一文看懂去中心化分布式存储IPFS/FileCoin
去中心化存储系统分为两部分IPFS和FileCoin。IPFS是去中心化存储网络,是一个协议是基础设施,比如水电,机场,公路,房子。Filecoin是IPFS存储的激励层,类似上层建筑,比如水电房子公路如何收费,如果分配。具体到存储,FileCoin类似存储交易所,通过付费方式撮合存储交易并提供保障交易执行的制度。
IPFS的功能可简单类比目前的BT下载+内容寻址(分布式哈希表DHT)。我们知道BT种子的发布和下载的流程是用户制作种子文件并上传到中心化服务器(百度云盘,Bt论坛),然后用户通过种子论坛,百度搜索种子文件,下载种子文件后通过迅雷等下载软件下载内容,但是一旦百度禁止,种子就找不到了。同时种子文件对应的原始数据源节点信息也是由中心化的下载软件比如迅雷维护的,它负责告诉你哪些节点有该数据,是中心化的,如果迅雷出故障或者屏蔽,你是不可能下载的。而IPFS系统中,通过DHT,大量节点保存有种子及数据源节点信息,一个节点挂掉,还可以从其他节点获取这个种子及数据源信息,然后和对应节点建立连接传输数据,是去中心化的,不存在单点故障。当然IPFS具体技术设计还是有不少差异的,也新增了额外的功能。简单来说,IPFS就是一个去中心化的按内容寻址的分布式存储系统。
IPFS解决了分布式存储和查找,传送数据,但是没法保证数据的稳定存储。就像BT下载一样,我们可能找到了一个种子,但是下载时发现速度为0,这可能是因为保存有该种子数据的节点已经删除了该数据或者禁止了数据上传。IPFS也一样,其他节点是自愿存储网络的其他节点的数据,没有强制性规范,任何节点是可能也可以随时清理数据的。但是事实上,持久性确定性的数据存储需求是广泛存在的,这个需求的解决方案也很明显----有偿存储。一部分节点(客户方)希望出钱让别人帮忙存储数据,而有些节点(存储方)有空闲空间,如果有钱赚也是非常愿意存储的。不像中心化的阿里云提供的云存储,阿里云是大企业,大家信任他。而在IPFS系统中,节点是小个体,客户方和存储方是陌生人,是没有任何信任的,双方对数据存储量,存储时间,是否违约等都没法信任。因而需要代码制度规范这个交易建立信任,如果存储方违约,代码就可以惩罚它,且可以有多个存储方,从而一个存储方节点违约(清除数据)也不会影响到数据的安全性。这个代码制度规范就是FileCoin。
FileCoin核心技术
那FileCoin定义了哪些规范来保障存储安全呢?核心是两个证明
复制证明(Proofs-of-Replication)
简单来说,就是存储方需要证明自己已经将客户方的数据复制到指定的物理设备上了。 同时客户方为了加强数据安全性,他可能要求存5份完整的相同文件在存储方的物理机器上以冗余备份。但是如何确保存储方真正存储了5份,而不是只存储了一份呢?因为存储方可能等到验证的时候再复制出4份,这就还需要证明存储方独立存储了每份副本,具体而言需要解决防御如下攻击。

从上表格可知防范措施的核心是Cipher block chaining这些类似算法, 那它又是如何做到编码慢而解码快呢?数据被分割多次编码,且编码过程是串行的,也就是后一个计算单元依赖于前面一个计算单元的编码结果

左侧是一个有向图,计算单元c2的编码是要依赖于c1的编码结果。我们不可能同时进行C1和C2,图上的其他箭头也是如此。为了完成整个数据的编码,我们需要持续编码5次,这样我们的整个延长了编码时间。而解码则可以并行,也就是说我们可以一次解码从C1到C5的所有单元对应的数据,这样大大提升了解码速度。但该算法仍有弊端,依赖关系比较单一,也就是后面的单元仅仅依赖于前一个单元。所以filecoin团队在最新的论文里提出了用depth robust graph来编码数据,depth robust graph 上节点之间的依赖关系更强,可以更好的抵御攻击。右侧同样是一个含有5个节点的有向图,但是计算单元之间的依赖关系更复杂。算法具体实现细节请查看:https://eprint.iacr.org/2018/678.pdf。
上面的编码协议定义了数据如何被seal来避免上面的攻击, 但是具体如何检验的呢?
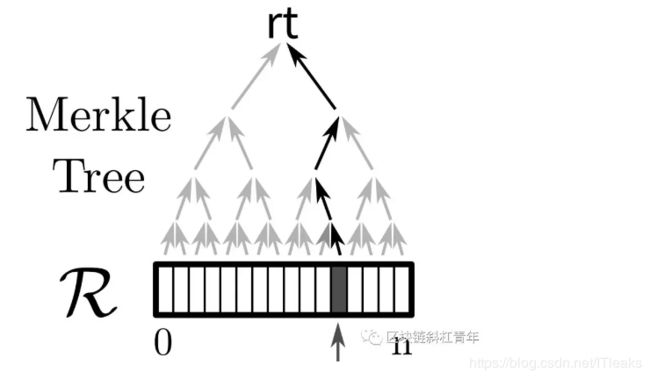
用户和系统都会发起随机挑战,给出一个随机数,让存储方给出证明。具体采取了类似Merkle树的证明方法,一个数据备份被分割为很多小块,形成merkle树,树根Root就是副本的hash值。当用户或者系统要挑战存储方时,只需提出随机挑战请求,比如验证节点挑战位置12,那么矿工就需要计算从叶子节点D12到根节点Root的路径,输出一个证明给发起挑战的验证节点。(Merkle证明的相关知识可以看https://blog.csdn.net/ITleaks/article/details/79992072)
时空证明(Proofs-of-Spacetime)
存储收费不仅和数据的占用空间有关,更和存储时间相关。因而如何生成时空证明也很重要。时空证明是连续时间的大量的复制证明形成的证明链, 具体机制如下。

具体算法过程请查看:https://filecoin.io/filecoin.pdf
FileCoin角色
存储矿工
存储数据及挖矿出块,存储的数据包括两部分:
-
用户数据seal后的数据
-
链上数据的副本
filecoin链本身的数据也是分布式存储的,每个矿工有副本
检索矿工(CDN矿工)
真正存储用户数据的矿工可能离查询服务的用户很远,这时查询服务的用户下载数据的速度很慢甚至连接不上,这时就出现为提高速度和服务的矿工来缓存数据以提供更好服务,这个非常贴近CDN服务。具体方式可能有
-
存储热门数据(非存储矿工),并全球分布式部署,以提供更优质服务。
-
自己也可同时担任存储矿工角色,就像阿里云也提供CDN服务。
-
可以从filecoin网络有偿获取,也可以从IPFS网络免费获取。
检索客户和存储客户
检索客户是指那些从filecoin获取数据内容的用怒。存储客户是指那些希望filecoin网络为自己存储数据的用户。
FileCoin基本概念
filecoin本身也是一条链,所以公链里的概念,filecoin也有。
Actor
filecoin里的actor类似ETH, EOS里的账号, 有一个地址和它绑定。感觉FileCoin这个是参考以太坊的,这个Actor结构对以太坊的Account数据很像。code是该actor的代码,Head是该账号状态数据树root, balance是该actor 代币FIL余额。
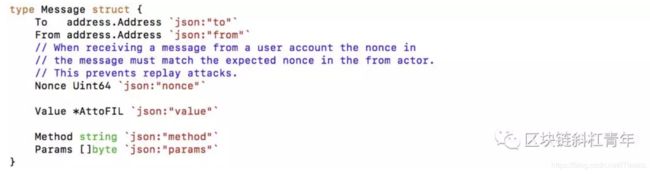
Message
message对应ETH,EOS里的交易。filecoin的交互以message的方式发起,比如发起存储需求。一个Message包含发起actor地址,目标actor地址,金额,调用的函数以及参数。
和EOS一样,Message也是用来执行的,执行结果保存在状态数据里,不像EOS状态数据保存在chainbase里,filecoin状态数据以IPLD的方式存储,IPLD也是IPFS采用的数据结构,filecoin复用了。
区块
filecoin的区块是用来打包message的。filecoin的区块信息和以太坊的区块信息很像,包含矿工的地址,区块高度,权重,交易,状态merkle root,PoSt证明。PoSt证明对应POW里的随机碰撞Nonce值,用来证明该区块的算力(权重)。

挖矿共识算法
我们知道ETH的POW谁先算出hash值谁就是合法区块打包者(Leader),EOS的DPOS 21个超级节点轮到谁了谁就打包。FileCoin也有对应的共识协议。理论上来说,filecoin可以使用任何共识协议比如POW和DPOS。但是既然存储天然是一个可衡量和有成本的资源,Filecoin使用Proof-of-Spacetime(PoSt)就是很自然的了,PoSt是filecoin在验证矿工数据存储真实性的时候产生的。矿工的当前存储数据相对于整个网络的存储比例转化为矿工投票权(voting power of the miner)。干活的同时把矿也挖了,是不是太环保太完美了。这个有点像BTM号称的AI友好的POW挖矿,挖矿的同时做AI计算,但是BTM的这个POW实际落地和应用价值只是呵呵了,但PoSt挖矿可是实实在在的边存储边挖矿。 filecoin每一个周期里,该算法预期选举出一个Leader,但是也有可能选举出来多个Leader。被选举出来的leader创建新block,并把新的block对网络进行广播。由于同一高度可能有多个Leader,因而也是可能存在短暂分叉的,但是最后确定的主链以最大PoSt量的链作为主链。
附录
FileCoin搭建测试网络请参考:FileCoin测试网络上线了,分布式去中心化存储实际性一步
|**************************************************
* 本文来自CSDN博主"爱踢门",喜欢请点关注
* 转载请标明出处:http://blog.csdn.net/itleaks
***************************************************|
如果你对EOS,ETH技术及开发感兴趣,请入QQ群讨论: 829789117

如需实时查看最新文章,请关注公众号"区块链斜杠青年",一起探索区块链未来
