numpy学习笔记三:numpy文件读写与常用统计方法
在数据挖掘中,通常数据需要从文件中读取,与之类似的也可以把数据写入文件中,如:
i2 = np.eye(3)
print(i2)
np.savetxt('D:\eye.txt',i2)就是将i2的内容写入到了文件eye.txt中,eye()的作用是生成一个单位矩阵。生成的文件内容如下:
1.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
0.000000000000000000e+00 1.000000000000000000e+00 0.000000000000000000e+00
0.000000000000000000e+00 0.000000000000000000e+00 1.000000000000000000e+00
AAPL,28-01-2011, ,344.17,344.4,333.53,336.1,21144800
AAPL,31-01-2011, ,335.8,340.04,334.3,339.32,13473000
AAPL,01-02-2011, ,341.3,345.65,340.98,345.03,15236800
AAPL,02-02-2011, ,344.45,345.25,343.55,344.32,9242600
AAPL,03-02-2011, ,343.8,344.24,338.55,343.44,14064100
AAPL,04-02-2011, ,343.61,346.7,343.51,346.5,11494200
AAPL,07-02-2011, ,347.89,353.25,347.64,351.88,17322100
AAPL,08-02-2011, ,353.68,355.52,352.15,355.2,13608500
AAPL,09-02-2011, ,355.19,359,354.87,358.16,17240800
AAPL,10-02-2011, ,357.39,360,348,354.54,33162400
AAPL,11-02-2011, ,354.75,357.8,353.54,356.85,13127500
AAPL,14-02-2011, ,356.79,359.48,356.71,359.18,11086200
AAPL,15-02-2011, ,359.19,359.97,357.55,359.9,10149000
AAPL,16-02-2011, ,360.8,364.9,360.5,363.13,17184100
AAPL,17-02-2011, ,357.1,360.27,356.52,358.3,18949000
AAPL,18-02-2011, ,358.21,359.5,349.52,350.56,29144500
AAPL,22-02-2011, ,342.05,345.4,337.72,338.61,31162200
AAPL,23-02-2011, ,338.77,344.64,338.61,342.62,23994700
AAPL,24-02-2011, ,344.02,345.15,338.37,342.88,17853500
AAPL,25-02-2011, ,345.29,348.43,344.8,348.16,13572000
AAPL,28-02-2011, ,351.21,355.05,351.12,353.21,14395400
AAPL,01-03-2011, ,355.47,355.72,347.68,349.31,16290300
AAPL,02-03-2011, ,349.96,354.35,348.4,352.12,21521000
AAPL,03-03-2011, ,357.2,359.79,355.92,359.56,17885200
AAPL,04-03-2011, ,360.07,360.29,357.75,360,16188000
AAPL,07-03-2011, ,361.11,361.67,351.31,355.36,19504300
AAPL,08-03-2011, ,354.91,357.4,352.25,355.76,12718000
AAPL,09-03-2011, ,354.69,354.76,350.6,352.47,16192700
AAPL,10-03-2011, ,349.69,349.77,344.9,346.67,18138800
AAPL,11-03-2011, ,345.4,352.32,345,351.99,16824200
可以使用如下的方法:
c,v=np.loadtxt('d:/data.csv', delimiter=',', usecols=(6,7), unpack=True)
print(c)
print(v)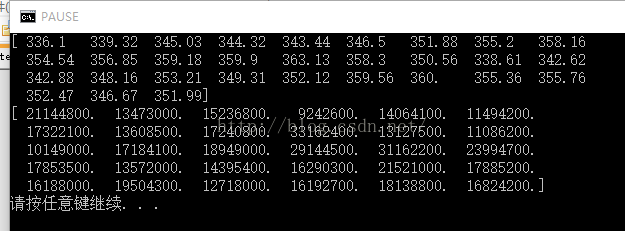
loadtxt中的参数分别是要读取的文件,分隔符,要读内容的列数和不同列的参数是否要拆分。
我们可以利用mean来求某一列的平均值:
a = np.mean(c)
print(a)当然在实际使用中还经常会用到加权平均值:
a = np.average(c, weights=v)也可以求数组中的最大,最小值:
max = np.max(c)
min = np.min(c)有时还需要取方差:
var = np.var(c)看文件中第二列,是一些日期数据,当希望对他们读取时需要进行一些处理,比如转换成周几:
def datestr2num(s):
s = str(s)
s = s[2:-1]
num = datetime.strptime(s, "%d-%m-%Y").date().weekday()
return str(num)
c,v=np.loadtxt('d:/data.csv', delimiter=',', usecols=(1,7), converters={1:
datestr2num}, unpack=True)
print(c)其中datestr2num用来将xx-xx-xxxx格式的日期转化为周几,由于在python3中改变了字符串的存储方式因此需要先进行一次格式转换。