机器学习:Parzen窗、k-nn
一、问题描述

1、考虑对于表格中的数据进行Parzen窗估计和设计分类器。窗函数为一个球形的高斯函数,如下所示:
![]()
(a)编写程序,使用Parzen窗估计方法对一个任意的测试样本点x进行分类。对分类器的训练则使用表格中的三维数据。同时令h=1,分类样本点为![]() ,
,![]() ,
,![]() 。
。
(b)现在我们令h=0.1,重复(a)。
2、考虑不同维数的空间中,使用k-近邻概率密度估计方法的效果。
(a)编写程序,对于一维的情况,当有![]() 个数据样本点时,进行k-近邻概率密度估计。对表格中的类别
个数据样本点时,进行k-近邻概率密度估计。对表格中的类别![]() 中的特征
中的特征![]() ,用程序画出当k=1,3,5时的概率密度估计结果。
,用程序画出当k=1,3,5时的概率密度估计结果。
(b)编写程序,对于二维的情况,当有![]() 个数据样本点时,进行k-近邻概率密度估计。对表格中的类别
个数据样本点时,进行k-近邻概率密度估计。对表格中的类别![]() 中的特征
中的特征![]() ,用程序画出当k=1,3,5时的概率密度估计结果。
,用程序画出当k=1,3,5时的概率密度估计结果。
(c)对表格中的3个类别的三维特征,使用k-邻近概率密度估计方法。并且对下列点处的概率密度进行估计:![]() ,
,![]()
![]() 。
。
二、算法核心思想分析
1、非参数化概率密度估计
对于未知概率密度函数的估计方法,核心思想是:一个向量![]() 落在区域
落在区域![]() 中的概率为
中的概率为
![]()
其中,![]() 是概率密度函数
是概率密度函数![]() 的平滑了的版本,因此,我们可以通过计算概率
的平滑了的版本,因此,我们可以通过计算概率![]() 来估计概率密度函数
来估计概率密度函数![]() 。假设
。假设![]() 个样本
个样本![]() 都是根据概率密度函数
都是根据概率密度函数![]() 独立同分布的抽取得到的。显然,其中
独立同分布的抽取得到的。显然,其中![]() 个样本落在区域
个样本落在区域![]() 中的概率服从二项式定理:
中的概率服从二项式定理:
![]()
![]() 的期望值为
的期望值为
![]()
![]() 的二项式形式的分布在均值附近有非常显著的波峰,因此,我们可以用比值
的二项式形式的分布在均值附近有非常显著的波峰,因此,我们可以用比值![]() 来估计概率
来估计概率![]() ,且当样本个数
,且当样本个数![]() 非常大的时候将非常准确。假设
非常大的时候将非常准确。假设![]() 是连续的,并且区域
是连续的,并且区域![]() 足够小,以至于在这个区间中
足够小,以至于在这个区间中![]() 几乎没有变化,那么有:
几乎没有变化,那么有:
![]()
其中![]() 为一个点,
为一个点,![]() 则是区域
则是区域![]() 所包含的体积,概率密度函数
所包含的体积,概率密度函数![]() 的估计为:
的估计为:
![]()
如下图所示:

为了估计点![]() 处的概率密度函数,构造一系列包含点
处的概率密度函数,构造一系列包含点![]() 的区域:
的区域:![]() 。第一个区域使用1个样本,第二个区域使用2个样本,以此类推。记
。第一个区域使用1个样本,第二个区域使用2个样本,以此类推。记![]() 为区域
为区域![]() 的体积,
的体积,![]() 为落在区域
为落在区域![]() 中的样本个数,而
中的样本个数,而![]() 表示对
表示对![]() 的第
的第![]() 次估计:
次估计:
![]()
如果要求![]() 能够收敛到
能够收敛到![]() ,需满足以下三个条件:
,需满足以下三个条件:
![]()
![]()
![]()
有两种经常采用的获得这种区域序列的途径,如下图所示。其中“Parzen窗方法”是根据某一个确定的体积函数,比如![]() ,来逐渐收缩一个给定的初始区间,这就要求随机变量
,来逐渐收缩一个给定的初始区间,这就要求随机变量![]() 和
和![]() 能够保证
能够保证![]() 能够收敛到
能够收敛到![]() 。第二种“k-近邻法”则是确定
。第二种“k-近邻法”则是确定![]() 为
为![]() 的某个函数,比如
的某个函数,比如![]() ,这样,体积就必须逐渐增长,直到能包含进
,这样,体积就必须逐渐增长,直到能包含进![]() 的
的![]() 个相邻点。这两种方法最终都能够收敛,但是却很难预测它们在有限样本情况下的效果。
个相邻点。这两种方法最终都能够收敛,但是却很难预测它们在有限样本情况下的效果。

2、Parzen窗方法
假设区域![]() 是一个以
是一个以![]() 为中心的
为中心的![]() 维的超立方体,令
维的超立方体,令![]() 表示超立方体的边长,那么体积为:
表示超立方体的边长,那么体积为:
![]()
以二维情况为例,如下图所示:

通过定义如下窗函数,表示![]() 是否落入超立方体
是否落入超立方体![]() 中:
中:

因此,超立方体中样本个数![]() 为:
为:
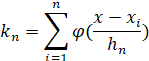
代入![]() 得:
得:

本题是三维数据,且假设窗函数为一个球形的高斯函数:
![]()
![]()
最终得到判别的核心函数,即概率密度函数为:

Notice:
① 数据使用说明:
表格中给出了3类数据,每类数据中含有10个三维数据,对于每类数据都需要将10个三维数据代入上述公式中,求出该类的概率密度函数,通过30组测试数据得出每类的概率密度函数,然后将测试数据代入到三个概率密度函数中,概率密度函数最大的那个类便是该数据所在的类。
② 窗的宽度h说明:
H越小,![]() 越小,统计结果的稳定性不够
越小,统计结果的稳定性不够
H越大,![]() 越大,统计结果的分别率太低
越大,统计结果的分别率太低
所以窗宽度的选择对于训练模型有影响,同时窗函数的选择也十分重要。
3、k-近邻估计
在Parzen窗方法中,窗函数的选择往往是个需要权衡的问题,而k-近邻算法提供了一种解决办法,是一种经典的非参数估计方法。基本思路是:已知训练数据![]() ,估计
,估计![]() ,以点
,以点![]() 为中心,不断扩大体积
为中心,不断扩大体积![]() ,直到区域内包含
,直到区域内包含![]() 个样本点为止,这些样本被称为点
个样本点为止,这些样本被称为点![]() 的
的![]() 个最近邻点。
个最近邻点。
当涉及到邻点时,我们通常选用欧几里得距离来度量。
① 一维和二维情况:求出自变量![]() 与每个训练数据的直线距离,通过能包含
与每个训练数据的直线距离,通过能包含![]() 个点的最小距离计算
个点的最小距离计算![]() ,进而得到概率密度值,画出图像。
,进而得到概率密度值,画出图像。
② 三维数据情况:规定![]() 值,找出距离测试样本点
值,找出距离测试样本点![]() 个最近的点,哪一类的点多就判定为该类。
个最近的点,哪一类的点多就判定为该类。
三、代码及运行结果
1、Parzen窗
import xlrd
import numpy as np
# 读取数据
def read_data():
x = []
data = xlrd.open_workbook("lab3_data.xlsx")
table = data.sheets()[0]
rows = table.nrows
for i in range(1, rows):
row_value = table.row_values(i)
x.append(row_value)
return x
def get_phi(x, xi, h):
x = np.mat(x)
xi = np.mat(xi)
phi = np.exp(-(x - xi) * (x - xi).T / (2 * h * h))
return phi
def get_px(x, xi, h):
phi = 0
n = len(xi)
for i in range(n):
# print("xi[i]", xi[i])
phi += get_phi(x, xi[i], h)
px = phi * 3 / (4 * np.pi * n * np.power(h, 3))
return px
def parzen(h, test, data):
px = [0, 0, 0]
print("h =", h)
for j in range(len(test)):
print("x =", test[j])
for i in range(len(px)):
xi = [x[:3] for x in filter(lambda x: x[3] == i + 1, data)]
# print("xi", xi)
# print("len xi", len(xi))
px[i] = get_px(test[j], xi, h)
print("px", i+1, "=", px[i])
if px[0] > px[1] and px[0] > px[2]:
print("belong to w1")
if px[1] > px[0] and px[1] > px[2]:
print("belong to w2")
if px[2] > px[0] and px[2] > px[1]:
print("belong to w3")
def main():
data = read_data()
# print(np.mat(data))
test = [[0.5, 1.0, 0.0], [0.31, 1.51, -0.50], [-0.3, 0.44, -0.1]]
h1 = 1
h2 = 0.1
parzen(h1, test, data)
parzen(h2, test, data)
if __name__ == '__main__':
main()
(a) h=1时,测试样本点分类结果:

(b) h=0.1时,测试样本点分类结果:
2、k-nn
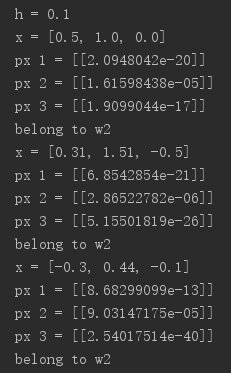
(a)一维特征,k=1,3,5时的概率密度估计结果:
import xlrd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
def read_data():
x = []
data = xlrd.open_workbook("lab3_data.xlsx")
table = data.sheets()[0]
rows = table.nrows
for i in range(1, rows):
row_value = table.row_values(i)
x.append(row_value)
return x
def get_distance(k, x, xi):
dist = []
for i in range(len(xi)):
dist.append(np.sqrt(np.sum(np.square(x - xi[i]))))
dist.sort()
return dist[k]
def k_nn(k, xi):
num = 1000
x = np.linspace(0, 3, num)
px = []
for i in range(num):
h = 2 * get_distance(k, x[i], xi)
px.append(k / (len(xi) * h))
plt.subplot(1, 5, k)
plt.plot(x, px)
plt.xlabel("x")
plt.ylabel("p(x)")
plt.title("k=" + str(k))
def main():
data = read_data()
xi = [x[0] for x in filter(lambda x: x[3] == 3, data)]
print(np.mat(xi).T)
k1 = 1
k2 = 3
k3 = 5
k_nn(k1, xi)
k_nn(k2, xi)
k_nn(k3, xi)
plt.show()
if __name__ == '__main__':
main()
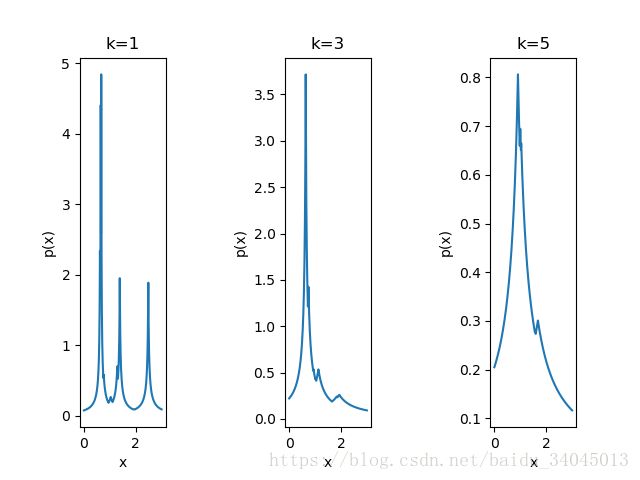
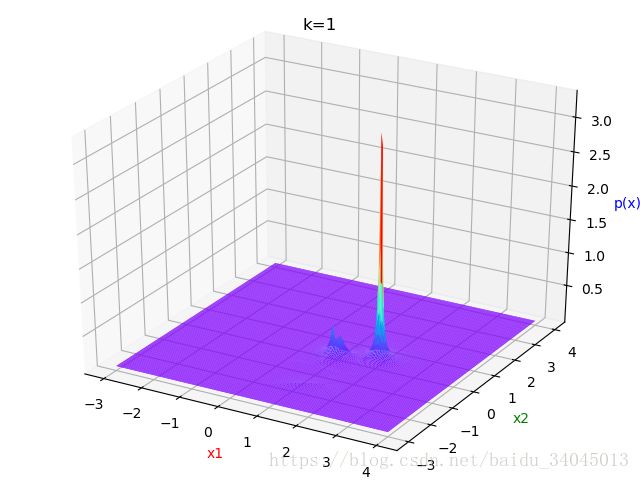
(b)二维特征,k=1,3,5时的概率密度估计结果:
import xlrd
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 读取数据
def read_data():
x = []
data = xlrd.open_workbook("lab3_data.xlsx")
table = data.sheets()[0]
rows = table.nrows
for i in range(1, rows):
row_value = table.row_values(i)
x.append(row_value)
return x
def get_distance(k, x, xi):
dist = []
for i in range(len(xi)):
dist.append(np.sqrt(np.sum(np.square(x - xi[i]))))
dist.sort()
return dist[k]
def k_nn(k, xi):
num = 100
x = y = np.linspace(-3, 4, num)
px = []
X = []
for i in range(num):
for j in range(num):
X.append([x[i], y[j]])
for i in range(num * num):
h = 2 * get_distance(k, np.mat(X)[i], xi)
px.append(k / (len(xi) * np.pi * h * h))
px2d = []
for i in range(num):
list = []
for j in range(num):
list.append(px[i*num+j])
px2d.append(list)
px2d = np.array(px2d)
x, y = np.meshgrid(x, y)
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x, y, px2d, rstride=1, cstride=1, cmap='rainbow')
ax.set_xlabel("x1", color='r')
ax.set_ylabel("x2", color='g')
ax.set_zlabel("p(x)", color='b')
plt.title("k=" + str(k))
def main():
data = read_data()
xi = [x[:2] for x in filter(lambda x: x[3] == 2, data)]
print(np.mat(xi))
k1 = 1
k2 = 3
k3 = 5
k_nn(k1, xi)
k_nn(k2, xi)
k_nn(k3, xi)
plt.show()
if __name__ == '__main__':
main()


(c)三维特征,k=5,测试点概率密度估计结果:
import xlrd
import numpy as np
# 读取数据
def read_data():
x = []
data = xlrd.open_workbook("lab3_data.xlsx")
table = data.sheets()[0]
rows = table.nrows
for i in range(1, rows):
row_value = table.row_values(i)
x.append(row_value)
return x
def get_distance(test, xi):
dist = []
for i in range(len(xi)):
dist.append(np.sqrt(np.sum(np.square(test - xi[i][:3]))))
return dist
def k_nn(k, test, data):
x = [x[:3] for x in filter(lambda x: x, data)]
dist = get_distance(np.mat(test), np.mat(x))
index = []
index = np.argsort(dist)
w = [0, 0, 0]
for i in range(k):
if data[index[i]][3] == 1:
w[0] += 1
if data[index[i]][3] == 2:
w[1] += 1
if data[index[i]][3] == 3:
w[2] += 1
if w[0] > w[1] and w[0] > w[2]:
return "w1"
if w[1] > w[0] and w[1] > w[2]:
return "w2"
if w[2] > w[0] and w[2] > w[1]:
return "w3"
def main():
data = read_data()
k = 5
test = [[-0.41, 0.82, 0.88], [0.14, 0.72, 4.1], [-0.81, 0.61, -0.38]]
for i in range(len(test)):
print(test[i])
print("belong to", k_nn(k, test[i], data))
if __name__ == '__main__':
main()

四、总结
Parzen窗和k-近邻是非参数估计的两种经典方法,由 ![]() ,n是已知的总的样本点,k和V未知。Parzen窗方法通过固定V改变k来求概率密度,而k-近邻通过固定k改变V来估计概率密度。Parzen窗需要先确定条件概率密度后才能对测试点进行分类,而k-近邻可以直接根据k个近邻中哪个类别的样本点最多就将其分为哪一类。k-近邻是典型的lazy-learning,每一个测试点都要重新计算,并且训练集需要保留。
,n是已知的总的样本点,k和V未知。Parzen窗方法通过固定V改变k来求概率密度,而k-近邻通过固定k改变V来估计概率密度。Parzen窗需要先确定条件概率密度后才能对测试点进行分类,而k-近邻可以直接根据k个近邻中哪个类别的样本点最多就将其分为哪一类。k-近邻是典型的lazy-learning,每一个测试点都要重新计算,并且训练集需要保留。
如有错误请指正