简介
服务网格本质上还是远程方法调用(RPC),而在ignite中注册的服务本质体现还是以cache的形式存在,集群中的节点可以相互调用部署在其它节点上的服务,而且ignite集群会负责部署服务的容错和负载均衡,并且服务可以在集群节点间传播(前提是节点类路径中包含服务类),并且给服务的部署方式提供了多种选择。
ignite服务部署的最常见的两种方式: 集群单例和节点单例

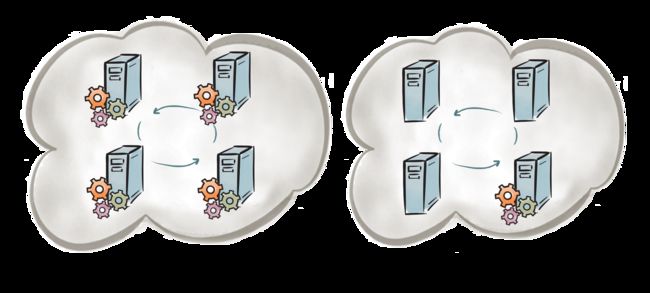
节点单例(deployNodeSingleton) : 在节点范围内的单例,表示针对同一个服务集群中每个节点上只有一个实例。当在集群组中启动了新的节点时,Ignite会自动地在每个新节点上部署一个新的服务实例。
集群单例(deployClusterSingleton) :在集群范围内的单例,表示一个服务在整个集群中只有一个实例。当部署该服务的节点故障或者停止时,Ignite会自动在另一个节点上重新部署该服务。然而,如果部署该服务的节点仍然在网络中,那么服务会一直部署在该节点上,除非拓扑发生了变化。
服务节点
- 定义服务
public interface MyCounterService {
/**
* Increment counter value and return the new value.
*/
int increment() throws CacheException;
/**
* Get current counter value.
*/
int get() throws CacheException;
}@Component
public class MyCounterServiceImpl implements Service, MyCounterService {
/** Auto-injected instance of Ignite. */
@IgniteInstanceResource
private Ignite ignite;
/** Distributed cache used to store counters. */
private IgniteCache cache;
/** Service name. */
private String svcName;
/**
* Service initialization.
*/
@Override public void init(ServiceContext ctx) {
// Pre-configured cache to store counters.
cache = ignite.cache("myCounterCache");
svcName = ctx.name();
System.out.println("Service was initialized: " + svcName);
}
/**
* Cancel this service.
*/
@Override public void cancel(ServiceContext ctx) {
// Remove counter from cache.
cache.remove(svcName);
System.out.println("Service was cancelled: " + svcName);
}
/**
* Start service execution.
*/
@Override public void execute(ServiceContext ctx) {
// Since our service is simply represented by a counter
// value stored in cache, there is nothing we need
// to do in order to start it up.
System.out.println("Executing distributed service: " + svcName);
}
@Override public int get() throws CacheException {
Integer i = cache.get(svcName);
return i == null ? 0 : i;
}
@Override public int increment() throws CacheException {
return cache.invoke(svcName, new CounterEntryProcessor());
}
/**
* Entry processor which atomically increments value currently stored in cache.
*/
private static class CounterEntryProcessor implements EntryProcessor {
@Override public Integer process(MutableEntry e, Object... args) {
int newVal = e.exists() ? e.getValue() + 1 : 1;
// Update cache.
e.setValue(newVal);
return newVal;
}
}
} - 配置服务节点过滤器并注册服务
public class ServiceNodeFilter implements IgnitePredicate{
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("service.node");
return dataNode != null && dataNode;
}
}
- 调用服务
@GetMapping("/test1")
public String test1() {
//分布式计算如果不指定集群组的话则会传播到所有节点
IgniteCompute compute = ignite.compute(ignite.cluster().forAttribute("service.node", true));
// IgniteCompute compute = ignite.compute(); //未部署服务的节点会抛出空指针
compute.run(new IgniteRunnable() {
@ServiceResource(serviceName = "myCounterService", proxySticky = false) //非粘性代理
private MyCounterService counterService;
@Override
public void run() {
int newValue = counterService.increment();
System.out.println("Incremented value : " + newValue);
}
});
return "all executed.";
}分布式计算默认会传播到集群中的所有节点,如果某个节点没有部署相关服务,则调此服务负载均衡到该节点的时候会报空指针异常,因为该节点找不到此服务。针对此情景有两种解决办法:
1.获取分布式计算对象的时候过滤节点,则计算只会传播到过滤后的节点上
ignite.compute(ignite.cluster().forAttribute("service.node", true))2.设置粘性代理
如果代理是粘性的,Ignite会总是访问同一个集群节点的服务,如果代理是非粘性的,那么Ignite会在服务部署的所有集群节点内对远程服务代理的调用进行负载平衡。
服务网格故障转移
只有在分布式计算中使用服务网格调用才能实现服务调用故障转移
所谓故障转移,也就是服务调用过程中节点宕机,这时候会在其它节点继续执行。另外,如果服务是集群单例的话,那么如果节点宕机,首先发生的是服务的故障转移,这个时候分布式计算的故障转移会出错,因为其它节点的服务不一定会已经初始化成功。所以如果要保证服务调用能故障转移,最好在服务部署的时候保证服务是集群内有多个实例,并且在不同的节点,这样在节点故障的时候进行服务调用可以进行故障转移。
分布式计算中使用服务网格(可以故障转移):
IgniteCompute compute = ignite.compute(ignite.cluster().forServers());
compute.run(new IgniteRunnable() {
@ServiceResource(serviceName = "simpleMapService", proxyInterface = SimpleMapService.class, proxySticky = true)
private SimpleMapService simpleMapService;
@Override
public void run() {
if (simpleMapService != null) {
Object ret = simpleMapService.get("sleep");
} else {
System.out.println("simpleMapService is null");
}
}
});正常调用服务网格(无法故障转移):
Ignite ignite = Ignition.ignite();
IgniteServices svcs = ignite.services(ignite.cluster().forRemotes());
//非粘性,负载均衡
SimpleMapService sms = svcs.serviceProxy("simpleMapService", SimpleMapService.class, false);
Object ret = sms.get("sleep");数据节点
ignite节点可以配置成server模式或者client模式,主要区别在于client模式无法存储数据,而server能存储数据,但是无法更细粒度控制数据,比如控制数据在某部分节点上存储。通过节点过滤器可以实现集群中划分部分节点作为某缓存的节点。
注意:如果一个节点本身是client模式,那么即使这个节点配置成了数据节点,它也是无法存储数据的。
1,实现数据节点过滤器
public class DataNodeFilter implements IgnitePredicate{
public boolean apply(ClusterNode node) {
Boolean dataNode = node.attribute("data.node");
return dataNode != null && dataNode;
}
} 该过滤器通过检查节点属性中是否含有data.node==true的过滤标志来确定该节点是否会被当做数据节点。
过滤器的实现类需要放到每个节点的classpath路径下,不管该节点是否会成为数据节点。
2,缓存配置中添加过滤器
java.lang.Long
org.cord.ignite.data.domain.Student
这个过滤器会在缓存启动时调用,它会定义一个要存储缓存数据的集群节点的子集--数据节点。同样的过滤器在网络拓扑发生变化时也会被调用,比如新节点加入集群或者旧节点离开集群。3,为需要作为数据节点的节点添加过滤标志属性
示例:启动两个节点,其中一个cache配置了过滤器,并且只有一个节点添加了过滤标志,最后数据的存储状态如下:
visor> cache
Time of the snapshot: 11/14/18, 21:57:06
+=========================================================================
| Name(@) | Mode | Nodes | Entries (Heap / Off-heap) |
+=========================================================================
| myCounterCache(@c0) | REPLICATED | 2 | min: 0 (0 / 0) |
| | | | avg: 0.50 (0.00 / 0.50) |
| | | | max: 1 (0 / 1) |
+---------------------+------------+-------+-----------------------------+
| student(@c1) | REPLICATED | 1 | min: 500 (0 / 500) |
| | | | avg: 500.00 (0.00 / 500.00) |
| | | | max: 500 (0 / 500) |
+-------------------------------------------------------------------------可见student缓存只分布在一个节点上了,并没有像普通情况一样发生数据的再平衡,说明节点的过滤器起作用了。
通过节点过滤器,可以将数据节点和服务节点进行分离,因为部署新服务需要部署新的服务相关的包,涉及到重启之类的,这样便于维护。另外,通过部署一系列的服务,这就形成了一套微服务的解决方案,而且不用考虑负载均衡和容错处理,这些ignite都会处理,我们需要做的就是实现服务并将服务部署到ignite集群,就能实现服务的拆分,和服务的治理,达到微服务的效果。
附:
完整代码参考 https://github.com/cording/ignite-example