深入理解人工神经网络——从原理到实现
王琦 QQ:451165431 计算机视觉&深度学习
转载请注明出处 :http://blog.csdn.net/Rainbow0210/article/details/78396755。
本篇通过在MNIST上的实验,引出神经网络相关问题,详细阐释其原理以及常用技巧、调参方法。欢迎讨论相关技术&学术问题,但谢绝拿来主义。
代码是博主自己写的,因为倾向于详细阐述底层原理,所以没有用TensorFlow等主流DL框架。实验结果与TF等框架可能稍有不同,其原因在于权重初始化方式的差异等,但并不影响对于网络的本质的理解。
此外,值得注意的是博主在一年多前写的关于DBN的博客:
http://blog.csdn.net/rainbow0210/article/details/53010694
在本次实验中,也证明了使用 Relu 作为激活函数时可以达到 Sigmoid+DBN 近乎相同的性能。DBN所解决的是深度网络的参数初始化的问题,在传统激活函数中(Sigmoid系),随着网络权值的更新,会有相当一部分节点的值分布在激活函数值域的两侧,导致其梯度近乎为零,使得网络难以更新,即“梯度消亡”。而通过 DBN 去初始化网络权重,再 fine-tuning,可以很大程度上解决这个问题。但实际上,利用 Relu 激活函数替代 Sigmoid 可以更本质地解决这个问题。这也是为什么如今即便是很深的网络,也可以直接进行训练的原因(有足够多的训练样本)。
实验概述
数据集
- MNIST:0-9共10个数字,其中,60000条训练样本,10000条测试样本,每条样本分辨率为 28×28 。拉伸为 1 维向量,因而为 28×28=784 维。
实验平台
- Python 2.7
实验内容
通过MLP完成对MNIST数据集的分类。具体有需要实现一下三部分:
- 全连接层:实现并比较1层隐层的 MLP 与2层隐层的MLP的性能差异
- 激活函数:实现并比较 Relu 和 Sigmoid 两种激活函数的性能差异
- 损失函数:实现 EuclideanLoss
实验原理

上图是一个典型的包含两个隐层的MLP,其中,每个圆圈代表一个神经元,且每个神经元模型包含一个可微的非线性激活函数(如Sigmoid);每两个神经元之间的连线具有一个权值 w ,且每个神经元具有一个偏置值 b 。 w 和 b 这两个值可以使得网络层与层之间产生映射关系,而激活函数则可以使得这种映射具有非线性,从而可以得到更复杂的输入与输出之间的映射表达。
MLP的训练往往基于反向传播算法,这也是本次试验的重点。其中,包含如下两个阶段
- 前向传播:网络参数( w 和 b )固定,输入信号在网络中一层一层传播(图中对应于自下向上),直到输出端。
- 反向传播:通过比较网络的输出信号和期望的输出信号所差生的一个误差信号( loss ),该误差信号通过网络一层一层传播(图中对应于自上向下),网络参数( w 和 b )通过计算梯度不断修正,使得 loss 逐渐收敛于局部极小值,即误差信号逐步减小。
前向传播(Forward)
记第 k 层神经元第 k+1 层神经元与之间的权值为 W(k,k+1) ,其中, k=0,1 , 第 k 层神经元的偏置值为 b(k) , x 为输出信号,是一个 n 维的向量。则激活前,第一个隐层的输出值 u(1) 为:
注意到
所以,可以将 x 和 W 作相应的增广,达到简化的效果(以下皆讨论增广后的表达):
激活后,第一个隐层的输出值 y(1) 为:
其中, σ(⋅) 为激活函数,本次实验中为 Relu 函数或者 Sigmoid 函数, 其原函数及其导数可以表示为:
类似地,第二个隐层的输出值 y(2) 和输出层的输出值 y(3) 可以表示为:
至此,即完成了前向传播的过程,我们通过网络的输入信号 x 得到了其相应的输出信号 y(3) ,简记为 y 。
反向传播(Backward)
在进行反向传播之前,我们需要定义误差信号,即损失函数( loss ),在本次实验中为 EuclideanLoss。记真实概率分布(即标签)为 y¯ ,则 EuclideanLoss 可以表示为:
欲更新权重系数,使得 达到极小值,则需要求 对 W(t,t+1) 的偏导,其中 t=0,1,2 。
对于输出层,由于其存在一个期望响应,即 y¯ , 所以可以直接通过损失函数结合链式法则求得偏导;但对于隐藏层,由于不存在期望相响应,所以隐藏层的误差信号要根据所有与隐藏层神经元相连的神经元的损失来向后递归求得,也就是根据损失函数从输出层逐步递归求得偏导。下面分别介绍对于输出层和隐藏层的权值更新方式。其中, w(t,t+1)i,j 表示第 t 层的第 i 个神经元和第 t+1 层的第 j 个神经元之间的连接的权值,其余变量定义同上,下标表示神经元的位置。
输出层
注意到:
所以:
则修正量 Δw(2,3)i,j 为:
其中,负号意味着在权空间中梯度下降。定义局部梯度 δ(3)j :
则:
其中, η 是学习速率,最终权重更新可以表示为:
隐藏层
其中后两项的偏导是与输出层完全类似的:
对于 ∂∂y(2)j ,由于 y(2)j 并不存在期望响应,所以需要通过链式法则来求偏导:
注意到:
所以:
进而有:
则修正量 Δw(1,2)i,j 为:
其中,负号意味着在权空间中梯度下降。定义局部梯度 δ(2)j :
则:
其中, η 是学习速率,最终权重更新可以表示为:
学习速率( Learning Rate )
通过网络训练的逐步迭代,反向传播算法可以得到在权空间中基于最速下降的轨迹的近似,所以,学习速率 η 越小,这种轨迹也就越平滑,网络权值的变化量也就越小,但是相应的训练回合( epoch )也会随之增加。反之,如果学习速率 η 越大,则有可能导致网络的权值的变化量过大,从而发生震荡现象,网络不能够收敛。所以,学习速率的选取在网络训练的过程中是十分重要的。
动量( Momentom )
一个既能加快学习速度,又能保证网络的稳定性的一个简单的方法就是为修正量增加动量项:
其中,每一项后面的括号(即(n)和(n-1))表示在第n个回合( epoch )的修正量, α 称为动量常数,一般在 [0,1) 的区间内。
权值衰减( Weight Decay )
在极为有限的训练样本以及大量的网络参数的情况下,网络的训练非常容易发生过拟合的现象,导致泛化能力降低,而权值衰减可以一定程度地避免过拟合的发生。其通常的做法是在损失函数中加上 l2 正则项:
其中, λ 为衰减系数。此时,修正量相应为:
代码实现
损失函数( EuclideanLoss )
class EuclideanLoss(object):
def __init__(self, name):
self.name = name
def forward(self, input, target):
return 0.5 * np.mean(np.sum(np.square(input - target), axis=1))
def backward(self, input, target):
return (input - target) / len(input)全连接层
class Linear(Layer):
def __init__(self, name, in_num, out_num, init_std):
super(Linear, self).__init__(name, trainable=True)
self.in_num = in_num
self.out_num = out_num
self.W = np.random.randn(in_num, out_num) * init_std
self.b = np.zeros(out_num)
self.grad_W = np.zeros((in_num, out_num))
self.grad_b = np.zeros(out_num)
self.diff_W = np.zeros((in_num, out_num))
self.diff_b = np.zeros(out_num)
def forward(self, input):
self._saved_for_backward(input)
output = np.dot(input, self.W) + self.b
return output
def backward(self, grad_output):
input = self._saved_tensor
self.grad_W = np.dot(input.T, grad_output)
self.grad_b = np.sum(grad_output, axis=0)
return np.dot(grad_output, self.W.T)
def update(self, config):
mm = config['momentum']
lr = config['learning_rate']
wd = config['weight_decay']
self.diff_W = mm * self.diff_W + (self.grad_W + wd * self.W)
self.W = self.W - lr * self.diff_W
self.diff_b = mm * self.diff_b + (self.grad_b + wd * self.b)
self.b = self.b - lr * self.diff_b
激活函数
Relu:
class Relu(Layer):
def __init__(self, name):
super(Relu, self).__init__(name)
def forward(self, input):
self._saved_for_backward(input)
return np.maximum(0, input)
def backward(self, grad_output):
input = self._saved_tensor
return grad_output * (input > 0)Sigmoid:
class Sigmoid(Layer):
def __init__(self, name):
super(Sigmoid, self).__init__(name)
def forward(self, input):
output = 1 / (1 + np.exp(-input))
self._saved_for_backward(output)
return output
def backward(self, grad_output):
output = self._saved_tensor
return grad_output * output * (1 - output)实验结果
学习速率
将网络层数固定为 1 层,节点数为 512 ,激活函数为 Relu,动量为 0.9 ,权值衰减为 0.0005 , 迭代数( epoch )为 100 。探究学习速率对于模型性能的影响。实验数据如下表:
| 学习速率 | 训练集loss | 训练集accuracy | 测试集loss | 测试集accuracy |
|---|---|---|---|---|
| 0.01 | 0.0139 | 99.29 | 0.0213 | 98.47 |
| 0.005 | 0.0156 | 99.15 | 0.0222 | 98.28 |
| 0.001 | 0.0300 | 97.81 | 0.0222 | 97.36 |
相应的三个实验的函数曲线:

从图表中可以看出,随着学习速率的减小,网络的学习过程更加平稳,曲线更加光滑,但是,网络的收敛速度也会相应减小,需要训练的epoch数会变多。
激活函数
将网络层数固定为 1 层,节点数为 512 ,学习速率为 0.01 ,动量为 0.9 ,权值衰减为 0.0005 , 迭代数( epoch )为 100 。探究激活函数对于模型性能的影响。实验数据如下表:
| 激活函数 | 训练集loss | 训练集accuracy | 测试集loss | 测试集accuracy |
|---|---|---|---|---|
| Relu | 0.0139 | 99.29 | 0.0213 | 98.47 |
| Sigmoid | 0.0697 | 94.47 | 0.0704 | 94.14 |
相应的两个实验的函数曲线:

从图表中可以看出,相比于 Relu 作为激活函数,Sigmoid 作为激活函数时,网络的收敛速度更慢,性能也相对变差。这是因为当 Sigmoid 作为激活函数时,会有部分神经元达到“饱和”的状态:其值分布在 Sigmoid 函数的值域(即(0,1))的两端,梯度近乎为0,导致其值难以更新。但是 Relu 作为激活函数时则不会出现这种情况。
动量
将网络层数固定为 1 层,节点数为 512 ,激活函数为 Relu,学习速率为 0.01 ,权值衰减为 0.0005 , 迭代数( epoch )为 100 。探究动量参数对于模型性能的影响。实验数据如下表:
| 动量参数 | 训练集loss | 训练集accuracy | 测试集loss | 测试集accuracy |
|---|---|---|---|---|
| 0.1 | 0.0262 | 97.95 | 0.0294 | 97.57 |
| 0.5 | 0.0195 | 98.72 | 0.0251 | 97.90 |
| 0.9 | 0.0139 | 99.29 | 0.0213 | 98.47 |
相应的三个实验的函数曲线:
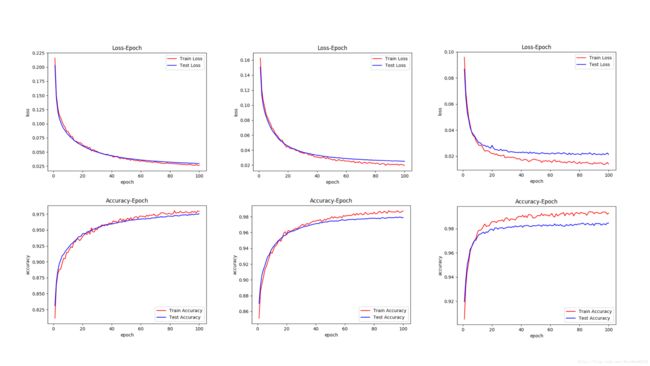
从图表中可以看出,适当增加动量参数的值可以加快网络的学习速度,但又不会使得网络震荡的太厉害,学习过程相对平稳。
权值衰减
将网络层数固定为 1 层,节点数为 512 ,激活函数为 Relu,学习速率为 0.01 ,动量为 0.9 , 迭代数( epoch )为 100 。探究权值衰减参数对于模型性能的影响。实验数据如下表:
| 权值衰减参数 | 训练集loss | 训练集accuracy | 测试集loss | 测试集accuracy |
|---|---|---|---|---|
| 0.001 | 0.0221 | 98.56 | 0.0254 | 98.00 |
| 0.0005 | 0.0139 | 99.29 | 0.0231 | 98.47 |
| 0.0001 | 0.0066 | 99.78 | 0.0188 | 98.67 |
| 0.00005 | 0.0062 | 99.67 | 0.0189 | 98.56 |
| 0.00001 | 0.0048 | 99.73 | 0.0186 | 98.55 |
| 0.000005 | 0.0051 | 99.64 | 0.0188 | 98.52 |
相应的六个实验的函数曲线:


从图表中可以看出,权值衰减系数不宜过大,当其小于 0.0005 时,其对实验结果几乎没有什么影响。
网络层数
单隐层网络节点数固定为 512 ,双隐层网络节点数固定为 512,128 ,激活函数为 Relu/Sigmoid,学习速率为 0.01 ,动量为 0.9 ,权值衰减为 0.0005 , 迭代数( epoch )为 100 。探究网络层数对于模型性能的影响。实验数据如下表:
| 网络层数 | 激活函数 | 训练集loss | 训练集accuracy | 测试集loss | 测试集accuracy |
|---|---|---|---|---|---|
| 1 | Relu | 0.0139 | 99.29 | 0.0231 | 98.47 |
| 2 | Relu | 0.0100 | 99.54 | 0.0169 | 98.62 |
| 1 | Sigmoid | 0.0697 | 94.47 | 0.0704 | 94.14 |
| 2 | Sigmoid | 0.0825 | 92.22 | 0.0781 | 92.87 |
相应的四个实验的函数曲线:
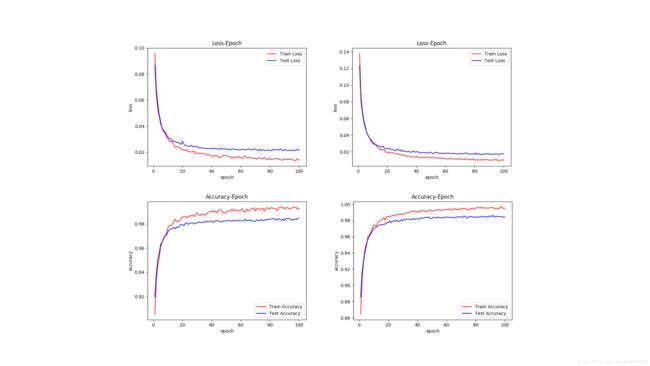

从图表中可以看出,相比于 Sigmoid,Relu作为激活函数时网络具有更好的性能。此外,双隐层的Sigmoid 训练难度很大,收敛速度极慢。而双隐层 Relu 网络相比于单隐层 Relu 网络具有更好的性能,这是因为多隐层可以更好地拟合高度非线性的分类面,从而使得模型具有更强的分类能力。