VIO当中的预计分 《On-manifold preintegration for real-time visual-inertial Odometry》
该博客是关于VIO当中预计分的知识。同时结合高翔博士的讲解PPT以及原文章。我刚开始也看不是很懂,然后不断的查各种知识甚至原文中的各种英文术语,然后先理解术语是什么意思,再将其与该论文中的应用场景对应,其中还选择择了高翔博士的《视觉SLAM十四讲作为参考资料》。
预备知识—李群李代数
李群李代数的知识参考了《视觉SLAM十四讲》以及预计分论文的前面部分。SO(3)特殊正交群也就是由三维旋转矩阵构成。SE(3)特殊欧式群也就是变换矩阵构成。个人的理解:群呢,就是集合了旋转变化矩阵的一个大集合,这个集合里面的元素都满足一些基本的性质。因为在SLAM中经常会涉及到旋转变换的求解,所以使用群以及其对应的代数形式就能很好的表示旋转变化啦!(主要就是积分微分啥的这些操作方便啦。)
当然用李群李代数不止是微分积分啥的方便,还有一点就是流形空间下更能很好的表示一些抽象的概念(比如SE(3)流形空间等)。所谓的流形空间,参考知乎流形学习.
嗯,以上是我个人的瞎扯,要是扯的不对的地方,请大神赐教!
李代数是指在李群的正切空间上的数(应该是向量)啦!至于正切空间,也就是李群中旋转矩阵的导数空间啦!旋转矩阵求导也就相当于左乘一个李代数上的数(向量),公式如下:
其实上面的公式就表达了
这个描述了R在局部的导数关系(在原点附近或者在某一个位置附近).
这个值 和R通过指数关系联系在了一起,其实R所对应的这个值就是李群(三维旋转矩阵)对应相应的李代数(特殊欧式群),所以两者之间的转换就变成了指数/对数映射。如下图所示。

知道了李代数上的这个值,就可以通过指数变化求出旋转矩阵,知道了旋转矩阵,通过对数映射也能求出相对应的李代数上的值。需要注意的是李群和李代数之间的关系是满射关系,也就是SO(3)对应的李代数中可能会有多个值,因此将旋转范围定在了[-pi,pi]之间。
李群和李代数之间的转换可以使用如下的图来形象的表示:

写到这儿,我自己怀疑了自己,有以下疑问:
李群代表的就是旋转变化矩阵,李代数指的是群的导数性质,也就是在正切空间上。那么计算的时候是将结果转成李代数来计算吗?这样是更方便一些吗?这样的转换是在什么时候进行转换呢?传感器的状态变量也是使用李代数来表示吗?由:

在预计分这篇论文里面在预备知识部分还讲了一些其它的预备知识,目前这部分还没看,包括用SO(3)来描述不确定性,在流形空间上用高斯牛顿方法之类的。这部分有时间还是需要再看看。
核心部分—预计分
引用以下别人的话
VIO,或VI-SLAM,是指利用视觉(Vision)加上惯导(Inertial),共同实现视觉里程计(Odometry)或完整SLAM的做法。我们知道,纯视觉可以实现三维空间中的定位,但由于图像可靠性不好,存在一些不可避免的问题:运动模糊、遮挡、快速运动、纯旋转、尺度不确定性,等等。许多问题,在纯视觉的SLAM中,难以得到根本上的解决。而IMU,可以得到与视觉无关的,关于运动主体自身的角速度、加速度的测量数据,从而对运动有一个约束。然而,从IMU数据到六自由度的空间位姿,还隔着一个动力学方程。同时,IMU数据,除了受白噪声影响之外,通常认为还存在一个零偏。仅用IMU来做位姿估计,由于零偏的影响,很快就会漂移。然而,视觉图像在固定不动时,并不会产生漂移。所以,利用视觉确定IMU的零偏,同IMU来辅助快速运动的定位和纯旋转的处理,成为VIO比较吸引人的研究点之一。
the state
但是由于IMU和camera的采样时间不同,还与基于关键帧的SLAM中构建关键帧的时间也不同,所以在这过程中就需要对IMU和camera的数据进行处理(预计分是只针对IMU还是会针对非key-frame的图像呢?从下图看好像是只对IMU数据部分预计分,然后每次都预计分两个key-frame之间的IMU数据,然后用其来纠正key-frame的状态信息?)设备的采样时间对比:
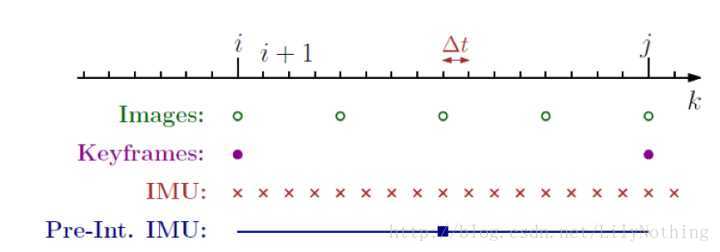
如上图所示。在时间轴上,IMU通常以较快的速率采集角速度和加速度的信息,而视觉则是以较慢的频率采集图像。VIO的器件同步,保证了每个时刻采集的数据都是同步的。原理上,我们可以给出每个时刻的位姿估计,然而,现有视觉SLAM,多数是基于关键帧+BA的处理形式。于是,一个重要的问题是,能否将两个视觉关键帧当中的IMU数据,整合在一起,约束它们之间的运动?这里的约束它们之间的运动,指的是什么呢?指的是两个视觉上的key-frame吗?如果可以的话,又如何来约束?预积分的目的,就在于处理这里的运动关系什么的运动关系?IMU和key-frame之间的吗?。为了说清楚这件事,需要介绍一些背景知识。
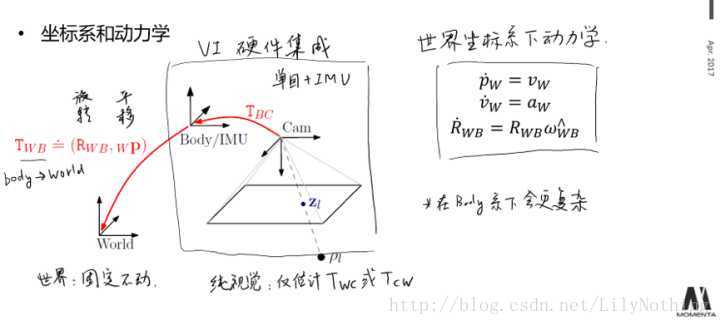

用IMU的测量数据来表示系统时刻i的state,可以如下表示:

其中bias又包含陀螺仪和加速度的bias,state中的每一个变量都是李代数中的R^3的表示方式,所以总的state有15维。
对于关键帧的state,用以下的方式表示:

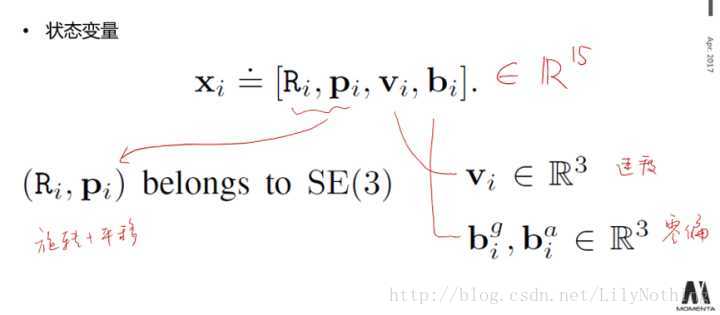
计算问题(estimation problem)的输入
也就是我们要实现localization的话我们需要的measurement有IMU和摄像头的图像输入。

C表示图像输入,在key-frame i处的输入包含一系列的图片,这些图片可能拍摄到l的landmark(这个地方的images会包含全部i到j之间的图像吗?还是会包含i时刻之前的图像呢?)。I表示第i个关键帧和第j个关键帧之间的IMU数据。这些landmark只是会对应到图像中的特征点之类的,这样landmark就可以和位置进行约束了(重投影误差约束)。
因子图(factor graph)和 最大后验估计(MAP)
其实估计问题就可以看成是MAP的问题。也就是在input的基础上估计处最好的state。
对应的公式如下图:
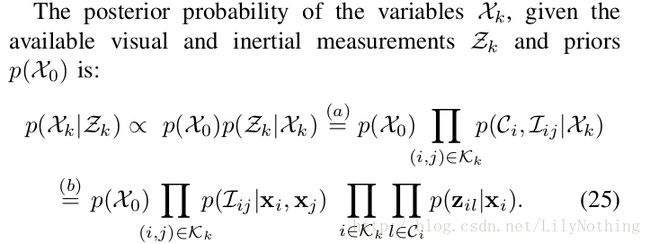
知道初始时刻的状态,那么也就可以得出相对应的MAP的公式了。其中a代表因式分解,b代表独立分布的假设成立,根据Markovian性质得到(这一刻的状态只受上一时刻影响)。因为Zk是已知的,那么就可以把其表示为因子图,因子图就可以用相应的方法进行求解了。转换过程如下:
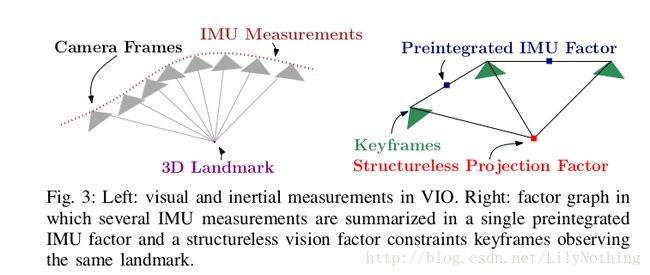
上图也标出来了预计分的部分。
MAP最大化(25)公式中的值,也就转换为最小化相对应的log值。

这样表示之后其实之后的计算也就是要尽可能的减少这个函数的值。这个函数是一个关于测量值和预测值之间的残差以及协方差的函数。也就是能反映系统的状态X。
IMU模型和运动的整合
IMU测出来的角速度和加速度是收到bias和noise影响的。所以测量值等于真实值加上相应的噪声和偏差。
其中的bias是state中的一个变量。加速度涉及到的旋转,偏差也是state中的变量。

那么目的就是从这些测量值中推出IMU的运动模型出来。首先引出动力学的积分模型:

因为导数就是代表了这个方向上的增量,所以在这个时候可以使用积分方式表示,剩下的速度和位移和物理上有些关系而已。在假设a和w都在一定时间内是不变的话,那么就可以写成上图右边的离散形式,接着用IMU的数据去替换掉离散形式的表达之后,就可以得到如上图右下部分表达的公式了。
于是,这个公式就可以表示两个视觉帧之间的约束关系了。进一步的,把两个key-frame之间的IMU的数据进行积分起来,那么就可以表示两个关键帧之间的约束关系了。



这里的构建优化函数是如何构建的呢?两个关键帧的误差量通过IMU数据可以表达,也可以通过视觉的方式进行表达?两个表达的L2吗?视觉的方式如何表达呢?非key-frame之间的方式如何表达呢?同key-frame一样吗?这个根据自己的要求,自己定义关键帧,看关键帧之间


上图解决了上述的视觉表达(key-frame之间的表达方式。)但是两个视觉帧(非关键帧之间的表达方式呢?)
然后,还需讨论观测量对零偏的雅可比:

至此,除了细节推导之外,我们已经说明了预积分的主要思路。那么,如何在VIO里应用预积分呢?实际上也不难,只要把原先视觉SLAM里的bundle adjustment里,用15维的Pose代替原先6维的Pose,再加上IMU运动约束即可。

在ORB+IMU、LSD+IMU的工作中,作者们都是利用了这个框架实现VIO或VI-SLAM的:

不过,由于预积分原先是在gtsam上开源的,所以作者们也都用了gtsam作为后端。然而,只要清楚了预积分的原理,那么在g2o或ceres这些通用优化框架中,也完全可以实现预积分的计算。这就给出了一种基于优化方法的VIO处理方式。
结语:以上内容应该是自己对高博讲解的笔记吧,很多图片都是来自于高博的PPT,原链接也在开始就给出来了,一些问题我也在文中提出来了,之后再去问问学长之后再来完善这部分内容。
参考:http://www.tk4479.net/qq_26682225/article/details/72649858
参考:https://zhuanlan.zhihu.com/p/26243851
这篇预计分的论文里是所有VIO的基础,其中是结合ORB_SLAM加这篇文章里面的预积分实现的VIO,具体的代码没有开源,但是大疆的一个人进行了实现,github地址:https://github.com/jingpang/LearnVIORB,,但是他只实现了单目的. 而且似乎双目比VINS-MONO(单目+imu)效果要好一些.