SiamRPN++算法详解
论文题目:SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
论文链接:论文链接
论文代码:后续会开源
目录
- 一、SiamRPN和DaSiamRPN算法回顾
- 1、SiamRPN
- 2、DaSiamRPN
- 二、SiamRPN++细节详解
- 1、论文动机
- 2、 创新点1-缓解平移不变性问题
- 2.1 、由Siamese-fc中可以获得的网络限制条件是什么?
- 2.2、 针对以上问题进行的分析和总结
- 2.3、如果破坏了网络的平移不变性,具体会带来什么问题呢?
- 2.4、 实验验证猜想
- 2.5、为什么该问题在检测任务和语义分割任务中并不存在?
- 3、创新点2-使用深层网络
- 4、创新点3-多层特征融合
- 5、创新点4-Depthwise Cross Correlation
- 6、创新点5-在多层使用siamrpn
- 三、SiamRPN++实验结果
- 四、个人感悟与总结
- 4.1、 个人感悟
- 4.2、个人总结
- 注意事项
- 参考资料
一、SiamRPN和DaSiamRPN算法回顾
1、SiamRPN
- 基于SiamFC, 引入了Faster RCNN中的RPN模块,让tracker可以回归位置、形状,可以省掉多尺度测试,提高算法性能的同时算法的跟踪速度;
- 使用更大的数据集VID和Youtube-BB来进行跟踪网络的训练;

- correlation操作详解(涉及到后续改进):以分类分支为例,在RPN中,分类分支需要输出一个通道数为 2k 的特征图( k 为anchor个数),SiamFC中使用的correlation只能提供通道数为1的响应图,无法满足要求。所以我们换了一个想法,把correlation层当成一个卷积层,template分支提取的特征作为卷积核,detection分支提取的特征作为卷积层的input,这样只需要改变卷积核的形状就可以达到输出2k通道数的目的。具体做法为使用了两个不同的卷积层,template分支的卷积层负责升维,把通道数提升到 256*2k ,为了保持对齐,detection分支也增加了一个卷积层,不过保持通道数不变。之后进行correlation操作(卷积),得到最终的分类结果。
2、DaSiamRPN
- 基于SiamRPN,主要针对训练数据集,丰富样本的个数和种类,利用更好的训练方式让tracker变得更加鲁棒;
- 针对long-term跟踪问题,提出了局部到全局的思路。
二、SiamRPN++细节详解
1、论文动机
该论文主要解决的问题是将深层基准网络ResNet、Inception等网络应用到基于孪生网络的跟踪网络中。在SiameseFC算法之后,尽管已经有很多的基于孪生网络的跟踪算法,但是大家可能会注意到一个问题是,这些网络都使用浅层的类AlexNet做为基准特征提取器。其实在这之前,也有学者们尝试着使用深层的网络,但是发现直接使用预训练好的深层网络反而会导致跟踪算法精度的下降,因此,这成为了一个基于孪生网络的跟踪器需要解决的一个关键问题!
2、 创新点1-缓解平移不变性问题
2.1 、由Siamese-fc中可以获得的网络限制条件是什么?
siamese-fc中的相关操作可以看成是按照滑窗的形式计算每个位置的相似度,这就会带来两个具体的限制:
- 网络需要满足严格的平移不变性。如SiamFC中介绍的,padding会破坏这种性质;
- 网络具有对称性,即如果将搜索区域图像和模板区域图像进行互换,输出的结果应该保持不变。(因为是相似度,所以应该有对称性)。
2.2、 针对以上问题进行的分析和总结
- 现代化网络:随着何铠明等提出残差网络以后,网络的深度得到了巨大的释放,通常物体检测和语义分割的baseline backbone都采用ResNet50的结构。为了保证网络具有适当/整齐的分辨率,几乎所有的现代网络backbone都需要执行padding操作。而ResNet网络中具有padding操作,即该网络肯定不具备严格的平移不变性,padding的引入会使得网络输出的响应对不同位置有了不同的认知。而我们进行进一步的训练是希望网络学习到如何通过物体的表观特征来分辨回归物体,这就限制了深网络在tracking领域的应用。
- 网络对称性:由于SiamRPN不再是进行相似度计算,而是通过计算回归的偏移量和分类的分数来选择最终的目标,这将使得该网络不再具有对称性。因而在SiamRPN的改进中需要引入非对称的部件,如果完全Siamese的话没法达到目的,这一点主要会引导后面的correlation设计。
2.3、如果破坏了网络的平移不变性,具体会带来什么问题呢?
如果现代化网络的平移不变性被破坏以后,带来的弊端就是会学习到位置偏见:按照SiamFC的训练方法,正样本都在正中心,网络逐渐会学习到这种统计特性,学到样本中正样本分布的情况。即简而言之,网络会给图像的中心位置分配更大的权重。具体的效果如下图所示:当我们将shift设置为0时,网络只会关注图像中心的位置,对应到图中就是只有中心位置具有较大的响应值;而当我们将shift设置为16时,网络开始关注更多的图像范围,对应到图中就是响应的范围会扩大,颜色由深变浅;而当我们将shift设置为32时,网络会关注更大额图像范围,对应到图中就是响应的范围变得更大,颜色也更加多样化。

2.4、 实验验证猜想
为了验证上述的猜测,文中设计了一个模拟实验。当我们像SiamFC一样训练,把正样本都放在图像中心时,网络只会对图像中心产生响应;如果我们把正样本均匀分布到某个范围内,而不是一直在中心时(所谓的范围即是指距离中心点一定距离,该距离为shift;正样本在这个范围内是均匀分布的),随着shift的不断增大,这种现象能够逐渐得到缓解。具体如下图所示:EAO是VOT比赛的一个评估指标,是将算法的鲁棒性和准确性结合起来的一个综合指标,该值越高表示算法越好。在下图中我们可以看到当shift从0变化到64的时候,跟踪算法在VOT16和VOT18数据集上面的效果都有了显著的性能提升,当shift超过64之后,提升的性能并不大,这可以从一方面说明该操作可以在一定程度上缓解上述这个问题。

具体的实施过程如下所示:
我们按照这个思想进行了实际的实验验证,在训练过程中,我们不再把正样本块放在图像正中心,而是按照均匀分布的采样方式让目标在中心点附近进行偏移。由上图可以看出,随着偏移的范围增大,深度网络可以由刚开始的完全没有效果逐渐变好。
所以说,通过均匀分布的采样方式让目标在中心点附近进行偏移,可以缓解网络因为破坏了严格平移不变性带来的影响,即消除了位置偏见,让现代化网络可以应用于跟踪算法中。
2.5、为什么该问题在检测任务和语义分割任务中并不存在?
因为对于物体检测和语义分割而言,训练过程中,物体本身就是在全图的每个位置较为均匀的分布。我们可以很容易的验证,如果在物体检测网络只训练标注在图像中心的样本,而边缘的样本都不进行训练,那么显然,这样训练的网络只会对图像的中心位置产生高响应,边缘位置就随缘了,不难想象这种时候边缘位置的性能显然会大幅衰减。而更为致命的是,按照SiamFC的训练方式,中心位置为正样本,边缘位置为负样本。那么网络只会记录下边缘永远为负,不管表观是什么样子了。这完全背离了我们训练的初衷。
3、创新点2-使用深层网络

我们主要的实验实在ResNet-50上做的。现代化网络一般都是stride32,但跟踪为了定位的准确性,一般stride都比较小(Siamese系列一般都为8),所以我们把ResNet最后两个block的stride去掉了,同时增加了dilated convolution,一是为了增加感受野,二是为了能利用上预训练参数。论文中提到的MobileNet等现代化网络也是进行了这样的改动。如上图所示,改过之后,后面三个block的分辨率就一致了。
在训练过程中采用了新的采样策略后,我们可以训练ResNet网络了,并且能够正常跟踪一些视频了。(之前跟踪过程中一直聚集在中心,根本无法正常跟踪目标)。对backbone进行finetune以后,又能够进一步得到一些性能提升。
4、创新点3-多层特征融合
如上图所示,由于深层网络中的层数比较多,网络的不同block块能够获取的特征也具有很大的差别,浅层网络特征更关注于提取一些颜色、边缘等信息,而深层网络特征则更关注于目标的语义特征,因此将深层网络的多层特征进行融合是一个值得去研究的工作。论文中选择了网络最后三个block的输出进行融合(由于之前对网络的改动,所以分辨率一致,融合时实现起来简单)。对于融合方式上我们并没有做过多的探究,而是直接做了线性加权。其实,如何做加权也是一个值得研究的事情,本文并没有在这里深究,这里可以进行更加深入的研究。

5、创新点4-Depthwise Cross Correlation

- Cross Correlation:如上图(a)所示,用于SiamFC中,模版特征在搜索区域上按照滑窗的方式获取不同位置的响应值,最终获得一个一维的响应映射图。
- Up-Channel Cross Correlation:如上图(b)所示,用于SiamRPN中,和Cross Correlation操作不同的是在做correlation操作之前多了两个卷积层,通道个数分别为256和256x2k,其中k表示每一个锚点上面的anchor个数。其中一个用来提升通道数,而另一个则保持不变。之后通过卷积的方式,得到最终的输出。通过控制升维的卷积来实现最终输出特征图的通道数。
- Depthwise Cross Correlation:如上图©所示,和UpChannel一样,在做correlation操作以前,模版和搜索分支会分别通过一个卷积层,但并不需要进行维度提升,这里只是为了提供一个非Siamese的特征(SiamRPN中与SiamFC不同,比如回归分支,是非对称的,因为输出不是一个响应值;需要模版分支和搜索分支关注不同的内容)。在这之后,通过类似depthwise卷积的方法,逐通道计算correlation结果,这样的好处是可以得到一个通道数非1的输出,可以在后面添加一个普通的 1x1卷积就可以得到分类和回归的结果。整个过程类似于构造检测网络的头网络。
- 这里的改进主要源自于upchannel的方法中,升维卷积参数量极大, 256x(256*2k)x3x3, 光分类分支就有接近6M的参数,回归分支12M。其次升维操作造成了两支参数量的极度不平衡,模版分支是搜索支参数量的 2k/4k 倍,造成了整个网络训练困难的问题。而改为Depthwise版本以后,参数量能够急剧下降;同时整体训练也更为稳定,整体性能也得到了加强。
6、创新点5-在多层使用siamrpn
如创新点2中的图所示,我们会观察到作者分别在conv3_3、conv4_6和conv5_3的分支上使用siamrpn网络,并将前面siamrpn的结果输入到后面的siamrpn网络中,该思路类似于cvpr2019值的C-RPN算法,通过多级级联具有两个优点:
- 可以通过多个siamrpn来选择出多样化的样本或者具有判别性的样本块,第一个siamrpn可以去除掉一些特别简单的样本块,而后面的网络进一步进行滤除,最终剩余一些hard negative sample,这样其实有利于提升网络的判别能力。
- 由于使用了多级回归操作,因此可以获得一个更加准确的BB。
三、SiamRPN++实验结果
为了验证本文提出的SiamRPN++的性能,我们在六个数据集上进行了实验。首先是比较重要的两个数据集,VOT和OTB,然后添加了UAV123,同时在两个比较大的数据集LaSOT,TrackingNet上也进行了实验。最后我们又将算法应用于longterm,在VOT18-LT上进行了实验。我们新提出的算法在这些数据集上都取得了非常好的效果。具体的效果如下所示:
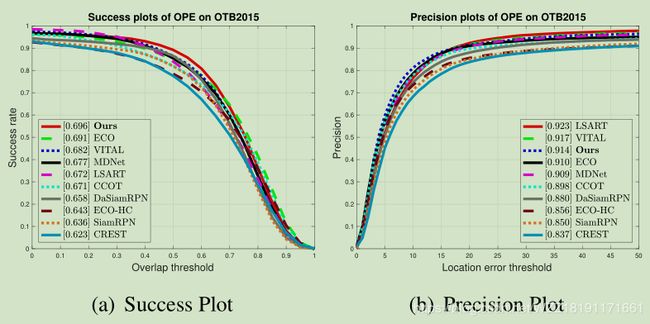
上图展示该算法在OTB15数据集上面的测试效果,我们可以观察到该算法在成功率上超过了ECO算法,而在精确率曲线上排名第三,主要的原因是该准确率的评估指标不是很好,仅仅通过中心点的位置来计算。

上图展示了该算法在VOT18数据集上面的测试结果,纵轴表示的是EAO,我们可以观察到该算法获得了最高的精度0.414,将第二名的LADCF算法拉开了较大的差距。

上图表示了该算法在VOT18-LT数据集上面的测试结果,所谓的long-term跟踪和普通的跟踪的不同之处在于,首先,该任务中的数据集的每一个视频具有更长的视频帧,一般超过2000帧;其次,待测试的跟踪算法需要具备检测待跟踪目标是否出现在图像中的能力。我们可以看到在这个新的任务上面该算法也获得了最好的成绩,大幅度超过了第二名的MBMD算法。

上图展示了该算法在UAV123数据集上面的测试效果,该数据集是用无人机拍摄的视频,具有不同的角度。我们可以看到该算法在该数据集中也获得了最好的成绩,远远超过了第二名的DaSiamRPN算法。

上图表示了该算法在一个新发布的跟踪数据集LaSOT上面的测试效果。我们可以观察到该算法同样取得了最好的成绩,并且和第二名的DaSiamRPN之间拉开了较大的差距。

上表展示了该算法在TrackingNet数据上的测试结果,我们可以观察到该算法同样获得了最好的成绩,在AUC、P等多个指标上面都远远超过了第二名的DaSiamRPN。

上表的主要目的是为了验证本文提出的每一个改进方案的有效性,具体包括使用不同的BackBone网络、是否使用网络层融合、是否进行网络微调操作、是否使用DW卷积等。具体的分析如下所示:
- 网络方面,从AlexNet换成了ResNet50以后,我们发现只有conv4的时候就取得了非常好的效果。虽然conv3和conv5效果没有那么好,但由于鲁棒性的提升,使得后续的提升变得有可能。同时对BackBone进行finetune也能带来接近两个点的提升。
- 多层特征融合,可以从图中看出,同时使用三支的效果明显比单支的要高,VOT上比最好的conv4还要高4个多点。
- 使用DW卷积,从表中也可以看出,无论是AlexNet还是ResNet,装备了新的correlation方式以后,都有接近两个点提升。
四、个人感悟与总结
4.1、 个人感悟
如果你一直在做视觉目标跟踪,你一定会感觉这篇文章真的很厉害,不愧CVPR2019的Oral。也许你也会有一种感觉感觉自己能做的全被王强大佬做啦,那你自己还做什么呢的疑惑,其实静下心来仔细琢磨这篇论文你肯定会获得不少的改进思路的,快快行动起来吧,也许你就是视觉目标跟踪领域的下一个大佬!
4.2、个人总结
深层网络在孪生网络框架中的使用一直是Siamese系列的一个关键问题,本文通过简单的调整训练过程中正样本的采样方式让深层网络可以在跟踪中发挥作用,同时通过多层聚合的方式更大程度的发挥深层网络的作用。除此之外,新的轻量级的DW卷积在减少参数量的同时,也增加了跟踪算法的性能。除此之外,本文提出的算法可以在多个数据集上达到state of the art的性能。
注意事项
[1] 该博客是本人原创博客,如果您对该博客感兴趣,想要转载该博客,请与我联系(qq邮箱:[email protected]),我会在第一时间回复大家,谢谢大家的关注。
[2] 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
[3] 如果您在阅读本博客时遇到不理解的地方,希望您可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
[4] 本文内容中的大部分内容都摘自该博客,本来打算按照自己的思路去写,不过想来想去还是绝对这篇博客说的更好一点,为了让读者们能够更好地了解该论文,还是引用了该博客的内容。
[5] 本人业余时间承接各种本科毕设设计和各种小项目,包括图像处理(数据挖掘、机器学习、深度学习等)、matlab仿真、python算法及仿真等,有需要的请加QQ:1575262785详聊!!!
参考资料
1、https://zhuanlan.zhihu.com/p/56254712