Python与人工神经网络(3)——随机梯度下降算法
在介绍这个算法之前,先介绍一些必要的东西。
首先,我们说人工神经网络是让计算机从训练数据中学习,所以第一步就是数据了。我们用到的数据集的叫MNIST数据集,这是从NIST(National Institute of Standards and Technology)中选了两个相关的数据集,然后改良了下,形式如下:

训练数据集包括上图所示的一张张的小图片(28*28px)以及识别好了的结果。当然MNIST中也是包含测试数据的。测试数据和训练数据是不同人群的手写字体扫描图像,避免我们得到的神经网络只能识别特定的人群。
我们用x表示输入的训练样本,上期说过设计神经网络的时候简单粗暴,对于28*28的图像,输入神经元就是784个,每个输入值是对应像素的灰度值归一化后的结果(以后简称灰度值)。那么x就需要表示这784个值,所以x是一个784维的向量。输出值y=y(x),y是一个10维的向量,比如如果某个图片描述的是6,那么他预期的输出值就应该是y(x)=(0,0,0,0,0,0,1,0,0,0)T,T在这里表示转置矩阵。
为了训练出好的w和b,我们用一个函数C(w,b)来评估其效果,这个函数被叫做成本函数(cost function),其定义如下:
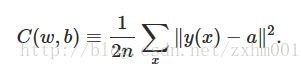
这里w和b分别是所有神经元的和网络的w与b的集合,n是训练样本的数量,x是输入值,y(x)是预期输出值,a是选取当前w和b的时候的实际输出值,∑表示对所有的输入情况求和,||v||用来计算向量的长度。所以其实C(w,b)其实就是表示采取当前的w和b的时候的均方误差,很显然,他不可能是负数,而且越小的时候,表示w和b越合适,神经网络用来进行识别也就越靠谱,越大的时候就越不靠谱。所以现在我们就是要用好多好多的训练样本,一遍又一遍的运算,不断地变换每个神经元和网络中的w和b,想方设法让C(w,b)变小,最好无限接近于0。
对于上述方程,我们先讨论其通用情况C(v),假设v只是一个二维向量(v1,v2)T。根据全微分的定义:

我们只要保证每次v变化时,ΔC都是负数,就能一步步的让C(v)减少,直到最小。这就是梯度下降算法的基本思想了。根据导数的定义,这个梯度就应该是:
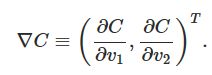
T依旧表示矩阵转置。定义v的每次变化量Δv=(v1,v2)T,那么根据向量的乘法,就有:
ΔC=∇C·Δv
当我们选择Δv=−η∇C(η是一个很小的正数),那么ΔC=−η∥∇C∥^2,明显∥∇C∥^2肯定是一个正数,那ΔC就是一个负数了。
还记得高数书上说过,二元函数到多元函数的微积分是可以类推的么,所以,你们懂的,C(w,b)也就是用这一套了。
对于w和b,就应该是这样:
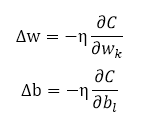
之所以w和b有下标,是因为这里只表示当前神经元和下一个神经元之的活动,wk和bl分别表示当前的w和b。
刚刚说了梯度下降算法的基本原理,其实随机梯度下降就是将输入数据随机切分成多份小的输入数据,以大幅度的提高训练的速度。
而这个时候的对于所选取的样本的平均梯度∇C:
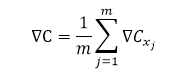
m是从训练数据集重随机选择的输入数据的数量,xj表示第j个输入数据。
对于w和b,也改造下:

我们选取一个η,随机选取一组w和b,计算出当前的梯度∇C,就可以算出Δw和Δb,然后更改w和b,再计算梯度∇C和Δw和Δb,一次又一次的迭代,直到成本函数变得最小,就得到了最合适的w和b的组合。
现在我们就可以写代码了,由于微信公众号不方便贴代码,代码我会放在码云上,原书使用的是Python 2.7,我修改了下,以适应Python 3.6。下面大致解释下代码的思想:
代码中定义了一个叫Network的类,来代表我们的神经网络,我们实例化这个类时,需要输入神经网络的大小,比如我在上一篇文章重说过的,我们设计的神经网络输入层神经元784个,隐藏神经元只有一层,15个,输出神经元10个,那么我们就可以这么实例化network = Network([784,15,10]),不过不知道为什么作者第二层隐藏神经元在前面说15个,而在演示代码中选择的是30个,我在代码里面也是使用的30。我也测试了下,确实选择15个的时候效果不如30个好。
然后给这个神经网络随机赋予w(权重)和b(偏移量)值,代码中使用weights和biases表示,注意第一层是输入神经元,是没有b值的。为了方便理解我把上期的图片贴在下面。

每条线上有一个w值;除了输入神经元,每个神经元上有一个b值。对于如此复杂的数组,我们引入了一个python中用于科学计算的库,叫Numpy,在控制台使用命令python -m pip install numpy安装后就可以引入了。除了复杂列表这种数据结构外,里面还有很多实用的数学方法,比如按正态分布随机生成的random,矩阵点积的dot等等,我也第一次接触这个库,数学渣表示看着感觉超级高大上。
所以biases[1][j]就是表示第三层第j个神经元的b值。weights[1][j][k]就是表示第二次第k个神经元和第三层第j个神经元之间连线的w值。有没有感觉这个weight有点奇怪,为什么j和k颠倒了,其实这么表示有个好处,在上一篇文章重我们有说到,利用S曲线神经元,下一层神经元的值应该满足:
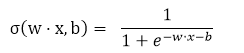
比如第二层神经元的值是向量m,那么第三层神经元的值向量n就应该是对向量m,w,b重的每个值分别进行计算。这里将w的表示颠倒过来,就可以直接对向量m,w,b进行如下计算,m·w+b,不用分别计算了。
再然后就是将训练数据集随机拆分成小的数据集,设置一个训练周期,设置一个η值,对每个小的数据集使用梯度下降。使用梯度下降算法的过程中,会用到一个叫反向传播(backpropagation)算法东西,这是一种快速计算成本函数梯度(∇C)的算法,本文不会详细讨论这个算法,这是下一篇文章的任务。
我们现在有了∇C,有了η,就有了Δw和Δb了,就可以迭代了。
当然这里面还有一个怎么读取训练数据和测试结果的问题,作者直接给了代码,我改造成了基于Python 3.6的,也会给出来。最后就来看运行的结果吧,作者选取的神经网络大小是[748,30,10],训练周期30,每次参与运算的小部分训练样本个数是10个,η是3,他得出的训练结果:

就是说他训练之后的识别精度高达95%,我的训练结果也差不多:
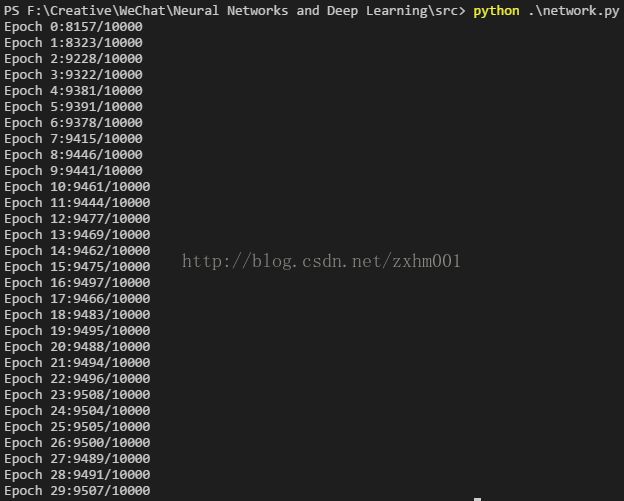
95%的识别率,比瞎猜的10%已经不知道高到哪里去了,而且我们没有自己设置一系列的w和b的值,而是让电脑自己去学习去设置。我们不知道他们怎么学习的,我们也不知道每个神经元代表什么,我们更不知道w和b对于电脑的世界有什么意义,但是他们就是做到了。
下期,我们就来解释文中留下的一个问题:反向传播(backpropagation)算法。
另外我用到的所有文件都在网址:https://git.oschina.net/zxhm/Neural-NetWork-and-Deep-Learning下,里面有我的代码,也有原作者的代码,还有用到的数据。用GIT的小伙伴可以直接clone过来,以后更新后直接pull就可以了。不用GIT的小伙伴在我每期文章更新后可以重新下载代码。=,,
欢迎关注我的微信公众号获取最新文章:

C(w,b)≡12n∑x∥y(x)−a∥2