Android逆向之旅—解析编译之后的Resource.arsc文件格式
一、前言
快过年了,先提前祝贺大家新年快乐,这篇文章也是今年最后一篇了。今天我们继续来看逆向的相关知识,前篇文章中我们介绍了如何解析Android中编译之后的AndroidManifest.xml文件格式:点击进入
当时我说到其实后续还要继续介绍两个文件一个是resource.arsc和classes.dex,今天我们就来看看resource.arsc文件个格式解析,classes.dex的解析要等年后了。
二、准备工作
我们在使用apktool工具进行反编译的时候,会发现有一个:res/values/public.xml这个文件:

我们查看一下public.xml文件内容:

看到了,这个文件就保存了apk中所有的类型和对应的id值,我们看到这里面的每个条目内容都是:
type:类型名
name:资源名
id:资源的id
类型的话有这么几种:
drawable,menu,layout,string,attr,color,style等
所以我们会在反编译之后的文件夹中看到这几个类型的文件xml内容。
上面我们介绍了如何使用apktool反编译之后的内容,下面我们要做的事情就是如何来解析resource.arsc文件,解析出这些文件。
我们解压一个apk得到对应的resource.arsc文件。按照国际惯例,每个文件的格式描述都是有对应的数据结构的,resource也不例外:frameworks\base\include\androidfw\ResourceTypes.h,这就是resource中定义的所有数据结构。
下面再来看一张神图:

每次我们在解析文件的时候都会有一张神图,我们按照这张图来进行数据解析工作。
三、数据结构定义

这个是项目工程结构,我们看到定义了很多的数据结构
第一、头部信息
Resources.arsc文件格式是由一系列的chunk构成,每一个chunk均包含如下结构的ResChunk_header,用来描述这个chunk的基本信息
package com.wjdiankong.parseresource.type;
import com.wjdiankong.parseresource.Utils;
/**
struct ResChunk_header
{
// Type identifier for this chunk. The meaning of this value depends
// on the containing chunk.
uint16_t type;
// Size of the chunk header (in bytes). Adding this value to
// the address of the chunk allows you to find its associated data
// (if any).
uint16_t headerSize;
// Total size of this chunk (in bytes). This is the chunkSize plus
// the size of any data associated with the chunk. Adding this value
// to the chunk allows you to completely skip its contents (including
// any child chunks). If this value is the same as chunkSize, there is
// no data associated with the chunk.
uint32_t size;
};
- @author i
*/
public class ResChunkHeader {
public short type;
public short headerSize;
public int size;
public int getHeaderSize(){
return 2+2+4;
}
@Override
public String toString(){
return "type:"+Utils.bytesToHexString(Utils.int2Byte(type))+",headerSize:"+headerSize+",size:"+size;
}
}
type:是当前这个chunk的类型
headerSize:是当前这个chunk的头部大小
size:是当前这个chunk的大小
第二、资源索引表的头部信息
Resources.arsc文件的第一个结构是资源索引表头部。其结构如下,描述了Resources.arsc文件的大小和资源包数量。
package com.wjdiankong.parseresource.type;
/**
struct ResTable_header
{
struct ResChunk_header header;
// The number of ResTable_package structures.
uint32_t packageCount;
};
- @author i
*/
public class ResTableHeader {
public ResChunkHeader header;
public int packageCount;
public ResTableHeader(){
header = new ResChunkHeader();
}
public int getHeaderSize(){
return header.getHeaderSize() + 4;
}
@Override
public String toString(){
return "header:"+header.toString()+"\n" + "packageCount:"+packageCount;
}
}
header:就是标准的Chunk头部信息格式
packageCount:被编译的资源包的个数
Android中一个apk可能包含多个资源包,默认情况下都只有一个就是应用的包名所在的资源包
实例:
图中蓝色高亮的部分就是资源索引表头部。通过解析,我们可以得到如下信息,这个chunk的类型为RES_TABLE_TYPE,头部大小为0XC,整个chunk的大小为1400252byte,有一个编译好的资源包。

第三、资源项的值字符串资源池
紧跟着资源索引表头部的是资源项的值字符串资源池,这个字符串资源池包含了所有的在资源包里面所定义的资源项的值字符串,字符串资源池头部的结构如下。
package com.wjdiankong.parseresource.type;
/**
struct ResStringPool_header
{
struct ResChunk_header header;
// Number of strings in this pool (number of uint32_t indices that follow
// in the data).
uint32_t stringCount;
// Number of style span arrays in the pool (number of uint32_t indices
// follow the string indices).
uint32_t styleCount;
// Flags.
enum {
// If set, the string index is sorted by the string values (based
// on strcmp16()).
SORTED_FLAG = 1<<0,
// String pool is encoded in UTF-8
UTF8_FLAG = 1<<8
};
uint32_t flags;
// Index from header of the string data.
uint32_t stringsStart;
// Index from header of the style data.
uint32_t stylesStart;
};
- @author i
*/
public class ResStringPoolHeader {
public ResChunkHeader header;
public int stringCount;
public int styleCount;
public final static int SORTED_FLAG = 1;
public final static int UTF8_FLAG = (1<<8);
public int flags;
public int stringsStart;
public int stylesStart;
public ResStringPoolHeader(){
header = new ResChunkHeader();
}
public int getHeaderSize(){
return header.getHeaderSize() + 4 + 4 + 4 + 4 + 4;
}
@Override
public String toString(){
return "header:"+header.toString()+"\n" + "stringCount:"+stringCount+",styleCount:"+styleCount+",flags:"+flags+",stringStart:"+stringsStart+",stylesStart:"+stylesStart;
}
}
header:标准的Chunk头部信息结构
stringCount:字符串的个数
styleCount:字符串样式的个数
flags:字符串的属性,可取值包括0x000(UTF-16),0x001(字符串经过排序)、0X100(UTF-8)和他们的组合值
stringStart:字符串内容块相对于其头部的距离
stylesStart:字符串样式块相对于其头部的距离
实例:
![]()
图中绿色高亮的部分就是字符串资源池头部,通过解析,我们可以得到如下信息,这个chunk的类型为RES_STRING_POOL_TYPE,即字符串资源池。头部大小为0X1C,整个chunk的大小为369524byte,有8073条字符串,72个字符串样式,为UTF-8编码,无排序,字符串内容块相对于此chunk头部的偏移为0X7F60,字符串样式块相对于此chunk头部的偏移为0X5A054。
紧接着头部的的是两个偏移数组,分别是字符串偏移数组和字符串样式偏移数组。这两个偏移数组的大小分别等于stringCount和styleCount的值,而每一个元素的类型都是无符号整型。整个字符中资源池结构如下。

字符串资源池中的字符串前两个字节为字符串长度,长度计算方法如下。另外如果字符串编码格式为UTF-8则字符串以0X00作为结束符,UTF-16则以0X0000作为结束符。
len = (((hbyte & 0x7F) << 8)) | lbyte;
字符串与字符串样式有一一对应的关系,也就是说如果第n个字符串有样式,则它的样式描述位于样式块的第n个元素。 字符串样式的结构包括如下两个结构体,ResStringPool_ref和ResStringPool_span。 一个字符串可以对应多个ResStringPool_span和一个ResStringPool_ref。ResStringPool_span在前描述字符串的样式,ResStringPool_ref在后固定值为0XFFFFFFFF作为占位符。样式块最后会以两个值为0XFFFFFFFF的ResStringPool_ref作为结束。
package com.wjdiankong.parseresource.type;
/**
struct ResStringPool_ref
{
uint32_t index;
};
- @author i
*/
public class ResStringPoolRef {
public int index;
public int getSize(){
return 4;
}
@Override
public String toString(){
return "index:"+index;
}
}
实例:

图中蓝色高亮的部分就是样式内容块,按照格式解析可以得出,第一个字符串和第二字符串无样式,第三个字符串第4个字符到第7个字符的位置样式为字符串资源池中0X1F88的字符,以此类推。
第四、Package数据块
接着资源项的值字符串资源池后面的部分就是Package数据块,这个数据块记录编译包的元数据,头部结构如下:
package com.wjdiankong.parseresource.type;
/**
struct ResTable_package
{
struct ResChunk_header header;
// If this is a base package, its ID. Package IDs start
// at 1 (corresponding to the value of the package bits in a
// resource identifier). 0 means this is not a base package.
uint32_t id;
// Actual name of this package, \0-terminated.
char16_t name[128];
// Offset to a ResStringPool_header defining the resource
// type symbol table. If zero, this package is inheriting from
// another base package (overriding specific values in it).
uint32_t typeStrings;
// Last index into typeStrings that is for public use by others.
uint32_t lastPublicType;
// Offset to a ResStringPool_header defining the resource
// key symbol table. If zero, this package is inheriting from
// another base package (overriding specific values in it).
uint32_t keyStrings;
// Last index into keyStrings that is for public use by others.
uint32_t lastPublicKey;
};
- @author i
*/
public class ResTablePackage {
public ResChunkHeader header;
public int id;
public char[] name = new char[128];
public int typeStrings;
public int lastPublicType;
public int keyStrings;
public int lastPublicKey;
public ResTablePackage(){
header = new ResChunkHeader();
}
@Override
public String toString(){
return "header:"+header.toString()+"\n"+",id="+id+",name:"+name.toString()+",typeStrings:"+typeStrings+",lastPublicType:"+lastPublicType+",keyStrings:"+keyStrings+",lastPublicKey:"+lastPublicKey;
}
}
header:Chunk的头部信息数据结构
id:包的ID,等于Package Id,一般用户包的值Package Id为0X7F,系统资源包的Package Id为0X01;这个值很重要的,在后面我们构建前面说到的那个public.xml中的id值的时候需要用到。
name:包名
typeString:类型字符串资源池相对头部的偏移
lastPublicType:最后一个导出的Public类型字符串在类型字符串资源池中的索引,目前这个值设置为类型字符串资源池的元素个数。在解析的过程中没发现他的用途
keyStrings:资源项名称字符串相对头部的偏移
lastPublicKey:最后一个导出的Public资源项名称字符串在资源项名称字符串资源池中的索引,目前这个值设置为资源项名称字符串资源池的元素个数。在解析的过程中没发现他的用途
实例:

图中紫色高亮的部分就是ResTable_package,按照上面的格式解析数据,我们可以得出,此Chunk的Type为RES_TABLE_PACKAGE_TYPE,头部大小为0X120,整个chunk的大小为1030716byte,Package Id为0X7F,包名称为co.runner.app,类型字符串资源池距离头部的偏移是0X120,有15条字符串,资源项名称字符串资源池0X1EC,有6249条字符串。
Packege数据块的整体结构,可以用以下的示意图表示:

其中Type String Pool和Key String Pool是两个字符串资源池,结构和资源项的值字符串资源池结构相同,分别对应类型字符串资源池和资源项名称字符串资源池。
再接下来的结构体可能是类型规范数据块或者类型资源项数据块,我们可以通过他们的Type来识别,类型规范数据块的Type为RES_TABLE_TYPE_SPEC_TYPE,类型资源项数据块的Type为RES_TABLE_TYPE_TYPE。
第五、类型规范数据块
类型规范数据块用来描述资源项的配置差异性。通过这个差异性描述,我们就可以知道每一个资源项的配置状况。知道了一个资源项的配置状况之后,Android资源管理框架在检测到设备的配置信息发生变化之后,就可以知道是否需要重新加载该资源项。类型规范数据块是按照类型来组织的,也就是说,每一种类型都对应有一个类型规范数据块。其数据块头部结构如下。
package com.wjdiankong.parseresource.type;
/**
struct ResTable_typeSpec
{
struct ResChunk_header header;
// The type identifier this chunk is holding. Type IDs start
// at 1 (corresponding to the value of the type bits in a
// resource identifier). 0 is invalid.
uint8_t id;
// Must be 0.
uint8_t res0;
// Must be 0.
uint16_t res1;
// Number of uint32_t entry configuration masks that follow.
uint32_t entryCount;
enum {
// Additional flag indicating an entry is public.
SPEC_PUBLIC = 0x40000000
};
};
- @author i
*/
public class ResTableTypeSpec {
public final static int SPEC_PUBLIC = 0x40000000;
public ResChunkHeader header;
public byte id;
public byte res0;
public short res1;
public int entryCount;
public ResTableTypeSpec(){
header = new ResChunkHeader();
}
@Override
public String toString(){
return "header:"+header.toString()+",id:"+id+",res0:"+res0+",res1:"+res1+",entryCount:"+entryCount;
}
}
header:Chunk的头部信息结构
id:标识资源的Type ID,Type ID是指资源的类型ID。资源的类型有animator、anim、color、drawable、layout、menu、raw、string和xml等等若干种,每一种都会被赋予一个ID。
res0:保留,始终为0
res1:保留,始终为0
entryCount:等于本类型的资源项个数,指名称相同的资源项的个数。
实例:
![]()
图中绿色高亮的部分就是ResTable_typeSpec,按照上面的格式解析数据,我们可以得出,此Chunk的Type为RES_TABLE_TYPE_SPEC_TYPE,头部大小为0X10,整个chunk的大小为564byte,资源ID为1,本类型资源项数量为137。
ResTable_typeSpec后面紧跟着的是一个大小为entryCount的uint32_t数组,每一个数组元素都用来描述一个资源项的配置差异性的。
第六、资源类型项数据块
类型资源项数据块用来描述资源项的具体信息, 这样我们就可以知道每一个资源项的名称、值和配置等信息。 类型资源项数据同样是按照类型和配置来组织的,也就是说,一个具有n个配置的类型一共对应有n个类型资源项数据块。其数据块头部结构如下
package com.wjdiankong.parseresource.type;
/**
struct ResTable_type
{
struct ResChunk_header header;
enum {
NO_ENTRY = 0xFFFFFFFF
};
// The type identifier this chunk is holding. Type IDs start
// at 1 (corresponding to the value of the type bits in a
// resource identifier). 0 is invalid.
uint8_t id;
// Must be 0.
uint8_t res0;
// Must be 0.
uint16_t res1;
// Number of uint32_t entry indices that follow.
uint32_t entryCount;
// Offset from header where ResTable_entry data starts.
uint32_t entriesStart;
// Configuration this collection of entries is designed for.
ResTable_config config;
};
- @author i
*/
public class ResTableType {
public ResChunkHeader header;
public final static int NO_ENTRY = 0xFFFFFFFF;
public byte id;
public byte res0;
public short res1;
public int entryCount;
public int entriesStart;
public ResTableConfig resConfig;
public ResTableType(){
header = new ResChunkHeader();
resConfig = new ResTableConfig();
}
public int getSize(){
return header.getHeaderSize() + 1 + 1 + 2 + 4 + 4;
}
@Override
public String toString(){
return "header:"+header.toString()+",id:"+id+",res0:"+res0+",res1:"+res1+",entryCount:"+entryCount+",entriesStart:"+entriesStart;
}
}
header:Chunk的头部信息结构
id:标识资源的Type ID
res0:保留,始终为0
res1:保留,始终为0
entryCount:等于本类型的资源项个数,指名称相同的资源项的个数。
entriesStart:等于资源项数据块相对头部的偏移值。
resConfig:指向一个ResTable_config,用来描述配置信息,地区,语言,分辨率等
实例:

图中红色高亮的部分就是ResTable_type,按照上面的格式解析数据,我们可以得出,RES_TABLE_TYPE_TYPE,头部大小为0X44,整个chunk的大小为4086byte,资源ID为1,本类型资源项数量为137,资源数据块相对于头部的偏移为0X268。
ResTable_type后接着是一个大小为entryCount的uint32_t数组,每一个数组元素都用来描述一个资源项数据块的偏移位置。 紧跟在这个偏移数组后面的是一个大小为entryCount的ResTable_entry数组,每一个数组元素都用来描述一个资源项的具体信息。ResTable_entry的结构如下:
package com.wjdiankong.parseresource.type;
import com.wjdiankong.parseresource.ParseResourceUtils;
/**
struct ResTable_entry
{
// Number of bytes in this structure.
uint16_t size;
enum {
// If set, this is a complex entry, holding a set of name/value
// mappings. It is followed by an array of ResTable_map structures.
FLAG_COMPLEX = 0x0001,
// If set, this resource has been declared public, so libraries
// are allowed to reference it.
FLAG_PUBLIC = 0x0002
};
uint16_t flags;
// Reference into ResTable_package::keyStrings identifying this entry.
struct ResStringPool_ref key;
};
- @author i
*/
public class ResTableEntry {
public final static int FLAG_COMPLEX = 0x0001;
public final static int FLAG_PUBLIC = 0x0002;
public short size;
public short flags;
public ResStringPoolRef key;
public ResTableEntry(){
key = new ResStringPoolRef();
}
public int getSize(){
return 2+2+key.getSize();
}
@Override
public String toString(){
return "size:"+size+",flags:"+flags+",key:"+key.toString()+",str:"+ParseResourceUtils.getKeyString(key.index);
}
}
ResTable_entry根据flags的不同,后面跟随的数据也不相同,如果flags此位为1,则ResTable_entry是ResTable_map_entry,ResTable_map_entry继承自ResTable_entry,其结构如下。
package com.wjdiankong.parseresource.type;
/**
struct ResTable_map_entry : public ResTable_entry
{
//指向父ResTable_map_entry的资源ID,如果没有父ResTable_map_entry,则等于0。
ResTable_ref parent;
//等于后面ResTable_map的数量
uint32_t count;
};
- @author i
*/
public class ResTableMapEntry extends ResTableEntry{
public ResTableRef parent;
public int count;
public ResTableMapEntry(){
parent = new ResTableRef();
}
@Override
public int getSize(){
return super.getSize() + parent.getSize() + 4;
}
@Override
public String toString(){
return super.toString() + ",parent:"+parent.toString()+",count:"+count;
}
}
ResTable_map_entry其后跟随则count个ResTable_map类型的数组,ResTable_map的结构如下:
package com.wjdiankong.parseresource.type;
/**
struct ResTable_map
{
//bag资源项ID
ResTable_ref name;
//bag资源项值
Res_value value;
};
- @author i
*/
public class ResTableMap {
public ResTableRef name;
public ResValue value;
public ResTableMap(){
name = new ResTableRef();
value = new ResValue();
}
public int getSize(){
return name.getSize() + value.getSize();
}
@Override
public String toString(){
return name.toString()+",value:"+value.toString();
}
}
实例:
![]()
图中颜色由深到浅就是一个完整的flags为1的资源项,现在就一起来解读这段数据的含义,这个资源项头部的大小为0X10,flags为1所以后面跟随的是ResTable_map数组,名称没有在资源项引用池中,没有父map_entry,有一个ResTable_map。
如果flags此位为0,则ResTable_entry其后跟随的是一个Res_value,描述一个普通资源的值,Res_value结构如下。
package com.wjdiankong.parseresource.type;
import com.wjdiankong.parseresource.ParseResourceUtils;
/**
struct Res_value
{
//Res_value头部大小
uint16_t size;
//保留,始终为0
uint8_t res0;
enum {
TYPE_NULL = 0x00,
TYPE_REFERENCE = 0x01,
TYPE_ATTRIBUTE = 0x02,
TYPE_STRING = 0x03,
TYPE_FLOAT = 0x04,
TYPE_DIMENSION = 0x05,
TYPE_FRACTION = 0x06,
TYPE_FIRST_INT = 0x10,
TYPE_INT_DEC = 0x10,
TYPE_INT_HEX = 0x11,
TYPE_INT_BOOLEAN = 0x12,
TYPE_FIRST_COLOR_INT = 0x1c,
TYPE_INT_COLOR_ARGB8 = 0x1c,
TYPE_INT_COLOR_ARGB8 = 0x1c,
TYPE_INT_COLOR_RGB8 = 0x1d,
TYPE_INT_COLOR_ARGB4 = 0x1e,
TYPE_INT_COLOR_RGB4 = 0x1f,
TYPE_LAST_COLOR_INT = 0x1f,
TYPE_LAST_INT = 0x1f
};
//数据的类型,可以从上面的枚举类型中获取
uint8_t dataType;
//数据对应的索引
uint32_t data;
};
- @author i
*/
public class ResValue {
//dataType字段使用的常量
public final static int TYPE_NULL = 0x00;
public final static int TYPE_REFERENCE = 0x01;
public final static int TYPE_ATTRIBUTE = 0x02;
public final static int TYPE_STRING = 0x03;
public final static int TYPE_FLOAT = 0x04;
public final static int TYPE_DIMENSION = 0x05;
public final static int TYPE_FRACTION = 0x06;
public final static int TYPE_FIRST_INT = 0x10;
public final static int TYPE_INT_DEC = 0x10;
public final static int TYPE_INT_HEX = 0x11;
public final static int TYPE_INT_BOOLEAN = 0x12;
public final static int TYPE_FIRST_COLOR_INT = 0x1c;
public final static int TYPE_INT_COLOR_ARGB8 = 0x1c;
public final static int TYPE_INT_COLOR_RGB8 = 0x1d;
public final static int TYPE_INT_COLOR_ARGB4 = 0x1e;
public final static int TYPE_INT_COLOR_RGB4 = 0x1f;
public final static int TYPE_LAST_COLOR_INT = 0x1f;
public final static int TYPE_LAST_INT = 0x1f;
public static final int
COMPLEX_UNIT_PX =0,
COMPLEX_UNIT_DIP =1,
COMPLEX_UNIT_SP =2,
COMPLEX_UNIT_PT =3,
COMPLEX_UNIT_IN =4,
COMPLEX_UNIT_MM =5,
COMPLEX_UNIT_SHIFT =0,
COMPLEX_UNIT_MASK =15,
COMPLEX_UNIT_FRACTION =0,
COMPLEX_UNIT_FRACTION_PARENT=1,
COMPLEX_RADIX_23p0 =0,
COMPLEX_RADIX_16p7 =1,
COMPLEX_RADIX_8p15 =2,
COMPLEX_RADIX_0p23 =3,
COMPLEX_RADIX_SHIFT =4,
COMPLEX_RADIX_MASK =3,
COMPLEX_MANTISSA_SHIFT =8,
COMPLEX_MANTISSA_MASK =0xFFFFFF;
public short size;
public byte res0;
public byte dataType;
public int data;
public int getSize(){
return 2 + 1 + 1 + 4;
}
public String getTypeStr(){
switch(dataType){
case TYPE_NULL:
return "TYPE_NULL";
case TYPE_REFERENCE:
return "TYPE_REFERENCE";
case TYPE_ATTRIBUTE:
return "TYPE_ATTRIBUTE";
case TYPE_STRING:
return "TYPE_STRING";
case TYPE_FLOAT:
return "TYPE_FLOAT";
case TYPE_DIMENSION:
return "TYPE_DIMENSION";
case TYPE_FRACTION:
return "TYPE_FRACTION";
case TYPE_FIRST_INT:
return "TYPE_FIRST_INT";
case TYPE_INT_HEX:
return "TYPE_INT_HEX";
case TYPE_INT_BOOLEAN:
return "TYPE_INT_BOOLEAN";
case TYPE_FIRST_COLOR_INT:
return "TYPE_FIRST_COLOR_INT";
case TYPE_INT_COLOR_RGB8:
return "TYPE_INT_COLOR_RGB8";
case TYPE_INT_COLOR_ARGB4:
return "TYPE_INT_COLOR_ARGB4";
case TYPE_INT_COLOR_RGB4:
return "TYPE_INT_COLOR_RGB4";
}
return "";
}
/*public String getDataStr(){
if(dataType == TYPE_STRING){
return ParseResourceUtils.getResString(data);
}else if(dataType == TYPE_FIRST_COLOR_INT){
return Utils.bytesToHexString(Utils.int2Byte(data));
}else if(dataType == TYPE_INT_BOOLEAN){
return data==0 ? "false" : "true";
}
return data+"";
}*/
public String getDataStr() {
if (dataType == TYPE_STRING) {
return ParseResourceUtils.getResString(data);
}
if (dataType == TYPE_ATTRIBUTE) {
return String.format("?%s%08X",getPackage(data),data);
}
if (dataType == TYPE_REFERENCE) {
return String.format("@%s%08X",getPackage(data),data);
}
if (dataType == TYPE_FLOAT) {
return String.valueOf(Float.intBitsToFloat(data));
}
if (dataType == TYPE_INT_HEX) {
return String.format("0x%08X",data);
}
if (dataType == TYPE_INT_BOOLEAN) {
return data!=0?"true":"false";
}
if (dataType == TYPE_DIMENSION) {
return Float.toString(complexToFloat(data))+
DIMENSION_UNITS[data & COMPLEX_UNIT_MASK];
}
if (dataType == TYPE_FRACTION) {
return Float.toString(complexToFloat(data))+
FRACTION_UNITS[data & COMPLEX_UNIT_MASK];
}
if (dataType >= TYPE_FIRST_COLOR_INT && dataType <= TYPE_LAST_COLOR_INT) {
return String.format("#%08X",data);
}
if (dataType >= TYPE_FIRST_INT && dataType <= TYPE_LAST_INT) {
return String.valueOf(data);
}
return String.format("<0x%X, type 0x%02X>",data, dataType);
}
private static String getPackage(int id) {
if (id>>>24==1) {
return "android:";
}
return "";
}
public static float complexToFloat(int complex) {
return (float)(complex & 0xFFFFFF00)*RADIX_MULTS[(complex>>4) & 3];
}
private static final float RADIX_MULTS[]={
0.00390625F,3.051758E-005F,1.192093E-007F,4.656613E-010F
};
private static final String DIMENSION_UNITS[]={
"px","dip","sp","pt","in","mm","",""
};
private static final String FRACTION_UNITS[]={
"%","%p","","","","","",""
};
@Override
public String toString(){
return "size:"+size+",res0:"+res0+",dataType:"+getTypeStr()+",data:"+getDataStr();
}
}
size:ResValue的头部大小
res0:保留,始终为0
dataType:数据的类型,可以从上面的枚举类型中获取
data:数据对应的索引
这里我们看到了有一个转化的方法,这个我们在解析AndroidManifest文件的时候也用到了这个方法。
实例:
图中画红线的部分就是一个ResTable_entry其后跟随的是一个Res_value的例子,从中我们可以得出以下信息,这个头部大小为8,flags等于0,所以后面跟随的是Res_value,在资源项名称字符串资源池中的索引为150,对应的值是badge_continue_months,Res_value的大小为8,数据的类型是TYPE_STRING,在资源项的值字符串资源池的索引为1912,对应的值是res/drawable-nodpi-v4/badge_continue_months.png。
当我们对arsc的文件格式有了了解过后,我们就可以开始我们的探索之旅了,由于在使用Android studio调试Apktool源码的时候遇到很多障碍,在前辈的指导下才能够顺利进行调试,所以下面简单介绍下设置Android studio调试Apktool源码的方法。
![]()
四、解析代码分析
因为篇幅的原因,这里就不把所有的代码都粘贴出来了,后面会列出来代码下载地址
package com.wjdiankong.parseresource;
import java.io.ByteArrayOutputStream;
import java.io.FileInputStream;
public class ParseResourceMain {
public static void main(String[] args){
byte[] srcByte = null;
FileInputStream fis = null;
ByteArrayOutputStream bos = null;
try{
fis = new FileInputStream("resource/resources_gdt1.arsc");
bos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while((len=fis.read(buffer)) != -1){
bos.write(buffer, 0, len);
}
srcByte = bos.toByteArray();
}catch(Exception e){
System.out.println("read res file error:"+e.toString());
}finally{
try{
fis.close();
bos.close();
}catch(Exception e){
System.out.println("close file error:"+e.toString());
}
}
if(srcByte == null){
System.out.println("get src error...");
return;
}
System.out.println("parse restable header...");
ParseResourceUtils.parseResTableHeaderChunk(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
System.out.println("parse resstring pool chunk...");
ParseResourceUtils.parseResStringPoolChunk(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
System.out.println("parse package chunk...");
ParseResourceUtils.parsePackage(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
System.out.println("parse typestring pool chunk...");
ParseResourceUtils.parseTypeStringPoolChunk(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
System.out.println("parse keystring pool chunk...");
ParseResourceUtils.parseKeyStringPoolChunk(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
int resCount = 0;
while(!ParseResourceUtils.isEnd(srcByte.length)){
resCount++;
boolean isSpec = ParseResourceUtils.isTypeSpec(srcByte);
if(isSpec){
System.out.println("parse restype spec chunk...");
ParseResourceUtils.parseResTypeSpec(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
}else{
System.out.println("parse restype info chunk...");
ParseResourceUtils.parseResTypeInfo(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
}
}
System.out.println("res count:"+resCount);
}
}
我们看到代码,首先我们读取resource.arsc文件到一个byte数组,然后开始解析。
第一、解析头部信息
/** * 解析头部信息 * @param src */ public static void parseResTableHeaderChunk(byte[] src){ ResTableHeader resTableHeader = new ResTableHeader();resTableHeader.header = parseResChunkHeader(src, 0); resStringPoolChunkOffset = resTableHeader.header.headerSize; //解析PackageCount个数(一个apk可能包含多个Package资源) byte[] packageCountByte = Utils.copyByte(src, resTableHeader.header.getHeaderSize(), 4); resTableHeader.packageCount = Utils.byte2int(packageCountByte);
}
解析结果:

第二、解析资源字符串内容
/**
* 解析Resource.arsc文件中所有字符串内容
* @param src
*/
public static void parseResStringPoolChunk(byte[] src){
ResStringPoolHeader stringPoolHeader = parseStringPoolChunk(src, resStringList, resStringPoolChunkOffset);
packageChunkOffset = resStringPoolChunkOffset + stringPoolHeader.header.size;
}这里有一个核心的方法:parseStringPoolChunk
/** * 统一解析字符串内容 * @param src * @param stringList * @param stringOffset * @return */ public static ResStringPoolHeader parseStringPoolChunk(byte[] src, ArrayListstringList, int stringOffset){ ResStringPoolHeader stringPoolHeader = new ResStringPoolHeader(); //解析头部信息 stringPoolHeader.header = parseResChunkHeader(src, stringOffset); System.out.println("header size:"+stringPoolHeader.header.headerSize); System.out.println("size:"+stringPoolHeader.header.size); int offset = stringOffset + stringPoolHeader.header.getHeaderSize(); //获取字符串的个数 byte[] stringCountByte = Utils.copyByte(src, offset, 4); stringPoolHeader.stringCount = Utils.byte2int(stringCountByte); //解析样式的个数 byte[] styleCountByte = Utils.copyByte(src, offset+4, 4); stringPoolHeader.styleCount = Utils.byte2int(styleCountByte); //这里表示字符串的格式:UTF-8/UTF-16 byte[] flagByte = Utils.copyByte(src, offset+8, 4); System.out.println("flag:"+Utils.bytesToHexString(flagByte)); stringPoolHeader.flags = Utils.byte2int(flagByte); //字符串内容的开始位置 byte[] stringStartByte = Utils.copyByte(src, offset+12, 4); stringPoolHeader.stringsStart = Utils.byte2int(stringStartByte); System.out.println("string start:"+Utils.bytesToHexString(stringStartByte)); //样式内容的开始位置 byte[] sytleStartByte = Utils.copyByte(src, offset+16, 4); stringPoolHeader.stylesStart = Utils.byte2int(sytleStartByte); System.out.println("style start:"+Utils.bytesToHexString(sytleStartByte)); //获取字符串内容的索引数组和样式内容的索引数组 int[] stringIndexAry = new int[stringPoolHeader.stringCount]; int[] styleIndexAry = new int[stringPoolHeader.styleCount]; System.out.println("string count:"+stringPoolHeader.stringCount); System.out.println("style count:"+stringPoolHeader.styleCount); int stringIndex = offset + 20; for(int i=0;i<stringPoolHeader.stringCount;i++){ stringIndexAry[i] = Utils.byte2int(Utils.copyByte(src, stringIndex+i*4, 4)); } int styleIndex = stringIndex + 4*stringPoolHeader.stringCount; for(int i=0;i<stringPoolHeader.styleCount;i++){ styleIndexAry[i] = Utils.byte2int(Utils.copyByte(src, styleIndex+i*4, 4)); } //每个字符串的头两个字节的最后一个字节是字符串的长度 //这里获取所有字符串的内容 int stringContentIndex = styleIndex + stringPoolHeader.styleCount*4; System.out.println("string index:"+Utils.bytesToHexString(Utils.int2Byte(stringContentIndex))); int index = 0; while(index < stringPoolHeader.stringCount){ byte[] stringSizeByte = Utils.copyByte(src, stringContentIndex, 2); int stringSize = (stringSizeByte[1] & 0x7F); if(stringSize != 0){ String val = ""; try{ val = new String(Utils.copyByte(src, stringContentIndex+2, stringSize), "utf-8"); }catch(Exception e){ System.out.println("string encode error:"+e.toString()); } stringList.add(val); }else{ stringList.add(""); } stringContentIndex += (stringSize+3); index++; } for(String str : stringList){ System.out.println("str:"+str); } return stringPoolHeader;
}
这里在得到一个字符串的时候,需要得到字符串的开始位置和字符串的大小即可,这点和解析AndroidManifest.xml文件中的字符串原理是一样的,就是一个字符串块的头两个字节中的最后一个字节是字符串的长度。这里我们在解析完字符串之后,需要用一个列表将其存储起来,后面有用到,需要通过索引来取字符串内容。
解析结果:
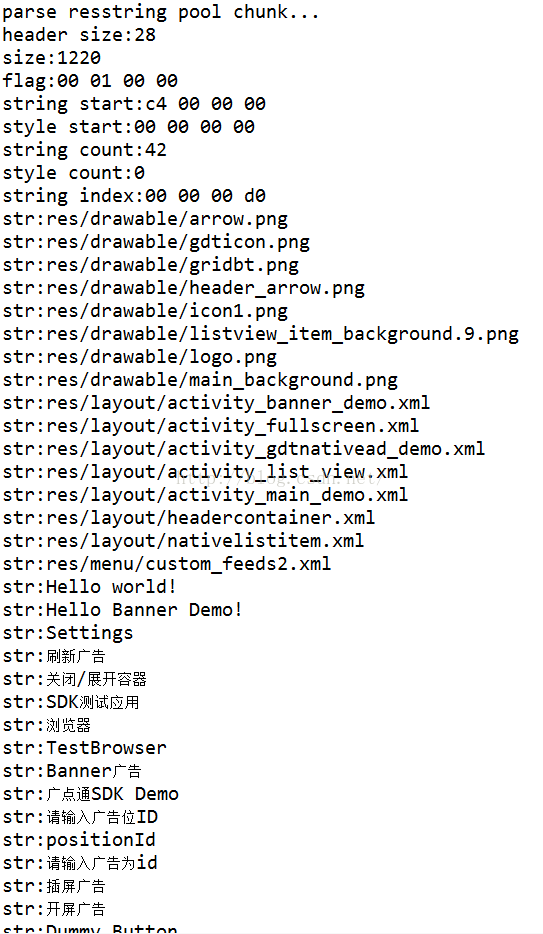
第三、解析包信息
/** * 解析Package信息 * @param src */ public static void parsePackage(byte[] src){ System.out.println("pchunkoffset:"+Utils.bytesToHexString(Utils.int2Byte(packageChunkOffset))); ResTablePackage resTabPackage = new ResTablePackage(); //解析头部信息 resTabPackage.header = parseResChunkHeader(src, packageChunkOffset);System.out.println("package size:"+resTabPackage.header.headerSize); int offset = packageChunkOffset + resTabPackage.header.getHeaderSize(); //解析packId byte[] idByte = Utils.copyByte(src, offset, 4); resTabPackage.id = Utils.byte2int(idByte); packId = resTabPackage.id; //解析包名 System.out.println("package offset:"+Utils.bytesToHexString(Utils.int2Byte(offset+4))); byte[] nameByte = Utils.copyByte(src, offset+4, 128*2);//这里的128是这个字段的大小,可以查看类型说明,是char类型的,所以要乘以2 String packageName = new String(nameByte); packageName = Utils.filterStringNull(packageName); System.out.println("pkgName:"+packageName); //解析类型字符串的偏移值 byte[] typeStringsByte = Utils.copyByte(src, offset+4+128*2, 4); resTabPackage.typeStrings = Utils.byte2int(typeStringsByte); System.out.println("typeString:"+resTabPackage.typeStrings); //解析lastPublicType字段 byte[] lastPublicType = Utils.copyByte(src, offset+8+128*2, 4); resTabPackage.lastPublicType = Utils.byte2int(lastPublicType); //解析keyString字符串的偏移值 byte[] keyStrings = Utils.copyByte(src, offset+12+128*2, 4); resTabPackage.keyStrings = Utils.byte2int(keyStrings); System.out.println("keyString:"+resTabPackage.keyStrings); //解析lastPublicKey byte[] lastPublicKey = Utils.copyByte(src, offset+12+128*2, 4); resTabPackage.lastPublicKey = Utils.byte2int(lastPublicKey); //这里获取类型字符串的偏移值和类型字符串的偏移值 keyStringPoolChunkOffset = (packageChunkOffset+resTabPackage.keyStrings); typeStringPoolChunkOffset = (packageChunkOffset+resTabPackage.typeStrings);
}
这里我们看到有一个特殊的地方,就是最后两行,这里需要得到我们后面需要重要解析的两个内容,一个是资源值字符串的偏移值和资源类型字符串的偏移值。
解析结果:

第四、解析资源类型的字符串内容
/**
* 解析类型字符串内容
* @param src
*/
public static void parseTypeStringPoolChunk(byte[] src){
System.out.println("typestring offset:"+Utils.bytesToHexString(Utils.int2Byte(typeStringPoolChunkOffset)));
ResStringPoolHeader stringPoolHeader = parseStringPoolChunk(src, typeStringList, typeStringPoolChunkOffset);
System.out.println("size:"+stringPoolHeader.header.size);
}这里也是用parseStringPoolChunk方法进行解析的,同样也需要用一个字符串列表存储内容
解析结果:

第五、解析资源值字符串内容
/**
* 解析key字符串内容
* @param src
*/
public static void parseKeyStringPoolChunk(byte[] src){
System.out.println("keystring offset:"+Utils.bytesToHexString(Utils.int2Byte(keyStringPoolChunkOffset)));
ResStringPoolHeader stringPoolHeader = parseStringPoolChunk(src, keyStringList, keyStringPoolChunkOffset);
System.out.println("size:"+stringPoolHeader.header.size);
//解析完key字符串之后,需要赋值给resType的偏移值,后续还需要继续解析
resTypeOffset = (keyStringPoolChunkOffset+stringPoolHeader.header.size);
}这里也是一样,使用parseStringPoolChunk方法来解析,解析完之后需要用一个字符串列表保存,后面需要使用索引值来访问
解析结果:

第六、解析正文内容
这里说到的正文内容就是ResValue值,也就是开始构建public.xml中的条目信息,和类型的分离不同的xml文件,所以这部分的内容的解析工作有点复杂
int resCount = 0;
while(!ParseResourceUtils.isEnd(srcByte.length)){
resCount++;
boolean isSpec = ParseResourceUtils.isTypeSpec(srcByte);
if(isSpec){
System.out.println("parse restype spec chunk...");
ParseResourceUtils.parseResTypeSpec(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
}else{
System.out.println("parse restype info chunk...");
ParseResourceUtils.parseResTypeInfo(srcByte);
System.out.println("++++++++++++++++++++++++++++++++++++++");
System.out.println();
}
}
System.out.println("res count:"+resCount);这里有一个循环解析,有两个方法,一个是isEnd方法,一个是isTypeSpec方法
我们如果仔细看上面的那张神图的话,就可以看到,后面的ResType和ResTypeSpec他们两个内容是交替出现的,直到文件结束。
所以isEnd方法就是判断是否到达文件结束位置:
/**
* 判断是否到文件末尾了
* @param length
* @return
*/
public static boolean isEnd(int length){
if(resTypeOffset>=length){
return true;
}
return false;
}还有一个方法就是判断是ResType还是ResTypeSpec,这个可以通过Chunk中头部信息来区分的:
/**
* 判断是不是类型描述符
* @param src
* @return
*/
public static boolean isTypeSpec(byte[] src){
ResChunkHeader header = parseResChunkHeader(src, resTypeOffset);
if(header.type == 0x0202){
return true;
}
return false;
}那么就是分别来解析ResTypeSpec和ResType这两个内容了:
1、解析ResTypeSpec
主要得到Res的每个类型名
/** * 解析ResTypeSepc类型描述内容 * @param src */ public static void parseResTypeSpec(byte[] src){ System.out.println("res type spec offset:"+Utils.bytesToHexString(Utils.int2Byte(resTypeOffset))); ResTableTypeSpec typeSpec = new ResTableTypeSpec(); //解析头部信息 typeSpec.header = parseResChunkHeader(src, resTypeOffset);int offset = (resTypeOffset + typeSpec.header.getHeaderSize()); //解析id类型 byte[] idByte = Utils.copyByte(src, offset, 1); typeSpec.id = (byte)(idByte[0] & 0xFF); resTypeId = typeSpec.id; //解析res0字段,这个字段是备用的,始终是0 byte[] res0Byte = Utils.copyByte(src, offset+1, 1); typeSpec.res0 = (byte)(res0Byte[0] & 0xFF); //解析res1字段,这个字段是备用的,始终是0 byte[] res1Byte = Utils.copyByte(src, offset+2, 2); typeSpec.res1 = Utils.byte2Short(res1Byte); //entry的总个数 byte[] entryCountByte = Utils.copyByte(src, offset+4, 4); typeSpec.entryCount = Utils.byte2int(entryCountByte); System.out.println("res type spec:"+typeSpec); System.out.println("type_name:"+typeStringList.get(typeSpec.id-1)); //获取entryCount个int数组 int[] intAry = new int[typeSpec.entryCount]; int intAryOffset = resTypeOffset + typeSpec.header.headerSize; System.out.print("int element:"); for(int i=0;i<typeSpec.entryCount;i++){ int element = Utils.byte2int(Utils.copyByte(src, intAryOffset+i*4, 4)); intAry[i] = element; System.out.print(element+","); } System.out.println(); resTypeOffset += typeSpec.header.size;
}
解析结果:

2、解析ResType
主要得到每个res类型的所有条目内容
/** * 解析类型信息内容 * @param src */ public static void parseResTypeInfo(byte[] src){ System.out.println("type chunk offset:"+Utils.bytesToHexString(Utils.int2Byte(resTypeOffset))); ResTableType type = new ResTableType(); //解析头部信息 type.header = parseResChunkHeader(src, resTypeOffset);int offset = (resTypeOffset + type.header.getHeaderSize()); //解析type的id值 byte[] idByte = Utils.copyByte(src, offset, 1); type.id = (byte)(idByte[0] & 0xFF); //解析res0字段的值,备用字段,始终是0 byte[] res0 = Utils.copyByte(src, offset+1, 1); type.res0 = (byte)(res0[0] & 0xFF); //解析res1字段的值,备用字段,始终是0 byte[] res1 = Utils.copyByte(src, offset+2, 2); type.res1 = Utils.byte2Short(res1); byte[] entryCountByte = Utils.copyByte(src, offset+4, 4); type.entryCount = Utils.byte2int(entryCountByte); byte[] entriesStartByte = Utils.copyByte(src, offset+8, 4); type.entriesStart = Utils.byte2int(entriesStartByte); ResTableConfig resConfig = new ResTableConfig(); resConfig = parseResTableConfig(Utils.copyByte(src, offset+12, resConfig.getSize())); System.out.println("config:"+resConfig); System.out.println("res type info:"+type); System.out.println("type_name:"+typeStringList.get(type.id-1)); //先获取entryCount个int数组 System.out.print("type int elements:"); int[] intAry = new int[type.entryCount]; for(int i=0;i<type.entryCount;i++){ int element = Utils.byte2int(Utils.copyByte(src, resTypeOffset+type.header.headerSize+i*4, 4)); intAry[i] = element; System.out.print(element+","); } System.out.println(); //这里开始解析后面对应的ResEntry和ResValue int entryAryOffset = resTypeOffset + type.entriesStart; ResTableEntry[] tableEntryAry = new ResTableEntry[type.entryCount]; ResValue[] resValueAry = new ResValue[type.entryCount]; System.out.println("entry offset:"+Utils.bytesToHexString(Utils.int2Byte(entryAryOffset))); //这里存在一个问题就是如果是ResMapEntry的话,偏移值是不一样的,所以这里需要计算不同的偏移值 int bodySize = 0, valueOffset = entryAryOffset; for(int i=0;i<type.entryCount;i++){ int resId = getResId(i); System.out.println("resId:"+Utils.bytesToHexString(Utils.int2Byte(resId))); ResTableEntry entry = new ResTableEntry(); ResValue value = new ResValue(); valueOffset += bodySize; System.out.println("valueOffset:"+Utils.bytesToHexString(Utils.int2Byte(valueOffset))); entry = parseResEntry(Utils.copyByte(src, valueOffset, entry.getSize())); //这里需要注意的是,先判断entry的flag变量是否为1,如果为1的话,那就ResTable_map_entry if(entry.flags == 1){ //这里是复杂类型的value ResTableMapEntry mapEntry = new ResTableMapEntry(); mapEntry = parseResMapEntry(Utils.copyByte(src, valueOffset, mapEntry.getSize())); System.out.println("map entry:"+mapEntry); ResTableMap resMap = new ResTableMap(); for(int j=0;j<mapEntry.count;j++){ int mapOffset = valueOffset + mapEntry.getSize() + resMap.getSize()*j; resMap = parseResTableMap(Utils.copyByte(src, mapOffset, resMap.getSize())); System.out.println("map:"+resMap); } bodySize = mapEntry.getSize() + resMap.getSize()*mapEntry.count; }else{ System.out.println("entry:"+entry); //这里是简单的类型的value value = parseResValue(Utils.copyByte(src, valueOffset+entry.getSize(), value.getSize())); System.out.println("value:"+value); bodySize = entry.getSize()+value.getSize(); } tableEntryAry[i] = entry; resValueAry[i] = value; System.out.println("======================================"); } resTypeOffset += type.header.size;
}
/**
-
解析ResEntry内容
-
@param src
-
@return
*/
public static ResTableEntry parseResEntry(byte[] src){
ResTableEntry entry = new ResTableEntry();byte[] sizeByte = Utils.copyByte(src, 0, 2);
entry.size = Utils.byte2Short(sizeByte);byte[] flagByte = Utils.copyByte(src, 2, 2);
entry.flags = Utils.byte2Short(flagByte);ResStringPoolRef key = new ResStringPoolRef();
byte[] keyByte = Utils.copyByte(src, 4, 4);
key.index = Utils.byte2int(keyByte);
entry.key = key;return entry;
}
/**
-
解析ResMapEntry内容
-
@param src
-
@return
*/
public static ResTableMapEntry parseResMapEntry(byte[] src){
ResTableMapEntry entry = new ResTableMapEntry();byte[] sizeByte = Utils.copyByte(src, 0, 2);
entry.size = Utils.byte2Short(sizeByte);byte[] flagByte = Utils.copyByte(src, 2, 2);
entry.flags = Utils.byte2Short(flagByte);ResStringPoolRef key = new ResStringPoolRef();
byte[] keyByte = Utils.copyByte(src, 4, 4);
key.index = Utils.byte2int(keyByte);
entry.key = key;ResTableRef ref = new ResTableRef();
byte[] identByte = Utils.copyByte(src, 8, 4);
ref.ident = Utils.byte2int(identByte);
entry.parent = ref;
byte[] countByte = Utils.copyByte(src, 12, 4);
entry.count = Utils.byte2int(countByte);return entry;
}
/**
-
解析ResValue内容
-
@param src
-
@return
*/
public static ResValue parseResValue(byte[] src){
ResValue resValue = new ResValue();
byte[] sizeByte = Utils.copyByte(src, 0, 2);
resValue.size = Utils.byte2Short(sizeByte);byte[] res0Byte = Utils.copyByte(src, 2, 1);
resValue.res0 = (byte)(res0Byte[0] & 0xFF);byte[] dataType = Utils.copyByte(src, 3, 1);
resValue.dataType = (byte)(dataType[0] & 0xFF);byte[] data = Utils.copyByte(src, 4, 4);
resValue.data = Utils.byte2int(data);return resValue;
}
/**
-
解析ResTableMap内容
-
@param src
-
@return
*/
public static ResTableMap parseResTableMap(byte[] src){
ResTableMap tableMap = new ResTableMap();ResTableRef ref = new ResTableRef();
byte[] identByte = Utils.copyByte(src, 0, ref.getSize());
ref.ident = Utils.byte2int(identByte);
tableMap.name = ref;ResValue value = new ResValue();
value = parseResValue(Utils.copyByte(src, ref.getSize(), value.getSize()));
tableMap.value = value;return tableMap;
}
/**
-
解析ResTableConfig配置信息
-
@param src
-
@return
*/
public static ResTableConfig parseResTableConfig(byte[] src){
ResTableConfig config = new ResTableConfig();byte[] sizeByte = Utils.copyByte(src, 0, 4);
config.size = Utils.byte2int(sizeByte);//以下结构是Union
byte[] mccByte = Utils.copyByte(src, 4, 2);
config.mcc = Utils.byte2Short(mccByte);
byte[] mncByte = Utils.copyByte(src, 6, 2);
config.mnc = Utils.byte2Short(mncByte);
byte[] imsiByte = Utils.copyByte(src, 4, 4);
config.imsi = Utils.byte2int(imsiByte);//以下结构是Union
byte[] languageByte = Utils.copyByte(src, 8, 2);
config.language = languageByte;
byte[] countryByte = Utils.copyByte(src, 10, 2);
config.country = countryByte;
byte[] localeByte = Utils.copyByte(src, 8, 4);
config.locale = Utils.byte2int(localeByte);//以下结构是Union
byte[] orientationByte = Utils.copyByte(src, 12, 1);
config.orientation = orientationByte[0];
byte[] touchscreenByte = Utils.copyByte(src, 13, 1);
config.touchscreen = touchscreenByte[0];
byte[] densityByte = Utils.copyByte(src, 14, 2);
config.density = Utils.byte2Short(densityByte);
byte[] screenTypeByte = Utils.copyByte(src, 12, 4);
config.screenType = Utils.byte2int(screenTypeByte);//以下结构是Union
byte[] keyboardByte = Utils.copyByte(src, 16, 1);
config.keyboard = keyboardByte[0];
byte[] navigationByte = Utils.copyByte(src, 17, 1);
config.navigation = navigationByte[0];
byte[] inputFlagsByte = Utils.copyByte(src, 18, 1);
config.inputFlags = inputFlagsByte[0];
byte[] inputPad0Byte = Utils.copyByte(src, 19, 1);
config.inputPad0 = inputPad0Byte[0];
byte[] inputByte = Utils.copyByte(src, 16, 4);
config.input = Utils.byte2int(inputByte);//以下结构是Union
byte[] screenWidthByte = Utils.copyByte(src, 20, 2);
config.screenWidth = Utils.byte2Short(screenWidthByte);
byte[] screenHeightByte = Utils.copyByte(src, 22, 2);
config.screenHeight = Utils.byte2Short(screenHeightByte);
byte[] screenSizeByte = Utils.copyByte(src, 20, 4);
config.screenSize = Utils.byte2int(screenSizeByte);//以下结构是Union
byte[] sdVersionByte = Utils.copyByte(src, 24, 2);
config.sdVersion = Utils.byte2Short(sdVersionByte);
byte[] minorVersionByte = Utils.copyByte(src, 26, 2);
config.minorVersion = Utils.byte2Short(minorVersionByte);
byte[] versionByte = Utils.copyByte(src, 24, 4);
config.version = Utils.byte2int(versionByte);//以下结构是Union
byte[] screenLayoutByte = Utils.copyByte(src, 28, 1);
config.screenLayout = screenLayoutByte[0];
byte[] uiModeByte = Utils.copyByte(src, 29, 1);
config.uiMode = uiModeByte[0];
byte[] smallestScreenWidthDpByte = Utils.copyByte(src, 30, 2);
config.smallestScreenWidthDp = Utils.byte2Short(smallestScreenWidthDpByte);
byte[] screenConfigByte = Utils.copyByte(src, 28, 4);
config.screenConfig = Utils.byte2int(screenConfigByte);//以下结构是Union
byte[] screenWidthDpByte = Utils.copyByte(src, 32, 2);
config.screenWidthDp = Utils.byte2Short(screenWidthDpByte);
byte[] screenHeightDpByte = Utils.copyByte(src, 34, 2);
config.screenHeightDp = Utils.byte2Short(screenHeightDpByte);
byte[] screenSizeDpByte = Utils.copyByte(src, 32, 4);
config.screenSizeDp = Utils.byte2int(screenSizeDpByte);byte[] localeScriptByte = Utils.copyByte(src, 36, 4);
config.localeScript = localeScriptByte;byte[] localeVariantByte = Utils.copyByte(src, 40, 8);
config.localeVariant = localeVariantByte;
return config;
}
看到这里,我们发现这里的解析很复杂的,和我们在讲解数据结构的时候那里一样,他需要解析很多内容:
ResValue,ResTableMap,ResTableMapEntry,ResTableEntry,ResConfig
关于每个数据结构如何解析这里就不多说了,就是读取字节即可。这里有一个核心的代码:
//这里需要注意的是,先判断entry的flag变量是否为1,如果为1的话,那就ResTable_map_entry
if(entry.flags == 1){
//这里是复杂类型的value
ResTableMapEntry mapEntry = new ResTableMapEntry();
mapEntry = parseResMapEntry(Utils.copyByte(src, valueOffset, mapEntry.getSize()));
System.out.println("map entry:"+mapEntry);
ResTableMap resMap = new ResTableMap();
for(int j=0;j判断flag的值,来进行不同的解析操作。这里需要注意这点。
解析结果:

看到解析结果,还是挺欣慰的,因为最难的地方我们解析成功了,而且看到结果我们很激动,就是我们想要的结果,但是这里需要解释的是,有了这些值我们构建public.xml内容和各个类型的xml内容是很简单,当然这里我们去构建了,感兴趣的同学可以去尝试一下。
注意:这里的ResId的构造方法是:
/**
* 获取资源id
* 这里高位是packid,中位是restypeid,地位是entryid
* @param entryid
* @return
*/
public static int getResId(int entryid){
return (((packId)<<24) | (((resTypeId) & 0xFF)<<16) | (entryid & 0xFFFF));
}这里我们可以看到就是一个int类型的resId,
他的最高两个字节表示packId,系统资源id是:0x01,普通应用资源id是:0x7F
他的中间的两个字节表示resTypeId,类型id,这个值从0开始,比如我们例子中第一个类型是attr,那么他的resTypeId就是00
他的最低四个字节表示这个资源的顺序id,从1开始,逐渐累加1
项目下载地址:http://download.csdn.net/detail/jiangwei0910410003/9426712
五、技术概述
上面我们就很蛋疼的解析完了所有的resource.arsc文件,当然内容有点多,所以有些地方可能没介绍清楚或者是有错误的地方,请多指正。当然关于Android编译之后的四个文件格式,我们已经介绍了三个了:
so文件格式、AndroidManifest.xml格式/资源文件.xml、resource.arsc
那么剩下就只有classes.dex这一个文件格式了,我们就算大功告成了。但是我想在这里说的是,这篇文章我们主要是介绍解析resource.arsc文件格式,那么写这篇文章的目的是什么呢?
有两个:
1、我们在使用apktool工具进行反编译的时候,经常出现一些莫名的一场信息,最多的就是NotFound ResId 0x0000XXX这些内容,那么这时候我们就可以去修复了,当然我们可以得到apktool的源码来解决这个问题,还可以就是使用我们自己写的这套解析代码也是可以的。
2、我们之前提过,解析resource.arsc文件之后,对resource.arsc文件格式如果有了解了之后,可以对资源文件名进行混淆,从而来减小apk包大小,我在之前的一篇文章:
Apk的签名机制:http://blog.csdn.net/jiangwei0910410003/article/details/50402000
因为META-INF文件夹下的三个文件大小很大,原因就是他们内部保存了每个资源名称,我们在项目中有时候为了不造成冲突,就把资源名起的很长,那么这样就会导致apk的包很大。
同样resource.arsc文件也会很大,因为资源名都是需要保存的,但是我们知道Android中的混淆是不会对资源文件进行混淆的,所以这时候我们就可以通过这个思路来减小包apk的大小了。这个后续我会继续讲解的。
注意:
到这里我们还需要告诉一件事,那就是其实我们上面的解析工作,有一个更简单的方法就可以搞定了?那就是aapt命令?关于这个aapt是干啥的?网上有很多资料,他其实很简单就是将Android中的资源文件打包成resource.arsc即可:

只有那些类型为res/animator、res/anim、res/color、res/drawable(非Bitmap文件,即非.png、.9.png、.jpg、.gif文件)、res/layout、res/menu、res/values和res/xml的资源文件均会从文本格式的XML文件编译成二进制格式的XML文件
这些XML资源文件之所要从文本格式编译成二进制格式,是因为:
1. 二进制格式的XML文件占用空间更小。这是由于所有XML元素的标签、属性名称、属性值和内容所涉及到的字符串都会被统一收集到一个字符串资源池中去,并且会去重。有了这个字符串资源池,原来使用字符串的地方就会被替换成一个索引到字符串资源池的整数值,从而可以减少文件的大小。
2. 二进制格式的XML文件解析速度更快。这是由于二进制格式的XML元素里面不再包含有字符串值,因此就避免了进行字符串解析,从而提高速度。
将XML资源文件从文本格式编译成二进制格式解决了空间占用以及解析效率的问题,但是对于Android资源管理框架来说,这只是完成了其中的一部分工作。Android资源管理框架的另外一个重要任务就是要根据资源ID来快速找到对应的资源。
那么下面我们用aapt命令就可以查看一下?
aapt命令在我们的AndroidSdk目录中:

看到路径了:Android-SDK目录/build-tools/下面
我们也就知道了,这个目录下全是Android中build成一个apk的所有工具,这里再看一下这些工具的用途:

1、使用Android SDK提供的aapt.exe生成R.java类文件
2、使用Android SDK提供的aidl.exe把.aidl转成.java文件(如果没有aidl,则跳过这一步)
3、使用JDK提供的javac.exe编译.java类文件生成class文件
4、使用Android SDK提供的dx.bat命令行脚本生成classes.dex文件
5、使用Android SDK提供的aapt.exe生成资源包文件(包括res、assets、androidmanifest.xml等)
6、使用Android SDK提供的apkbuilder.bat生成未签名的apk安装文件
7、使用jdk的jarsigner.exe对未签名的包进行apk签名
看到了吧。我们原来可以不借助任何IDE工具,也是可以出一个apk包的。哈哈~~
继续看aapt命令的用法,命令很简单:
aapt l -a apk名称 > demo.txt
将输入的结果定向到demo.txt中

看到我们弄出来的内容,发现就是我们上面解析的AndroidManifest.xml内容,所以这个也是一个方法,当然aapt命令这里我为什么最后说呢?之前我们讲解的AndroidManifest.xml格式肯定是有用的,aapt命令只是系统提供给我们一个很好的工具,我们可以在反编译的过程中借助这个工具也是不错的选择。所以这里我就想说,以后我们记得有一个aapt命令就好了,他的用途还是很多的,可以单独编译成一个resource.arsc文件来,我们后面会用到这个命令。
六、总结
这篇文章篇幅有点长,所以我写的很蛋疼,但是得耐心的看,因为resource.arsc文件格式比AndroidManifest.xml文件格式复杂得多,所以解析起来很费劲的。也希望你们看完之后能多多支持,后面还有一篇解析classes.dex文件格式,当然这篇文章要等年后来才能动笔了,所以尽请期待,最好注大家新年快乐~~
关注微信公众号,最新Android技术实时推送

