tensorflow笔记__学习率的设置
learning_rate:
学习率设置大了震荡不收敛,设置小了,收敛速度太慢,时间成本高.
下面我们使用tensorflow设置损失函数为 y=(w+1)^2, 初始w=5, 更改学习率看一下loss值输出的变化情况, 显然,我们知道最优的值w=-1
code:
#coding:utf-8 """设置损失函数为 loss = (w+1)^2 令w的初值为常数5,反向传播就是求最优的w,即求最小的loss对应的w值""" import tensorflow as tf # 定义待优化变了w,赋初值5 w = tf.Variable(tf.constant(5,dtype=tf.float32)) #定义损失函数loss loss = tf.square(w+1) #定义反向传播算法 train_step = tf.train.GradientDescentOptimizer(0.01).minimize(loss) with tf.Session() as sess: # 初始化所有变量 init_op = tf.global_variables_initializer() sess.run(init_op) # 设置训练轮数为40 for i in range(40): sess.run(train_step) w_val = sess.run(w) loss_val = sess.run(loss) # 输出最后查看结果 print("After {} steps: w is {}, loss is {}.".format(i,w_val,loss_val))
测试: 下面设置将学习率设置为1或者0.01看看输出变化.
① 设置为学习率1(过大)时, 震荡不收敛,loss值比较大
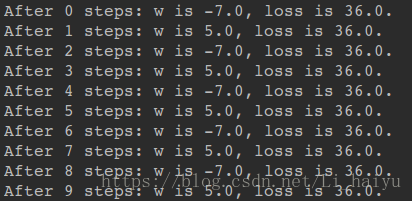
② 设置学习率为0.01(过小),训练40次之后w不能收敛到-1,loss值仍然比较高
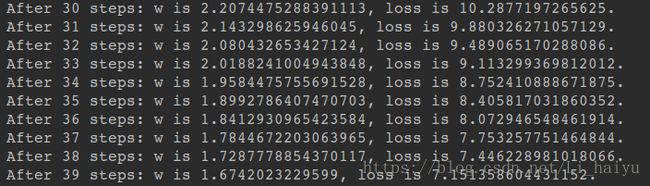
指数衰减学习率:
刚才我们看到衰减率的设置还是个比较难搞的事情,那么指数衰减学习率提供了一种学习率随着训练轮数动态更新的功能,我们希望刚开始训练的时候学习率大一些,训练到后面学习率就慢慢减小到一个较小的值.
指数衰减学习率的设置也比较简单,主要参数有下面几个:
① LEARNING_RATE_BASE # 学习率初始值
② global_step = tf.Variable(0,trainable = False) # 设置训练轮数初始值,不可训练
③ LEARNING_RATE_STEP # 学习率更新频率,一般设置为 样本总数/BATCH_SIZE
④ LEARNING_RATE_DECAY # 设置学习率衰减率
④ staircase # True/False, 设置学习率阶梯型下降(True)或者平滑下降(False)
学习率更新公式:
learning_rate = LEARNING_RATE_BASE*LEARNING_RATE_DECAY*(global_step/LEARNING_RATE_BASE_SIZE)
tensorflow函数表示如下:
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
下面再看一下前面的例子使用指数衰减学习率训练代码:
code:
import tensorflow as tf LEARNING_RATE_BASE = 0.1 # 设置初始学习率为0.1 LEARNING_RATE_DECAY = 0.99 # 设置学习衰减率为0.99 LEARNING_RATE_STEP = 1 # 设置喂入多少轮BATCH_SIZE之后更新一次学习率,一般设置为 总样本数/BATCH_SIZE global_step = tf.Variable(0,trainable = False) # 只需要这一行代码即可 learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True) w = tf.Variable(tf.constant(5,dtype=tf.float32)) loss = tf.square(w+1) # 优化函数中使用前面定义好的指数衰减学习率 train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss,global_step=global_step) with tf.Session() as sess: # 初始化变量 init_op = tf.global_variables_initializer() sess.run(init_op) # 设置训练轮数,开始训练 for i in range(40): sess.run(train_step) learning_rate_val = sess.run(learning_rate) global_step_val = sess.run(global_step) w_val = sess.run(w) loss_val = sess.run(loss) print("After {} steps:global_step is {},w is {},learning_rate is {} and loss is {}".format(i,global_step_val,w_val,learning_rate_val,loss_val))
output:

可以看到最终的w是已经很接近-1的,loss也趋于0.
The end.