首次公开!阿里搜索中台开发运维一体化实践

阿里妹导读:2015年底,阿里宣布启动阿里巴巴集团中台战略。战略定义为:构建符合DT时代的更具创新性、灵活性的“大中台、小前台“组织机制和业务机制。其中,前台作为一线业务,更敏捷更快速适应市场,中台将集合整个集团的数字运营能力、产品技术能力,对各业务前台形成强力支撑,而集团在中台布局中一个非常重要的一环便是搜索中台化,但因搜索技术本身的复杂度和业务规模的挑战,让搜索中台在技术上、产品上都遇到了世界级的挑战。
面对挑战,阿里选择走上中台开发运维一体化实践之路。这条路究竟要怎么走?下面一起来了解。
背景
阿里搜索中台的初心是支持前台业务更敏捷更快速适应市场的变化,愿景是让天下没有难用的搜索,基于初心和愿景我们从0到1建设搜索中台3年,三年期间在DevOps、AIOps、offline平台化上都有了不少业内前沿的沉淀,而我作为一名阿里搜索老兵,有幸见证了整个阿里搜索中台的技术发展,所以在这里通过一些我个人有限的经验跟大家去分享一个后端服务该如何解决规模化、成本、效率、质量问题,朝着平台化产品前进的经验。
搜索中台技术发展
下图即是搜索中台从技术角度发展趋势的一个判断,也是经过3年多落地实践的一个过程。
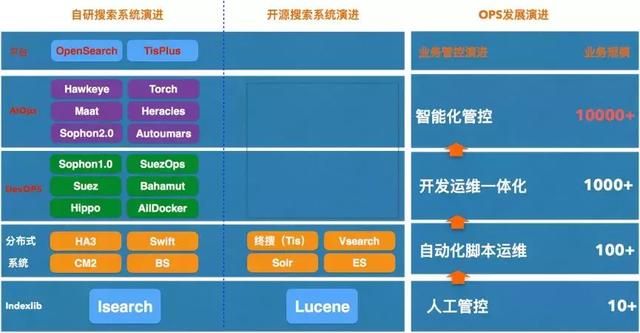
可以从图上看到第一个阶段应该是我加入阿里的时候,无论是搜索事业部还是开源搜索技术都是靠人来负责系统和业务运维。当时人力资源是随着业务规模成正比增长的,这期间消耗了大量的人力资源在做着低效而重复工作,这是人工管控的阶段。
之后随着经验沉淀,PE逐渐发现一些常见重复的运维工作可以通过自动化脚本实现,在一定程度上减少了人力成本,提高了运维效率,也初步有了专家经验和领域知识沉淀的影子,这是自动化脚本运维阶段,这也是绝大部分开源技术体系所处的阶段。但是这样的运维方式天然地分割了开发和运维两种角色。
因为大家的使命不同,让两种角色天然的站在了对立面上,开发希望快速迭代,运维希望尽可能保障线上稳定而减少迭代次数,因为大家都知道绝大部分线上故障都其实是因为配置变更和软件升级导致的,天然的分割造成了相互之间存在着对对方的不信任,所以也就有了双方最后的妥协:固定每周周二和周四的发布窗口进行发布,但这是牺牲了业务运营效率为前提的。
其实这里存在了一个系统能力和业务方迭代需求上的一个很大gap,为了解决上述矛盾基于运维开发一体化的devOps概念的全新管控系统建设应运而生,也就有了第一阶段的开发运维一体化的建设,通过这些ops也较好地解决一些发布迭代问题。
但是我们的业务场景天然是一个技术体系的管控,所以我们认为devops不应该还停留在单个系统开发运维一体化的方法论认知上,所以希望我们的devops的定义是单个系统ops之上的“ops”,所以本质上我们和集团其他所谓的devOps平台有着非常大本质上的区别。
集团比较有代表性devops平台就是天基平台,它主要解决的是服务源代码到部署再到升级的一个全过程的管理,面向的用户本质上还是运维人员。所以在这个基础上,天基利用IAC(Infrastructure As Code,基础设施即代码)的维度+Git管理部署配置去打造产品其实已经足够,这是一种典型devops的平台设计思路,但是仅仅如此的设计其实对于我们来讲也许并不够,因为对于我们来说我们的用户是最终用户,他并不具备线上系统运维专业知识,只看到配置或者code,他一定会晕菜。
所以从根本上来讲我们需要将对DevOps理解上继续往前走一步,朝着面向平台产品化的角度上前进一步:一是对用户屏蔽配置或者code或者领域知识复杂度,二是将系统协同变成一种端对端体验的管控,因为只有做到了简化复杂度和全链路端对端体验的管控才能真正让复杂搜索业务迭代效率得到本质上的提升,为了达成上述2个目标我们经过多年努力逐步落地了sophon、bahamut、Maat等系统,也取得了很好的业务迭代效率提升。
但只做到DevOPS对于阿里这样体量的平台就完美了吗?显然不是,全链路的DevOps只是有效解决了研发、PE、用户配合效率和用户使用体验的问题,但是对于平台方来讲随着业务规模的急剧膨胀,以及搜索服务类型的复杂多样及多变,业务跟平台的矛盾其实又发生了本质性的转移:如何给在海量规模下为每个业务提供更好的稳定性保障和合理的资源利用率、以及更高的迭代效率等就成为了我们平台新目标。
目前我们基于在AIOPS数据化运营的3年实践中落地了Hawkeye -在线服务优化平台、Torch-容量治理平台、Heracles-日常压测服务化平台、CostMan-成本服务等系统。这些服务系统帮助平台在容量管理,日常巡检、一键诊断优化上取得了一定的阶段性成果,也让我们对未来统一集团搜索运维管控,业务数量即使超过10000+规模效应下平台也能应对自如,树立了坚定的信心。
虽然经过3年的数据化运营的实践,但我们离真正的AIOps还有较远距离,因为之前我们的性能瓶颈分析、问题诊断、故障自愈、复杂运维决策主要还是停留在专家经验沉淀上,说白了还是把人的经验沉淀到系统来解决线上运维的问题,而AIOPS期待的是用数据和算法能力帮我们自动地发现规律问题并解决问题,从这点上看AIOps在我们的平台依然还有非常多的潜力可挖,所以我们希望未来在效率提升、质量保障、成本优化上能真正借助AI的能力帮平台更好地适应未来的发展。
搜索中台开发运维一体化实践-Sophon
开发运维一体化-DevOPS
在我们介绍开发运维一体化-sophon的系统前,我们先看看一个稍微复杂搜索场景的业务接入时需要涉及到的系统以及他们是如何协调工作的。
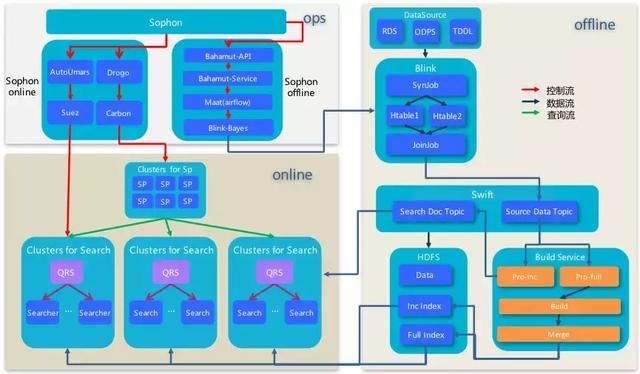
从上图其实大家看到整个系统模块大致分为3大模块,OPS、Online、Offline。其中如图所示Ops层很明显分成了在线有状态服务ops、在线无状态服务ops和离线ops。
就是说每个服务都是单独OPS进行单独管控,但实际上如上图所示一个复杂业务就是一个多服务体系协同的结果,所以在我的记忆里当tisplus没上线前,我们接入复杂业务之前第一件事情就是召集在线有状态服务团队、在线无状态服务团队、离线DUMP团队、业务方、PE开个会互通下有无,然后安排怎么合作推进这个项目上线,上线后的线上变更和问题处理也是支持群里相互吼:“我已经做完这一步了,你可以做下一步了”,“你稍等下再操作,我还要重新发下”。所以可以想象这样的业务接入合作效率得有多低,相信大家从我刚才的描述中也能知道为啥我们之前支持10来个业务已经是极限的原因了吧。
有了这些痛点需求,那再回过头来说说我们我们在实践过程中认为复杂搜索系统的devops建设必须有:
- 提供端对端体验的全链路OPS才是我们认为符合我们场景的devops标准定义。
- 复杂的运维管控链路中基于我们常识认知的过程式运维方式需要升级到基于目标驱动式的运维管控。
- 较好的运维抽象及产品抽象,更好的赋能用户。
- 提高业务迭代效率必须是保障业务稳定性为基础。
有了这些需求痛点,也就有了我们在这个领域的技术平台布局-Sophon,接下来我们将分章节详细介绍下该系统。
搜索中台devops实践-Sophon
目标驱动式运维
什么叫基于目标驱动式的运维?其实乍一听,会觉得太过于抽象,其实如果听完我的解释,你会觉得非常简单,我们举个实际搜索的运维场景来说明也许更容易明白为什么我们要提倡基于目标的运维管控。

比如我们的搜索系统现在的索引版本是A版本,然后要求系统执行切换索引B版本,但正在rollingB版本的时候,我后悔了我要rolling C 版本。这其实在早些年的时候,线上这种状况是非常让人崩溃的,如果这事让PE去做的话 , 只能杀掉切换流程,检查系统每个节点到哪一步了,清理中间状态,重新发起运维流程,可以想象过程式的运维管控方式在复杂运维体系下是多么低效的事情。
但如果是基于目标驱动的调度,我们只需要重新给系统设定新的rolling C版本,那么系统将会获得最新目标和当前执行渐进的目标进行对比,发现目标状态存在变化,系统会马上终止掉当前执行路径和自动清理系统存在的不一致状态,开始下放最新目标状态关键路径执行通知,各个节点接受到最新命令后开始逐步向新的目标渐进,所以只看最终状态的渐进式最终一致性运维方式自然而然屏蔽了运维中间状态的复杂性,让复杂运维管控变得更加简单更灵活,这也是为什么我们平台自上而下所有的运维方式都升级成了基于目标驱动的原因。
运维概念简化
我们平台一直提到从托管到赋能,言下之意是希望让最终用户承担起自己应当要承担的责任才能享受更强大的搜索能力。但谈到要赋能,那也不能将搜索系统复杂的领域知识和运维概念直接暴露给最终用户,否则这肯定不叫赋能用户,而是叫做折腾用户了。所以如何将系统的运维概念简化,将复杂和潜在领域知识留给系统内部就是sophon需要解决的核心问题之一。

上图下方是从PE视角看到的各个数据中心的基础设施和各种在线服务,如果没有一层管控抽象,让最终用户和PE看到的是一样的复杂度,我相信用户一定会晕菜。
所以sophon做的一个事情就是将运维管控对象抽象成一组数据关系模型,也就是运维管控模型,如上图右侧所示,但是这一层运维抽象依然足够复杂,用户不应该也不需要去了解这层运维抽象,我们应该给用户看到的是触达业务场景的业务抽象,所以sophon在第一层运维抽象之上又抽象了业务抽象,如左上角的三层概念:业务逻辑(插件、配置)、服务(部署关系)、数据(数据源&离线数据处理)。这层的定义用户是几乎无成本就能接受的,所以通过sophon做到的抽象运维概念和简化业务概念的能力也让我们平台从托管到赋能用户成为了可能。
稳定性保障
sophon保障服务稳定性主要体现在2个方面:
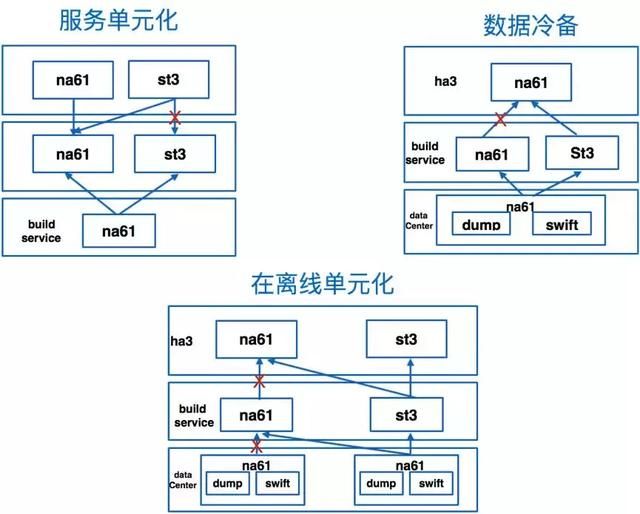
- 当平台支持越来越多的头部核心业务,我们需要对业务的搜索服务进行SLA保障,同时也能适应各个业务根据自己的稳定性要求进行灵活的在离线服务的部署,同时还需要具备自动容灾切换能力。目前sophon服务稳定性方面能够支持搜索在线服务单元化、在离线服务单元化、离线数据冷备部署以及查询链路和数据回流链路自动容灾切切换的能力,如下图所示:
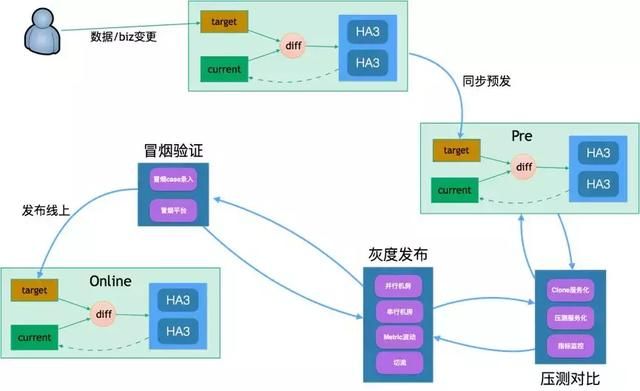
- 我们前面提到迭代效率提升有一点就是让原先基于时间窗口的线上发布迭代变成了可以24小时随时随地可以发布,但我们说的随时随地并不是代表我们只是提供了发布按钮功能,而不去考虑快速发布过程可能带来的潜在危险,所以高效且安全的发布迭代才是我们追求的目标,这个背后非常重要的基础就是我们设计和标准化了一套发布迭代规范。
- 例如一次正常的业务迭代,需要经过日常、预发2套环境进行验证,同时在预发发布线上的发布流程中我们加入了多重校验机制来进行发布的稳定性,比如插件、算法策略升级时,我们会要求clone压测对比,如果性能差距太大,发布流程会被回退,同时基于单机房切流灰度发布和冒烟验证等能力可以在发布流程里被定义,所以有了sophon提供的强大的多重校验机制和快速容灾切换的能力,让业务快速迭代中再也没有了后顾之忧,可以将业务运营迭代效率提升到极致,如下图所示:
专家经验沉淀
搜索技术体系虽然功能强大,但强大的背后也有很多专业潜规则,所以如果平台把复杂的运维管控和业务迭代需要遵循的专业知识暴露给普通用户,用户肯定歇菜,所以我们在devops这层一定要将引擎服务领域知识下沉让平台去屏蔽这些复杂性。
举个真实的搜索场景来说,如果业务方有一个字段的修改,但真实情况下一个字段的修改其实是可能涉及到在线和离线的配置联动修改,换句话说你不能说让用户在修改配置的时候让他判断我这次修改是只会影响到在线服务、还是影响到离线服务,还是在离线服务都会影响到,此外配置推送需要先离线服务生效还是在线服务先生效,还是说配置必须做全量后一起生效等等,这些都是引擎服务的专家知识。
目前我们依靠sophon devOPS这层将这些领域知识都在背后默默消费掉了,用户完全不需要关注这些潜在知识,运维平台内部会分解复杂运维操作,然后会根据我们定义好的专家运维DAG图来有条不紊分阶段的进行运维执行,如下图所示:

通过我们不断将运维专家经验沉淀到系统(运维DAG执行流程图),用户对平台的使用成本会不断变小,同时迭代效率也会越来越高。当然如果运维操作变得越来越复杂(比如我们暴露给用户的业务视角需要涵盖越来越多的服务),运维DAG执行链从简单就会发展到可能存在多种执行分支,那么如何在运维执行中寻找到最优执行链路就会成为一个有趣的话题(如上图右边所示),目前我们称之为最短路径选择,这是智能化运维一个有趣的尝试,这也是未来我们持续努力的方向。
从系统到全链路
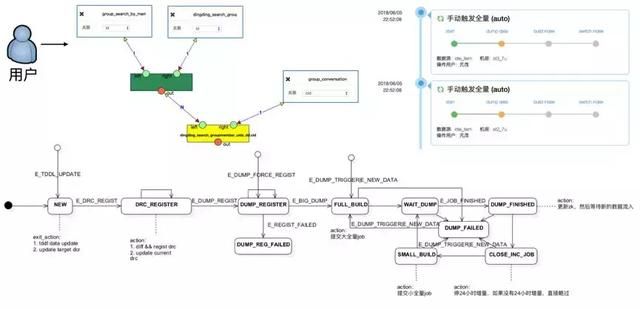
前面其实也介绍了我们的所有业务场景都是一个技术体系协同的结果,而这个过程中最重要也最具挑战的点便是如何将在线和离线高效协同提供给用户端对端的体验。
从上图可以看到最终用户使用离线数据永远看到的是可视化数据关系定义和简单的dump->Build->switchindex任务执行列表。但是实际上是我们把所有的复杂度屏蔽掉,系统背后却是有一个复杂的状态机在管控在离线的协同,这张图不打算展开讲,整个在离线协同,状态机不是关键,关键是我们如何将每个在线搜索业务对离线数据处理的个性化需求转换成一种抽象,最后通过平台方式来支撑的。
在展开介绍离线平台技术前,稍微跟大家介绍下一个搜索业务对离线处理的普世需求,而这些需求也是没有离线平台之前支持复杂业务在离线跨团队合作中被重复讨论过多次的话题。那就是到引擎的业务数据并不是一个简单的数据库表,它可能来源于多个同构或者异构数据源,同时每个搜索业务都有全量和增量的需求,所以如何将这些根据业务不同而不同数据源关系处理变成一种高层抽象并且屏蔽内部处理环节和统一增量和全量处理流程就变得非常重要,否则来一个业务我们都要为其实现全量和增量数据处理代码简直是不可忍的事情。
现在来回顾之前我们离线支持效率低的原因还是我们之前对引擎schema定义的数据源都是被弱化成一对对的资源进行抽象和管理,也就导致我们没有把本应该的基础的抽象给提炼出来,其实仔细想下来我们目前接入的所有数据资源都是Dynamic Table,所以如果我们以表的抽象去定义这些资源,那一些通用的类似创建表、删除表、修改表、增删改查表数据,定义表之间关系等API都应该可以被收敛掉而不会存在重复开发问题,所以有了这样一个思考,也就有了我们打造离线组件平台-bahamut的整体设计思路。
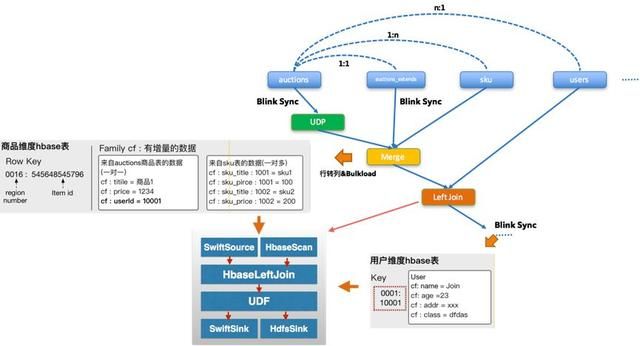
平台支持用户在平台画布上定义好各自数据源信息和表之间关系定义后(我们可以支持异构表之间的join,例如odps和mysql),我们会将这个前端的Graph提交给Bahamut进行翻译,bahamut将这个前端的Graph解析、优化、拆分、翻译成成若干个blink可执行的graph,比如增量的syncBlink 、全量的BulkLoad MR任务,和Blink Join 任务等。
这里最重要的两个关键的graph节点是merge和left join。merge是将所有的1:1和1:N关系表的处理通过行转列到一个HBASE中间表,而N:1的关系处理以下图的例子来说,我们目前只支持主表N这边(商品表)驱动,也就是说N这方的通过blink sync更新后利用blink Join合并1这方(即用户表)成完整的行记录发送到SwiftSink(增量)&HDFSSink(全量)最终回流到到BuildService构建索引,如下图所示:
通过在线离线管控协同和BaHamut组件平台的打造,可以让用户通过可视化的手段就能享受到强大的离线复杂数据关系处理和计算能力,极大地提升了业务支持效率,同时也让我们平台成为第一个可以整合离线提供在离线端对端体验的里程碑式的产品。另外我们还在做一件事情将离线能力变成在线服务通用能力,相信不远的将来离线组件平台不会是HA3搜索场景的离线组件平台,而是整个搜索在线服务的离线组件平台。
本文是阿里搜索中台技术系列Devops实践的分享,接下来还会陆续推出搜索离线组件平台、搜索AIOps实践的多篇分享,敬请期待。
搜索中台从0到1建设已经走过了3年,但它离我们心目中让天下没有难用的搜索的远大愿景还离得非常远,在这个前行的道路上一定会充满挑战,无论是业务视角的SaaS化能力、搜索算法产品化、云端DevOps&AIOps,还是业务建站等都将遇到世界级的难题等着我们去挑战。
无论是web开发,引擎开发还是算法同学,欢迎加入我们阿里搜索中台团队
平台工程师岗位详情:https://job.alibaba.com/zhaopin/position_detail.htm?trace=qrcode_share&positionCode=GP037395
我们一起让天下没有难用的搜索。