几种目标检测网络模型对比(RCNN系列、Mask-RCNN、R-FCN、YOLO、SSD、FPN等)
1 RCNN
RCNN具体原理解析

网络分为四个部分:区域划分、特征提取、区域分类、边框回归
区域划分:使用selective search算法画出2k个左右候选框,送入CNN
特征提取:使用imagenet上训练好的模型,进行finetune
区域分类:从头训练一个SVM分类器,对CNN出来的特征向量进行分类
边框回归:使用线性回归,对边框坐标进行精修
优点:
ss算法比滑窗得到候选框高效一些;使用了神经网络的结构,准确率比传统检测提高了
缺点:
1、ss算法太耗时,每张图片都分成2k,并全部送入CNN,计算量很大,训练和inference时间长
2、四个模块基本是单独训练的,CNN使用预训练模型finetune、SVM重头训练、边框回归重头训练。微调困难,可能有些有利于边框回归的特征并没有被CNN保留
2 Fast-RCNN
Fast-RCNN具体原理解析


相对RCNN,准确率和速度都提高了,具体做了以下改进:
1、依旧使用了selective search算法对原始图片进行候选区域划分,但送入CNN的是整张原始图片,相当于对一张图片只做一次特征提取,计算量明显降低
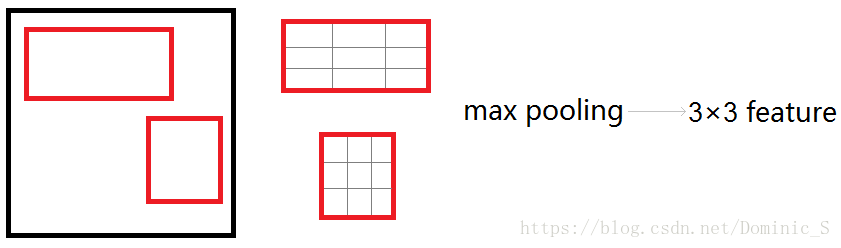
2、在原图上selective search算法画出的候选区域对应到CNN后面输出的feature map上,得到2k个左右的大小长宽比不一的候选区域,然后使用RoI pooling将这些候选区域resize到统一尺寸,继续后续的运算
3、将边框回归融入到卷积网络中,相当于CNN网络出来后,接上两个并行的全连接网络,一个用于分类,一个用于边框回归,变成多任务卷积网络训练。这一改进,相当于除了selective search外,剩余的属于端到端,网络一起训练可以更好的使对于分类和回归有利的特征被保留下来
4、分类器从SVM改为softmax,回归使用平滑L1损失
缺点:因为有selective search,所以还是太慢了,一张图片inference需要3s左右,其中2s多耗费在ss上,且整个网络不是端到端
3 Faster-RCNN
Fseter-RCNN具体原理解析 1
Fseter-RCNN具体原理解析 2
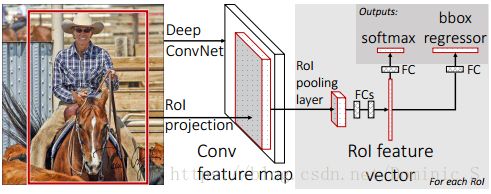
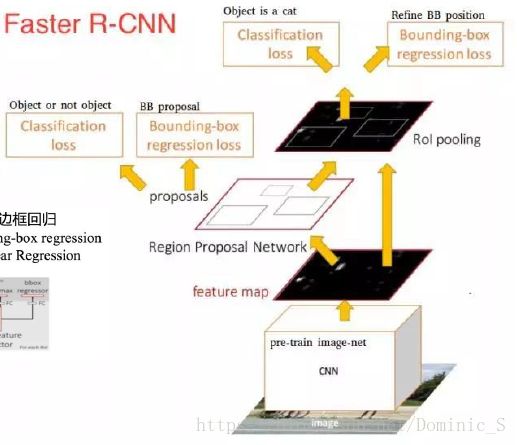

引入RPN,Faster-RCNN相当于Fast-RCNN+RPN,准确率和速度进一步提高,主要做了以下改进:
1、移除selective search算法,还是整张原始图片输入CNN进行特征提取,在CNN后面的卷积不再使用ss算法映射过来的候选区域,而是采用新的网络RPN,使用神经网络自动进行候选区域划分
2、RPN通过生成锚点,以每个锚点为中心,画出9个不同长宽比的框,作为候选区域,然后对这些候选区域进行初步判断和筛选,看里面是否包含物体(与groundtruth对比IoU,大于0.7的为前景,小于0.3的为背景,中间的丢弃),若没有就删除,减少了不必要的计算
3、有效的候选区域(置信度排序后选取大概前300个左右)进行RoI pooling后送入分类和边框回归网络
优点:端到端网络,整体进行优化训练;使用神经网络自动生成的候选区域对结果更有利,比ss算法好;过滤了一些无效候选区,较少了冗余计算,提升了速度
RPN网络和锚点具体原理和训练过程
RPN训练:
1、加载预训练模型,训练RPN
2、训练fast-rcnn,使用的候选区域是RPN的输出结果,然后进行后续的bb的回归和分类
3、再训练RPN,但固定网络公共的参数,只更新RPN自己的参数
4、根据RPN,对fast-rcnn进行微调训练
4 R-FCN
R-FCN具体原理解析
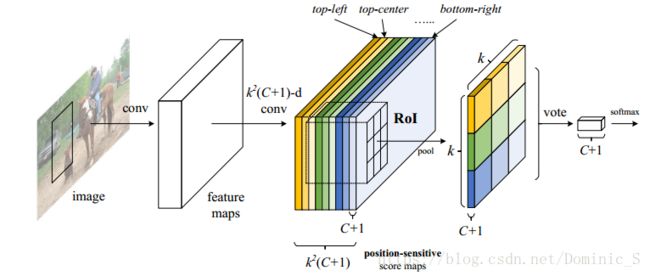
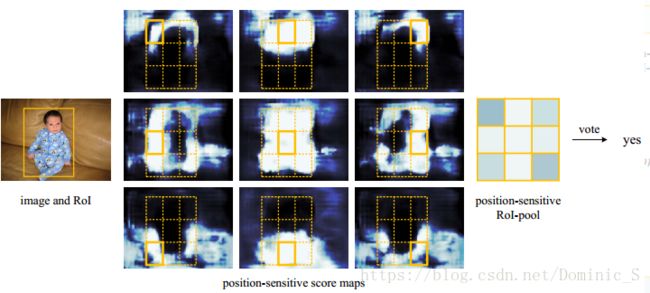
在Faster-RCNN基础上,进一步提高了准确率,主要以下改进:
1、使用全卷积层代替CNN basenet里面的全连接层
2、CNN得到的feature map在RoI pooling之后变成3x3大小,把groundtruth也变成3x3大小,对9宫格每个区域分别比较和投票
5 YOLO(you only look once)
YOLO具体原理解析1
YOLO具体原理解析2

动图来自于原博客,感谢整理
YOLO 属于回归系列的目标检测方法,与滑窗和后续区域划分的检测方法不同,他把检测任务当做一个regression问题来处理,使用一个神经网络,直接从一整张图像来预测出bounding box 的坐标、box中包含物体的置信度和物体所属类别概率,可以实现端到端的检测性能优化
原理如下:
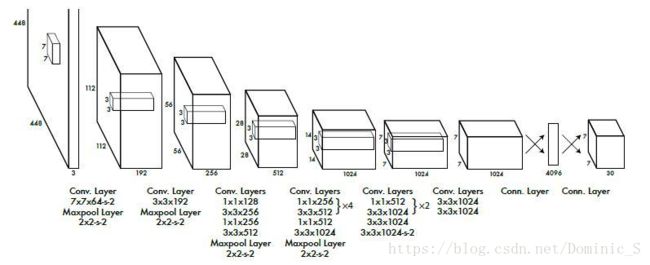
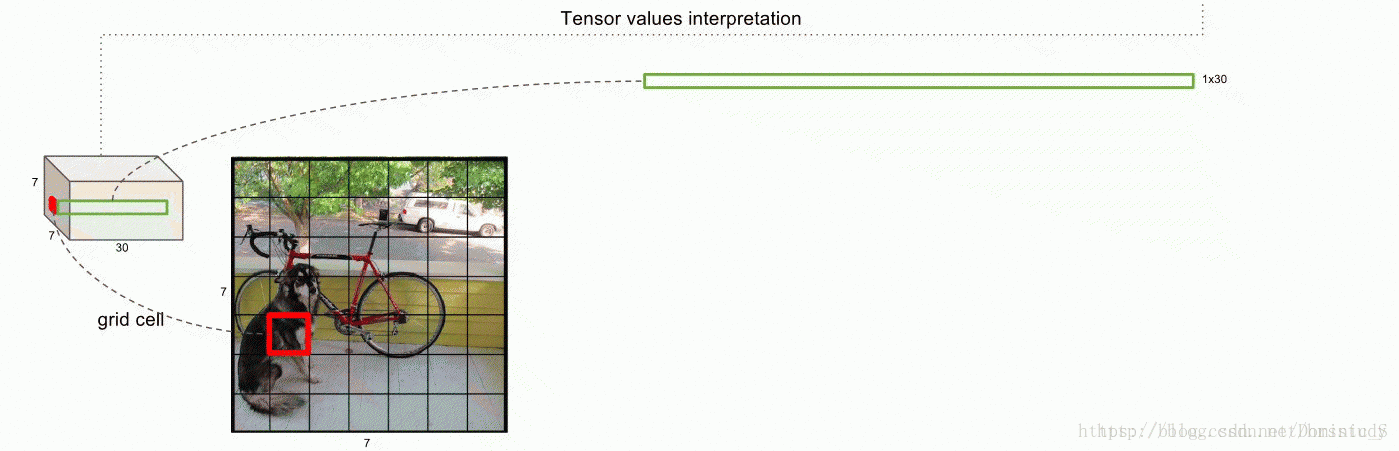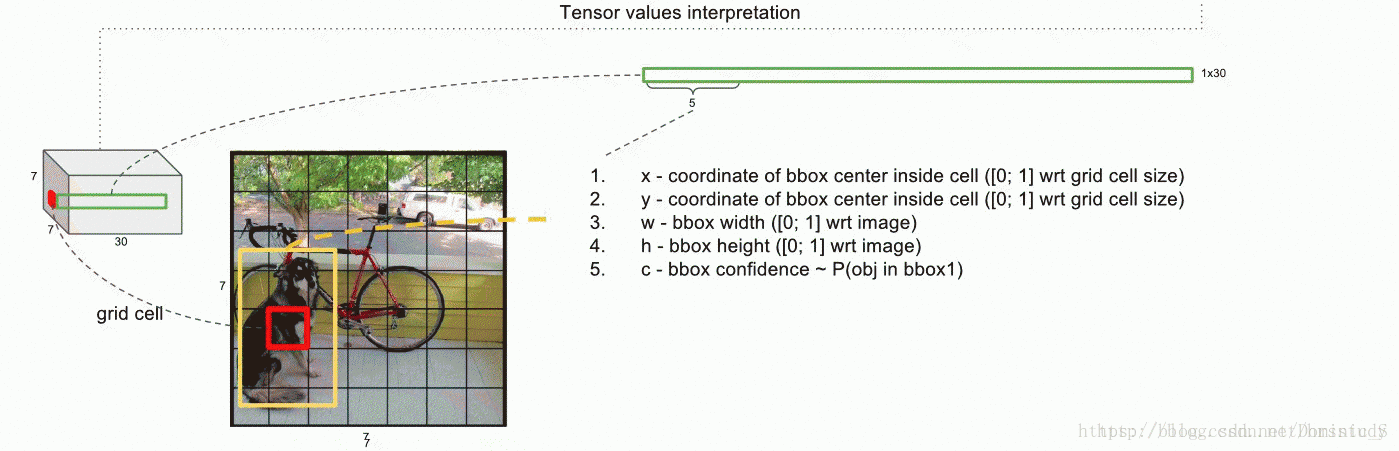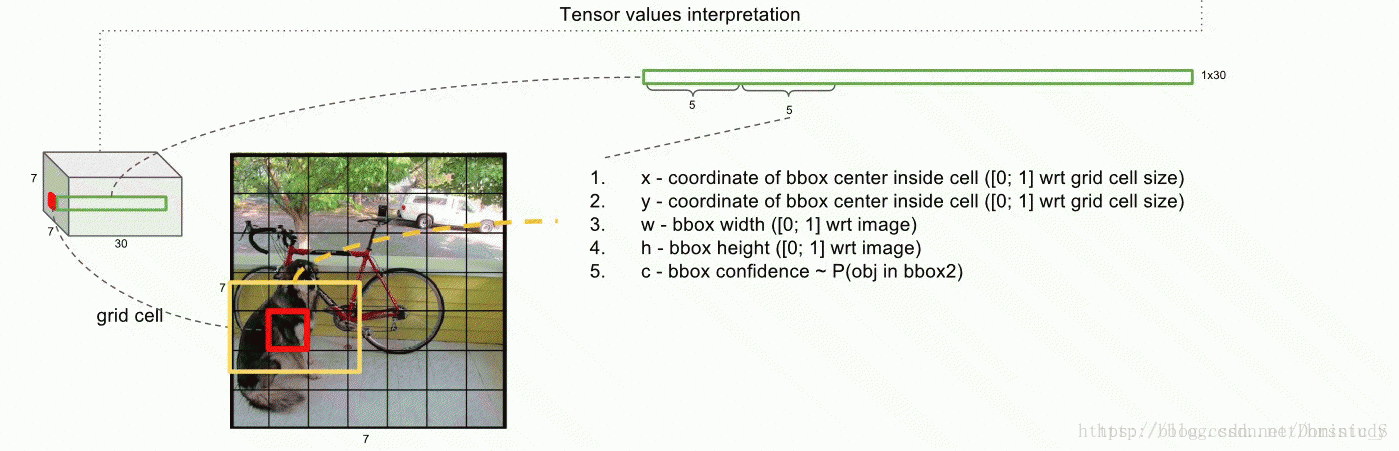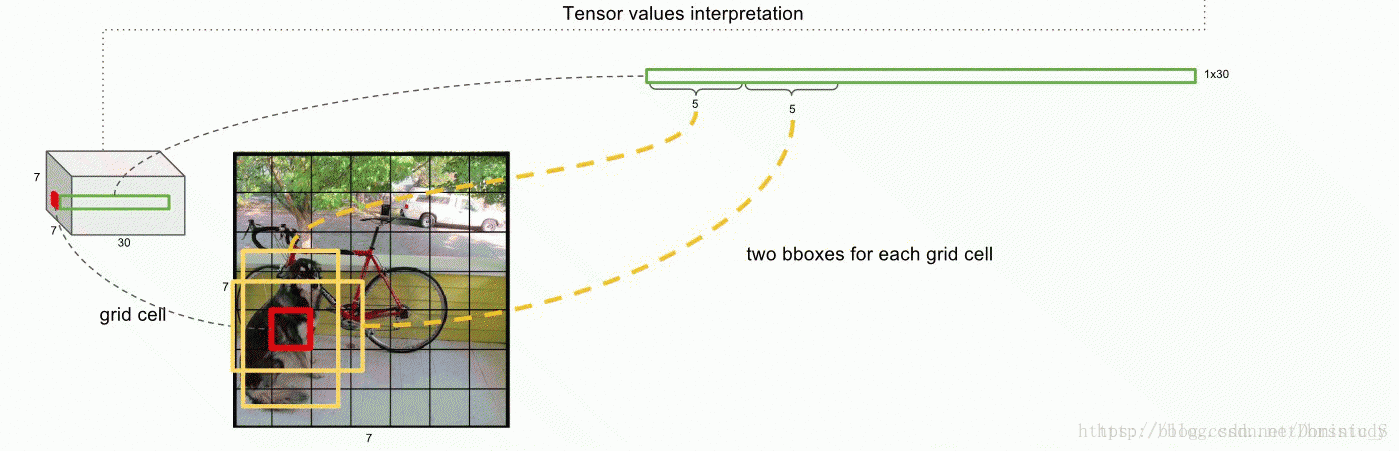
输入一张图片,图片中包含N个object,每个object包含4个坐标(x,y,w,h)和1个label。在网络最后面会生成一个7x7x30的三维矩阵,其中7x7对应到原图,就是将图片划分为7x7个grid cell,每个cell预测两个bounding box,30=5+5+20,第一个5代表预测的第一个bounding box的4个坐标和置信度,第二个5代表第二个bounding box的4个坐标和置信度,最后的20代表PASCAL VOC数据集的20个分类。
预测的结果和groundtruth进行对比,每个object的groundtruth的中心对应到原图会落在某个grid cell里面,该object的检测由这个grid cell负责。预测的结果如果也落在该grid cell里,代表该grid cell有object(前提),分数(score)是预测bounding box与groundtruth的IoU值,若没有落在该grid cell中,代表没有object,分数(score)为0。最后会得到一个20x(7x7x2)=20x98的score矩阵,其中20行代表20个分类,98列代表的是整张图输出的所有bounding box,整个矩阵代表每个bounding box预测为这20个分类的分数。对于同一个类来说,有98个bounding box,这里用非极大值抑制法(NMS)进行候选框的筛选和合并。
每个grid cell负责:
1、预测两个bounding box
2、每个bounding box是否包含物体,置信度为0(无物体)或IoU(有物体)
3、每个bounding box所包含物体分别属于20个分类的概率
Inference: 输入一张图像,跑到网络的末端得到7x7x30的三维矩阵,这里虽然没有计算IOU,但是由训练好的权重已经直接计算出了bounding box的confidence。然后再跟预测的类别概率相乘就得到每个bounding box属于哪一类的概率。
YOLO缺点:
1、对小目标和密集型目标检测的效果差,如一群小鸭子(因为图片划分为7x7个grid cell,而每个cell只产生两个bounding box,意思就是每个grid cell的区域最多只会预测两个object)(是否可以用裁剪方法得到原图的局部放大图?每个grid cell预测多个bounding box?最后的卷积使用14x14x20?)
2、YOLO的物体检测精度低于其他state-of-the-art的物体检测系统。
3、YOLO容易产生物体的定位错误
YOLO优点:
1、YOLO检测物体非常快(45-155FPS)
2、YOLO可以很好的避免背景错误,产生false positives(可以看到全局图像,有上下文信息)
6 SSD(single shot mutibox detector)
SSD具体原理解析
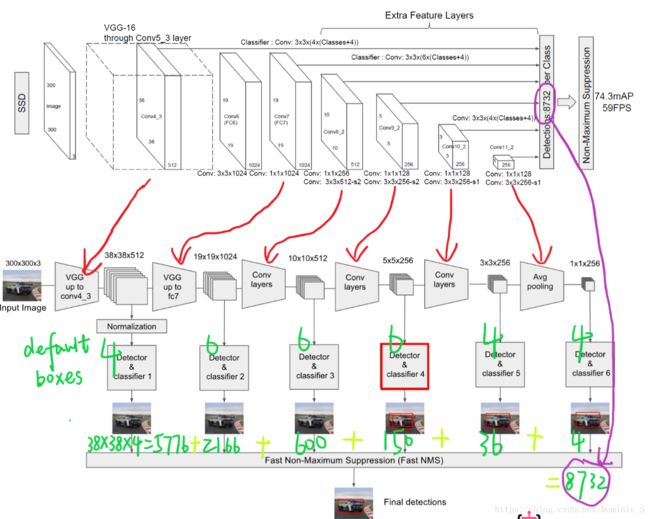
图片来自于原博客
SSD也是使用回归的方法直接预测bounding box和分类,没有使用候选区域。
1、算法的主网络结构是VGG16,将两个全连接层改成卷积层再增加4个卷积层构造网络结构
2、对其中5个不同的卷积层的输出分别用两个3 * 3的卷积核进行卷积,一个输出分类用的confidence,每个default box生成21个confidence(这是针对VOC数据集包含20个object类别而言的);一个输出回归用的localization,每个default box生成4个坐标值(x,y,w,h)
3、每个feature map中default box的来源是由prior box通过计算产生的,包括default box的长宽比
上述5个feature map中每一层的default box的数量是给定的(5个层总和是8732个)。最后将前面三个计算结果分别合并然后传给loss层。
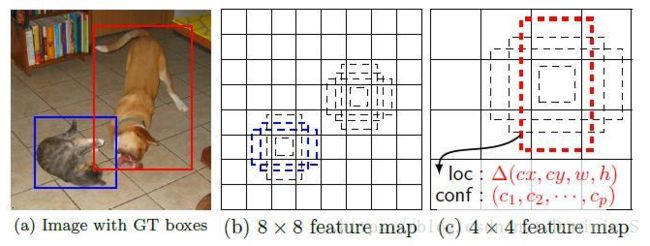
注意:
1、feature map cell 是指feature map中每一个小格子,如图中分别有64和16个cell。default box是指在feature map的每个小格(cell)上都有一系列固定大小的box,如图中每个cell包含4个default box(这部分和Faster-RCNN RPN中的锚点和画候选区域有点像,Faster-RCNN产生锚点和边框的地方是在最后一层卷积上,使用RPN产生的,而SSD则是在多个层次的feature map上产生default box,然后把预测的坐标和分类结果进行拼接)。
2、假设每个feature map cell有k个default box,则每个default box都需要预测c个类别score和4个offset,如果一个feature map的大小是m×n,也就是有m * n个feature map cell,则该feature map就一共有(c+4)* k * m * n 个输出。这些输出个数的含义是:采用3×3的卷积核对该层的feature map卷积时卷积核的个数,包含两部分(实际code是分别用不同数量的3 * 3卷积核对该层feature map进行卷积):数量c * k * m * n是confidence输出,表示每个default box的confidence,也就是类别的概率;数量4 * k * m * n是localization输出,表示每个default box回归后的坐标)。
3、最后对使用NMS算法对所有层产生的这些box区域进行筛选合并
SSD算法的核心:
1、对于每个feature map cell都使用多种横纵比的default boxes,所以算法对于不同横纵比的object的检测都有效
2、对default boxes的使用来自于多个层次的feature map,而不是单层,所以能提取到更多完整的信息
优点:
1、检测速度很快
2、检测准确率比faster-rcnn和yolo高
缺点:
文中作者提到该算法对于小的object的detection比大的object要差,还达不到Faster R-CNN的水准。作者认为原因在于这些小的object在网络的顶层所占的信息量太少,另外较低层级的特征非线性程度不够,所以增加输入图像的尺寸对于小的object的检测有帮助。另外增加数据集对于小的object的检测也有帮助,原因在于随机裁剪后的图像相当于“放大”原图像,所以这样的裁剪操作不仅增加了图像数量,也放大了图像。不过这样速度很慢。
7 对于小目标难检测问题的解决——FPN(CVPR2017)
FPN具体原理解析
低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。对图像feature的利用有以下四个方法:
1)输入网络前进行裁切,然后scale,缩放图像,这种方法会增加网络训练和预测的时间
2)类似于faster-rcnn和fast-rcnn,对卷积网络最后一层的feature map进行利用
3)类似于SSD,在网络中间,抽取一些卷积层产生的feature map进行利用
4)RPN
FPN类似于SSD+FCN+RPN,先自底向上进行正常的网络前向传播,每个阶段生成空间尺寸不断缩小的feature map,然后再从顶部的feature map(空间尺寸最小的那个)开始,进行2倍上采样,倒数第二层的feature map进行1x1卷积后(通道数匹配),两个feature map进行加和,然后再用3x3的卷积对新的feature map进行卷积融合,去除上采样加和的混叠。之后就按照这个思路不断上采样加和到前一个stage(前向传播中空间尺寸一致的当做一个stage),每一个stage生成的新feature map都独立进行预测。这里的预测可以是把生成的feature map送入RPN中,进行滑窗生成锚点和对应的bounding box,总共有15种不同的锚点。
8 Mask-RCNN(201703)
Mask-RCNN具体原理解析1
Mask-RCNN具体原理解析2
Mask-RCNN具体原理解析3(RoI Align解释)
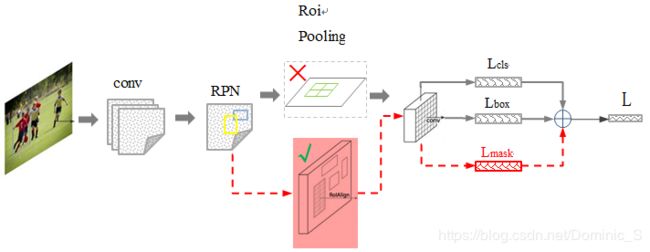

Mask-RCNN主要是基于Faster-RCNN,在RoI操作之后增加了一个分支,使用FCN进行语义分割操作,主要技术要点如下:
1、在RoI操作之后,除了接全连接的分类和边框回归之外,额外引出一个分支,用FCN进行语义分割,所以最终模型的loss来自于三个部分,分别是:分类loss、回归loss和分割loss
2、引入RoIAlign,替代原来的RoI pooling,RoI pooling是在fast-rcnn里提出的,用于对大小不同的候选框进行resize之后送入后面的全连接层分类和回归,但RoI pooling计算时存在近似/量化,即对浮点结果的像素直接近似为整数,这对于分类来说影响不大(平移不变性),但新引入的Mask分割来说,影响很大,造成结果不准确,所以引入了RoI Align,对浮点的像素,使用其周围4个像素点进行双线性插值,得到该浮点像素的估计值,这样使结果更加准确
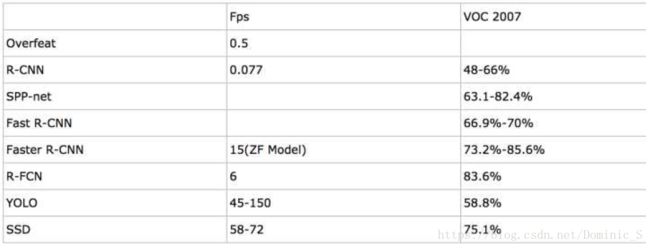
9 几种检测模型性能对比