Android 从零学数据结构与算法(1)——数据结构和线性表(ArrayList、vector、LinkedList源码部分解析)
本博客的原创文章,都是本人平时学习所做的笔记,不做商业用途,如有侵犯您的知识产权和版权问题,请通知本人,本人会即时做出处理删除文章。
- 数据结构
数据之间相互存在的一种或多种特定关系的元素结合。
数据对象中元素之间的相互关系:
1.集合结构;
2.线性结构;
3.树形结构;

4.图像结构;
物理结构(存储结构):
1.顺序存储结构;

2.链式存储结构;

数据类型:一组性质相同的值的集合及定义在此集合上的一些操作的总称
抽象数据类型:一个数字模型及定义在该模型上的一组操作
- 线性表(List)

线性表:a1是a2的前驱,ai+1是ai的后继,a1没有前驱,an没有后继,n为线性表的长度,若n=0时,线性表为空
- 顺序存储方式线性表:

存储位置连续,可以很方便计算各个元素的地址,如每个元素占C个存储单元
那么有:Loc(An)=Loc(An-1)+C,于是有:Loc(An)=Loc(A1)+(i-1)*C;Loc(A1):A1的内存地址
顺序线性存储有个特征:增删慢,查找快,你要在某个位置插入一个元素,这个位置之后的元素都得后移,这个开销是很大的。在Java中ArrayList就是采用的线性表,内部是用Object[]数组实现的,我们看看源码,看看ArraList.add()两个参数的方法。
transient Object[] elementData;
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}上面的代码很清楚的看到,elementData就是Object数组,从index位置的数组元素都向后移了一位。如果不知道System.arraycopy()方法的请自行百度,很简单,就不介绍了。如果你已经打开了源码,你还可以搜索一下remove方法,也是指定坐标的元素删除后再前移一位。
这里顺便提一下,ArrayList和vector的区别,底层都是数组,而ArrayList线程是不安全,而vector是线程安全的。比对一下源码就知道了,vector方法声明上添加了synchronized。vector的add代码如下:
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}2. 链式存储方式线性表
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。
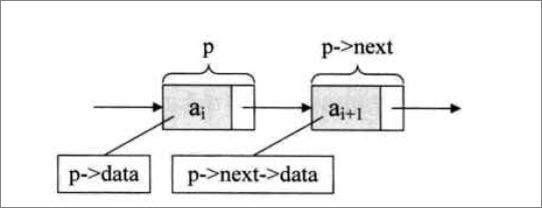
看上图,前面的ai是数据域,后面的空白是指针域,数据域存储数据,指针域存储下一个单元格的地址。
链式存储的优点:增删快,查询慢。
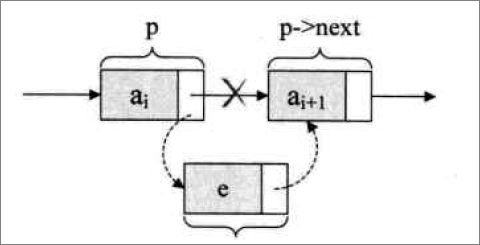
由上图可见,要插入一条数据,只需要ai单元格的指针域指向e单元格,e单元格的指针域指向ai+1单元格,ai和ai+1之间的关系就断了。除了这三个元素需要动,其他的元素都不需要动。这样插叙效率是非常快的。
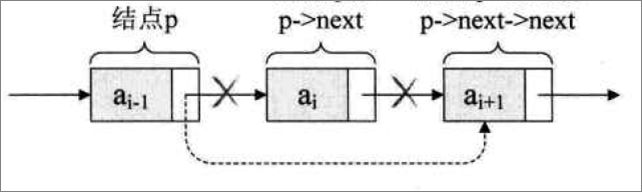
删除更效率,看上图。节点ai-1的指针域直接指向ai+1就可以了。
为什么说链式存储查询慢呢?链式存储的存储地址不一定是连续的,你要查询某个元素,需要从第一个元素开始一个一个查询。
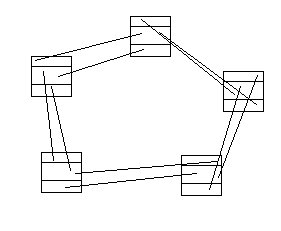
循环链表:将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相连的单链表称为单循环链表,简称循环链表,如下图:
下面我们一起看看链表结构的LinkedList的源码:
transient Node first;
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 这是一个内部类,是LinkedList的节点定义。上面我们已经说到了,每个单元格都有数据域和指针域,item就是存储数据,next存储的是下一个对象引用,prev存储的是上一个对象引用,这是双向链表。LinkedList的内部结构就是双向链表,每个节点都是双向指定。
上图画的不好请见谅,看前驱指针域的指向和后继指针域的指向。注意:我上图画的是双向循环列表,在jdk1.6的LinkedList是双向循环链表,而在jdk1.7之后是双向链表,没有"循环"。所以jdk1.7以后是首尾不相连的。而上述的源码是jdk1.7版本之后的源码。下面我们分析下add()方法的源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
} Node node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
} 看上面三段源码,是在指定位置添加元素,note(int index)方法是返回index位置的下个节点对象,note(int index)方法内部的实现为了效率,采用二分法遍历找到index的后继节点。双向链表有一个好处是通过next我们可以从前往后查询,也可以通过prev从后往前查询,所以我可以用二分法。在linkBefore()方法中,把新节点前驱引用指向了后继节点的前驱引用,把新节点的后继引用指向了后继节点,把后继节点前驱引用指向了新节点。这块有点绕,需要看源码好好屡屡。
看懂add方法的源码,其他方法源码都能看懂了,就不一一介绍了。
很荣幸我们能一起学习,一起成长。如果文中有错误,欢迎大神留言指正。谢谢!
- 下节预告
------------------------------------------------
想要继续跟我一起学习一起成长,请关注我的公众号:程序员持续发展方案
