深度学习应用到图像超分辨率重建2
图像超分辨重建一直也算是一个比较火的话题,发展也是很迅速的,下面结合我最近看的几篇文章,写写一些论文总结。
图像超分辨重建的基本的思想以及常见的一些算法已经在我之前的一篇文章介绍了,这里也就不过多介绍了。感兴趣的同学可以参考这篇文章深度学习应用到图像超分辨率重建1 这里着重介绍一些新发展的一些文章。
1. Learning a Single Convolutional Super-Resolution Network for Multiple Degradations (CVPR, 2018)
文章地址: https://arxiv.org/pdf/1712.06116.pdf
作者的项目地址: SRMD
1.1 简单介绍:
传统的CNN用于SR方法假设LR由HR经过双3次bicubic降采样得到的,但是当真实图像不遵循该假设时候,SR效果比较差。现有方法不能扩展用单一模型解决多种不同图像退化模型。为此,提出一种维度拉伸策略将单个SR网络将SISR退化过程二个关键因素(退化模糊核和噪声水平)作为网络输入。

实验结果:

2. Residual Dense Network for Image Super-Resolution(CVPR 2018 Spotlight)
文章地址:https://arxiv.org/abs/1802.08797
作者的项目地址: RDN
2. 1 引言
之前的网络结构没有充分利用好层级结构,我们提出一个残差密集连接网络。
2. 2 主要贡献
- 网络充分利用了原始LR图像层级特征。
- 提出了RDB通过CM然后通过LFF
- 将所有的特征通过特征融合。
- 另外在实验过程中不仅仅考虑了bicubic downsampling,也考虑了gaussian kernel。

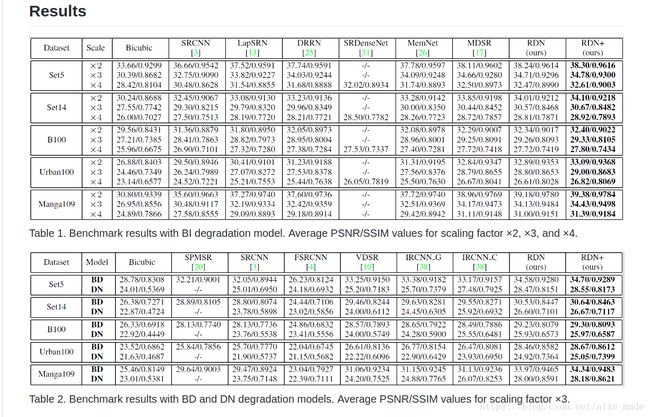
3. Deep Back-Projection Networks For Super-Resolution (CVPR, 2018)
文章地址:https://arxiv.org/abs/1803.02735
作者的项目地址: DBPN-Pytorch
3. 1 简介
- 近年来提出的SR网络多为前馈结果,学习LR和HR非线性映射,然而这不能解决LR和HR之间的映射。
- 之前的研究表明,人类的视觉系统可能使用反馈连接,最近的SR 网络由于缺乏这种反馈,可能不能很好表达。
- 作者提供一种不断上采样、下采样网络,为每个阶段提供一种错误反馈机制,网络为DBPN(Deep Back-Projection Networks)以及扩展版本的D-DBPN.
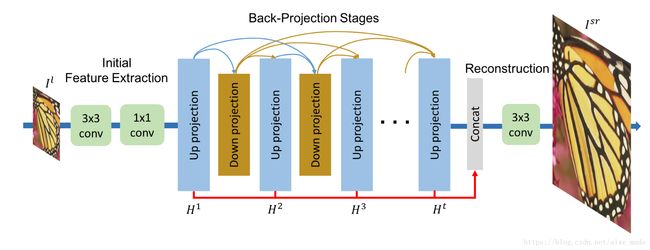
####4. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks(2018 CVPR)
文章地址:https://arxiv.org/abs/1711.10485
作者的项目地址: AttnGAN
4.1 简介
本文提出了细粒度图像生成,通过借助文本描述生成包含充分细节图像。利用了Attention-driven, multi-stage-refiment. GAN三种方法生成理想图像,建立了文本描述到图片细节attention。
构建了DAMSE使得Text-encoder和Image-encoder生成特征可以在公共空间对齐,表示相似性。也就是利用多模态相似性为目标协同优化特征提取,使得提取特征有利用GAN性能的提升。
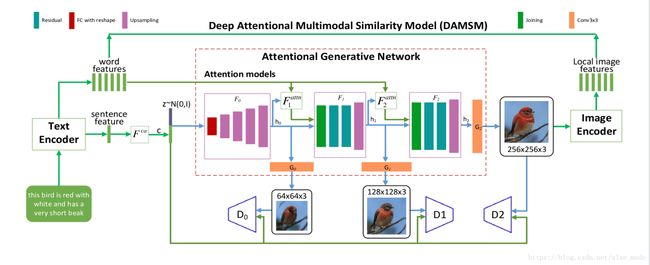

5. FSRNet: End-to-End Learning Face Super-Resolution with Facial Priors(2018 CVPR SPOTLIGHT Presentation)
文章地址:https://arxiv.org/abs/1711.10703
作者的项目地址: FSRNet
5. 1简介
本文提出了一个新的端到端训练人脸超分辨网络,通过更好的利用人脸特征脸热度图和分割图几何信息,在无需人脸对齐提升非常低分辨人脸图像质量。
具体上,首先构建一个粗细粒度超分辨网络恢复一个粗精度HR,其次把图像送入一个细粒度超分辨编码器和一个先验信息估计网络二条分支。细粒度抽取图像特征,先验网络估计人脸特征点和分割信息。最后二个分支结果汇入一个细粒度解码器进行重构信息。

6. Super-FAN: Integrated facial landmark localization and super-resolution of real-world low resolution faces in arbitrary poses with GANs(2018 CVPR)
文章地址:https://arxiv.org/abs/1712.02765
作者的项目地址: 无
6.1 主要贡献
- 同时解决两个任务的端到端系统,即,既提高面部分辨率又检测面部特征。新颖性或Super-FAN的核心在于通过热像图回归和优化新热像失真,通过集成子网络进行面对齐,将结构信息合并到基于GAN的超分辨率算法中。
- 我们通过不仅报告正面图像(如以前的工作),而且整体报告面部姿势,而不仅报告合成的低分辨率图像(如以前的工作),而且报告良好的结果,共同训练这两个网络的好处,但也在真实世界的图像上。
- 通过提出一种新的基于残余的体系结构来证明最新的面部超分辨率技术。
- 在数量上,我们展示了超高分辨率和对齐的最新技术。
- 定性地说,我们首次在真实世界的低分辨率图像上显示出良好的结果。


7. “Zero-Shot” Super-Resolution using Deep Internal Learning(2018 CVPR)
文章地址:https://arxiv.org/abs/1712.06087
非官方的项目地址: pytorch-zssr
在以往的SR基于大量的LR-HR进行训练的,其中LR方法是诸如MATLAB的imresize函数。这种称为ideal。但是实际上SR中的LR是好多的non-ideal。掺杂噪声,未知的降采样核,aliasing现象。
作者提出“zero-shot” 致力于寻找单个图像信息。在SR过程中,对改图再次降采样,学习二者超分辨参数,用于LR分辨。


8.Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform(2018 CVPR)
文章地址:https://arxiv.org/abs/1804.02815
官方的项目地址: CVPR18-SFTGAN
本文深入探讨了如何使用语义分割概率图作为语义先验来约束超分辨率解空间,使生成图像纹理符合真实而自然纹理特征。还提出了一种空间特征调制层(SFT)有效的将先验条件结合到网络中空间调制层和现有SR网络使用相同的损失函数,端到端进行训练。


9. Image Super-Resolution via Dual-State Recurrent Networks(2018 CVPR)
文章地址:https://arxiv.org/abs/1805.02704
官方的项目地址: 无
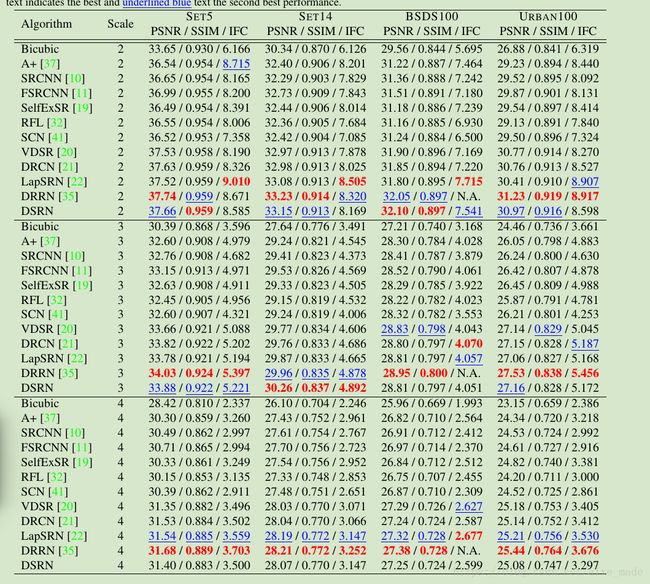
最近的图像超分辨力主要朝着二个方向发展,一个是越来越深网络,另外一个就是残差学习,包含了全局、局部和联合,但是这些也会出现一些问题。比如网络模型增大,网络也越来越大。虽然DRRN,DRCN利用了递归神经网络,也利用了残差学习,但是会导致我们的重建速度变慢。最近一些论文发现残差学习可用使用浅层的RNN网络表示,受到这个启发,作者引出了双循环状态网络进行SR,发现我们的网络DSRN不仅仅在参数上,在重建效果上也取得了不错的效果。


10.Deep Residual Network with Enhanced Upscaling Module for Super-Resolution(2018 CVPRW)
文章地址: http://openaccess.thecvf.com/content_cvpr_2018_workshops/w13/html/Kim_Deep_Residual_Network_CVPR_2018_paper.html
项目地址: 无
10.1 背景介绍
最近的SR对于upscale模块大致分成了三种,分别是 Pre-upscaling , Post-upscaling , Progressive upscaling。而很少有人对上采样的策略进行研究。目前主要的分成deconvolution,sub-pixel以及相邻上采样的几种。目前主流的使用sub-pixel conv,而作者指出了这种策略的不足之处:
- sub-pixel层只是使用线性的核,所以它限制在非线性的表达能力上面。
- 没有使用残差连接,而这个在啊很多特征提取模块都使用了。
- 上采样的模块相对具有比较简单的的结构
针对以上问题,作者提出一种 enhanced upscaling module (EUM)模块作为upscaling module,同时也进一步提出来EUSR网络。
10.2 网络介绍
这是EDSR的基本框架:
将上面的红色的upscaling module换成以下EUM模块。我们可以看出和之前的改进的地方。之前的模块是通过一个复杂的卷积网络进行的,但是现在EUM是一种逐渐的过程,利用每一residual 块的特征然后concatenate起来,有一种densenet的思想,其实本质上也是引入了一种注意力机制。另外网络也是变得复杂了,所以也可以引入残差连接,而在残差连接中,自然而然的可以加入很多relu等非线性单元。

然后作者提出的EUSR网络结构。

10.3 实验部分
其实实验和之前SR方法相比差不多,主要就是论证提出的EUM相比有效就行了。和其他的state-of-art相比感觉效果也差不多了,感兴趣的同学可以自己去看论文啦。
上面的文章并没有在细节上做过多的介绍,大家感兴趣的话可以精读,然后看看代码。从上面文章代码提供来看,大部分的都是基于Pytorch框架,这让我们使用tensorflow框架有点难受,自己造轮子重现作者代码还比较麻烦,但是pytorch动态图用起来确实很不错,所以可能要入Pytorch的坑了~