stage中的rdd的父子依赖关系进行判断:
如果是窄依赖,则将父rdd的,压入栈中;宽依赖,则以父rdd为最后一个 rdd,生成新的 父stage
/**
* 1) 每一种shuffle操作eg.reducebykey 底层隐含对应三个rdd : MapPartitionsRDD
* 、ShuffleRDD、MapPartitionsRDD [后面两个是一个stage,第一个MapPRDD是上一个stage的最后一个rdd]
* 2) finalStage之前的所有stage,都是shuffle Map stage
* 3) param stage : finalStage = newStage(finalRDD, partitions.size, None, jobId, callSite)
*/
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id) // 生成父stage
if (missing == Nil) { // 提交没有父stage的第一个stage相关的任务
submitMissingTasks(stage, jobId.get)
// 一个partition生成一个task (有 ResultTask与ShuffleMapTask两种类型)
} else {
for (parent <- missing) {
submitStage(parent) // 递归提交与生成父stage
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id)
}
}
/**
* 借助于栈获取当前stage的父stage
* @param stage 当前stage
* @return 父stage集合
*/
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
if (getCacheLocs(rdd).contains(Nil)) {
for (dep <- rdd.dependencies) {
dep match { // 宽依赖,则生成新的 ShuffleMap Stage
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getShuffleMapStage(shufDep, stage.jobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
// 往栈中压入stage最后的一个rdd
waitingForVisit.push(stage.rdd)
while (!waitingForVisit.isEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
Task 分配算法
- 根据本地化优先级别高低依次分配 task
PROCESS_LOCAL : 最高的本地化级别,rdd 的partition与task,在同一个executor内。
NODE_LOCAL : 不在一个executor中,不在一个进程,但在一个worker节点
NO_PREF : 没有所谓的本地化
RACK_LOCAL : 机架本地化,rdd的partition与task在一个机架上
ANY : 任意的本地化级别
var launchedTask = false
for (taskSet <- sortedTaskSets; maxLocality <- taskSet.myLocalityLevels) {
do {
launchedTask = resourceOfferSingleTaskSet(
taskSet, maxLocality, shuffledOffers, availableCpus, tasks)
} while (launchedTask)
}
- 将分配好的task发送到executor上执行
executorData.executorActor ! LaunchTask(new SerializableBuffer(serializedTask))
五. Hdfs源码二次开发篇
六. 其他核心组件架构原理篇
kafka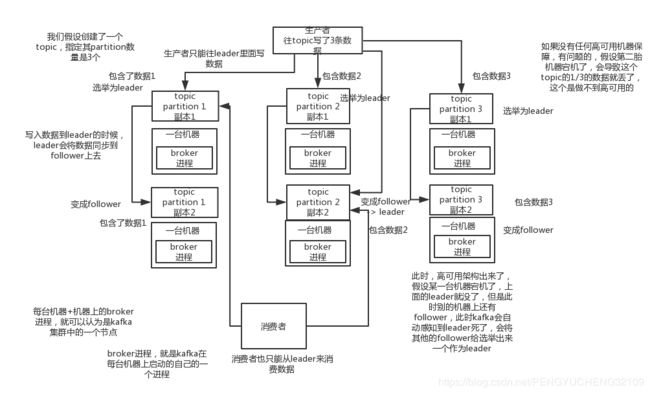
Hive
es

Zookeeper
Redis
七. 机器学习篇
梯度下降与最小二乘法的推导
逻辑回归、决策树与K-means聚类算法原理及在Spark ml与Sk-learn中的实现
评价指标
八. 重要项目简述
金融实时反欺诈
- 业务背景
你知道,做金融其实就是做风控,做风控就是做规则,做模型;我们公司风控这一块的工作,目前主要涉及到 C 端的消费金融,B端的产业链金融,以及全球资金运作三个方向;接下来,结合我主导交付的一个项目:消费金融-产融结合实时反欺诈,分享一下我们这边的消费金融风控建设现状以及我所做的一些主要的工作。有必要先稍稍提一下业务场景,其实很简单 :
1】用户在线下旗舰店够买我们美的的空调与洗衣机等家电的时候,可以关注我们的微信服务号-"美的分期"做分期付款,美的分期其实就是有点类似于京东白条。
2】关注美的分期微信服务号后,开始填写个人基本信息,包括身份证与银行卡信息等,完了,在相关页面上点击按钮,申请贷款。这个时候,在我们的美的分期业务系统后端,开始触发跑一系列的风控规则,用于鉴定这个用户是不是合法的、正常的购买家电所做的贷款申请。
我们的风控规则或者说是风控漏斗,主要有三个节点,最上面的是:
a.反欺诈过滤-反欺诈规则+反欺诈模型(目前没有做);中间的是
b. 授信过滤-授信评分卡+授信模型(已做) ;最下面的是
c. 人工审核。
项目架构介绍:我们消金实时反欺诈项目,就是基于js sdk、flume、kafka、spark streaming 、elasticsearch与hive等大数据技术,生成一堆反欺诈标签:登录注册黑名单、用户过去7天在旗舰店出现6次、用户申请贷款时与旗舰店距离小于1000米等标签。okay,先简单介绍到这里。 - 数据架构图
- 异常处理方案
自研实时计算平台 : M-StreamingIO
- 价值
- 数据架构图
- 下一步规划