DenseNet——对图片“特征”的极致利用 (目标检测)(one/two-stage)(深度学习)(CVPR 2017)
论文名称:《 Densely Connected Convolutional Networks 》
论文下载:https://arxiv.org/pdf/1608.06993.pdf
论文代码:https://github.com/liuzhuang13/DenseNet
1、类比ResNet:
DenseNet的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能。

相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个L层的网络,DenseNet共包含个L*(L+1)/2 连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
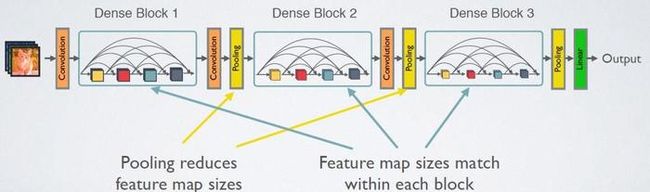
需要明确一点,dense connectivity 仅仅是在一个dense block里的,不同dense block 之间是没有dense connectivity的,比如下图所示。
2、DenseNet细节:
(1)解决了深层网络的梯度消失问题;
(2)加强了特征的传播;
(3)实现特征重用(更有效地利用了feature);
(4)减少了模型参数。
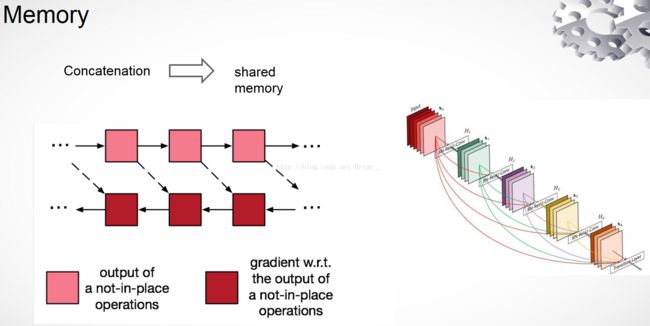
DenseNet的结构进一步使用了ResNet中的shortcut connections思想,将所有的层互相连接起来。在这个新架构中,每一层的输入都包含了所有较早的层的feature maps,而且它的输出被传递至每个后续层。这些feature maps通过depth concatenation在一起。
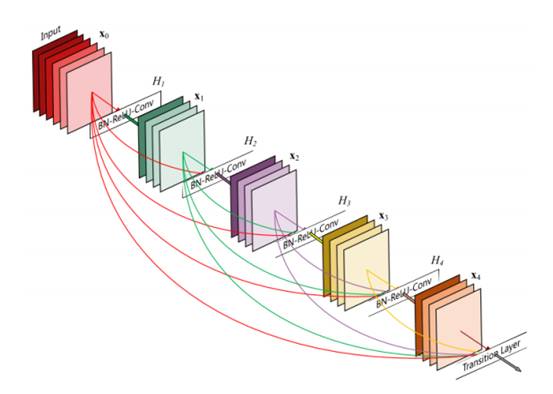
上图是一个详细的Dense Block模块,其中层数为5,即具有5个BN+Relu+Conv(3*3)这样的layer,网络增长率为4,简单的说就是每一个layer输出的feature map的维度为4。
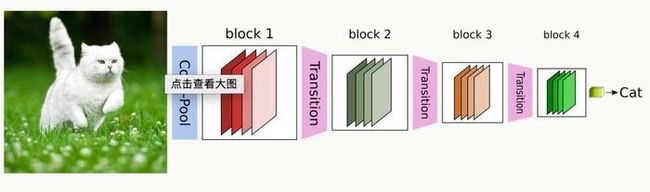
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起。
这里,由于DenseNet的每一个Dense Block模块都利用到了该模块中前面所有层的信息,即每一个layer都和前面的layer有highway的稠密连接。假设一个具有L层的网络,那么highway稠密连接数目为L*(L+1)/2。
和Resnet不同的是,这里的连接方式得到的feature map做的是concat操作,而resnet中做的是elementwise操作。
其中ResNet的非线性变换方程如下:
![]()
DensNet的非线性变换方程如下:
![]()
H代表是非线性转化函数(non-liear transformation),它是一个组合操作,其可能包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。注意这里L层与L-1层之间可能实际上包含多个卷积层。

DenseNet的稠密连接方式具有诸多的优势,增加了梯度的传递,特征得到了重用,甚至减少了在小样本数据上的过拟合。
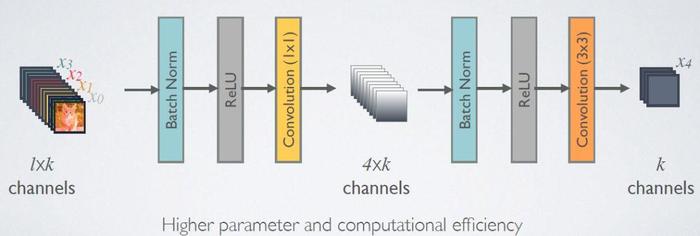
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,如图7所示,即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
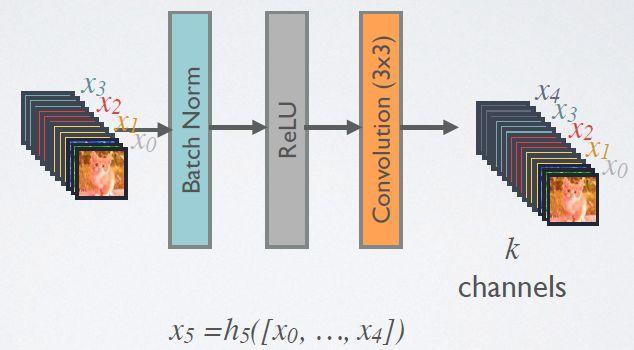
随着层数增加,尽管k设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有k个特征是自己独有的。
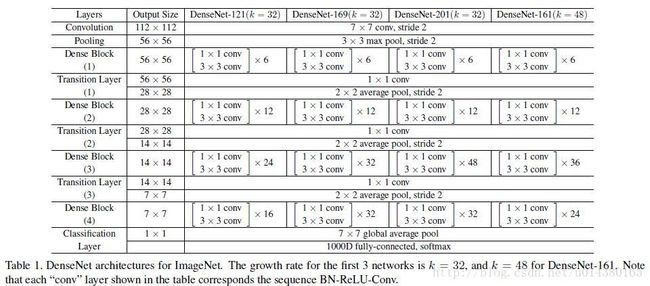
上表就是整个网络的结构图。这个表中的k=32,k=48中的k是growth rate,表示每个dense block中每层输出的feature map个数。为了避免网络变得很宽,作者都是采用较小的k,比如32这样,作者的实验也表明小的k可以有更好的效果。根据dense block的设计,后面几层可以得到前面所有层的输入,因此concat后的输入channel还是比较大的。另外这里每个dense block的3*3卷积前面都包含了一个1*1的卷积操作,就是所谓的bottleneck layer,目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征,何乐而不为。另外作者为了进一步压缩参数,在每两个dense block之间又增加了1*1的卷积操作。因此在后面的实验对比中,如果你看到DenseNet-C这个网络,表示增加了这个Translation layer,该层的1*1卷积的输出channel默认是输入channel到一半。如果你看到DenseNet-BC这个网络,表示既有bottleneck layer,又有Translation layer。
bottleneck和transition layer操作。在每个Dense Block中都包含很多个子结构,以DenseNet-169的Dense Block(3)为例,包含32个1*1和3*3的卷积操作,也就是第32个子结构的输入是前面31层的输出结果,每层输出的channel是32(growth rate),那么如果不做bottleneck操作,第32层的3*3卷积操作的输入就是31*32+(上一个Dense Block的输出channel),近1000了。而加上1*1的卷积,代码中的1*1卷积的channel是growth rate*4,也就是128,然后再作为3*3卷积的输入。这就大大减少了计算量,这就是bottleneck。至于transition layer,放在两个Dense Block中间,是因为每个Dense Block结束后的输出channel个数很多,需要用1*1的卷积核来降维。还是以DenseNet-169的Dense Block(3)为例,虽然第32层的3*3卷积输出channel只有32个(growth rate),但是紧接着还会像前面几层一样有通道的concat操作,即将第32层的输出和第32层的输入做concat,前面说过第32层的输入是1000左右的channel,所以最后每个Dense Block的输出也是1000多的channel。因此这个transition layer有个参数reduction(范围是0到1),表示将这些输出缩小到原来的多少倍,默认是0.5,这样传给下一个Dense Block的时候channel数量就会减少一半,这就是transition layer的作用。文中还用到dropout操作来随机减少分支,避免过拟合
3、DenseNet的缺点:
(1) 这里假设第L层输出K个feature map,即网络增长率为K,那么第L层的输入为K0+K*(L-1),其中K0为输入层的维度。也就是说,对于Dense Block模块中每一层layer的输入feature map时随着层数递增的,每次递增为K,即网络增长率。那么这样随着Dense Block模块深度的加深,后面的输入feature map的维度是很大的。为了解决这个问题,在Dense Block模块中加入了Bottleneck 单元,即1*1卷积进行降维,输出维度都被降到4K维(K为增长率)。
(2)每一个DenseBlock模块的输出维度是很大的,假设一个L层的Dense Block模块,假设其中已经加入了Bottleneck 单元,那么输出的维度为,第1层的维度+第2层的维度+第3层的维度+******第L层的维度,加了Bottleneck单元后每层的输出维度为4K,那么最终Dense Block模块的输出维度为4K*L。随着层数L的增加,最终输出的feature map的维度也是一个很大的数。为了解决这个问题,在transition layer模块中加入了1*1卷积做降维。
4、总结:
该文章提出的DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。