基于逻辑回归/决策树/随机森林/多层感知分类器/xgboost/朴素贝叶斯分类的资讯多分类性能对比
在上一篇(https://blog.csdn.net/baymax_007/article/details/82748544)中,利用逻辑回归实现资讯多分类。本文在之前基础上,又引入决策树、随机森林、多层感知分类器、xgboost和朴素贝叶斯分类算法,并对验证集和测试集分类正确率和耗时进行性能对比。
ml支持决策树、随机森林、梯度提升决策树(GBDT)、线性支持向量机(LSVC)、多层感知分类器(MPC,简单神经网络)和朴素贝叶斯分类,可以直接使用。需要注意,梯度提升决策树和线性支持向量机在spark mllib2.3.1版本中暂时不支持多分类,本文先不对两者作对比。xgboost4j-spark中封装支持java和scala版本的xgboost,可以直接使用。
一、环境
java 1.8.0_172+scala 2.11.8+spark 2.3.1+HanLP portable-1.6.8+xgboost-spark 0.80
org.apache.spark
spark-core_2.11
2.3.1
org.apache.spark
spark-sql_2.11
2.3.1
org.apache.spark
spark-hive_2.11
2.3.1
org.apache.spark
spark-mllib_2.11
2.3.1
com.hankcs
hanlp
portable-1.6.8
ml.dmlc
xgboost4j-spark
0.80
二、实验设计
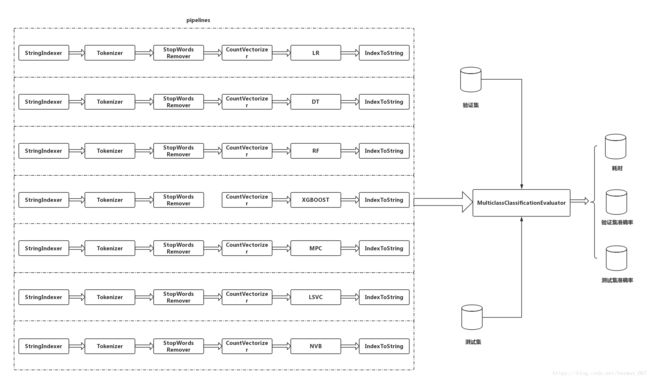
spark ml支持pipeline,可以将特征提取转换、分类模型一起组装到pipeline中,通过对pipeline的训练建模,并在统一分类评估准则下,进行算法对比,从而简化代码冗余,如下图所示。
而上一篇HanLP分词无法组装到pipeline中,因此需要自定义ml包Tokenizer继承UnaryTransformer类,并重写UnaryTransformFunc,实现基于HanLP分词、可以组装到pipeline功能。
三、代码实现
1. 自定义HanLP实现pipeline封装
ml自带Tokenizer可以封装到pipeline中,查看代码,发现其继承UnaryTransformer类,并重写UnaryTransformFunc方法,这也是分词的核心方法,outputDataType和valiadateInputType可以约束输出类型和输入类型校验。
class HanLPTokenizer(override val uid:String) extends UnaryTransformer[String, Seq[String], HanLPTokenizer] {
private var segmentType = "StandardTokenizer"
private var enableNature = false
def setSegmentType(value:String):this.type = {
this.segmentType = value
this
}
def enableNature(value:Boolean):this.type = {
this.enableNature = value
this
}
def this() = this(Identifiable.randomUID("HanLPTokenizer"))
override protected def createTransformFunc: String => Seq[String] = {
hanLP
}
private def hanLP(line:String): Seq[String] = {
var terms: Seq[Term] = Seq()
import collection.JavaConversions._
segmentType match {
case "StandardSegment" =>
terms = StandardTokenizer.segment(line)
case "NLPSegment" =>
terms = NLPTokenizer.segment(line)
case "IndexSegment" =>
terms = IndexTokenizer.segment(line)
case "SpeedSegment" =>
terms = SpeedTokenizer.segment(line)
case "NShortSegment" =>
terms = new NShortSegment().seg(line)
case "CRFlexicalAnalyzer" =>
terms = new CRFLexicalAnalyzer().seg(line)
case _ =>
println("分词类型错误!")
System.exit(1)
}
val termSeq = terms.map(term =>
if(this.enableNature) term.toString else term.word)
termSeq
}
override protected def validateInputType(inputType: DataType): Unit = {
require(inputType == DataTypes.StringType,
s"Input type must be string type but got $inputType.")
}
override protected def outputDataType: DataType = new ArrayType(StringType, true)
}2. 特征工程代码
主要包含有:标签索引转换,本文分词,去除停用词、关键词频数特征提取和预测索引标签还原。
val indexer = new StringIndexer()
.setInputCol("tab")
.setOutputCol("label")
.fit(peopleNews)
val segmenter = new HanLPTokenizer()
.setInputCol("content")
.setOutputCol("tokens")
.enableNature(false)
.setSegmentType("StandardSegment")
val stopwords = spark.read.textFile("/opt/data/stopwordsCH.txt").collect()
val remover = new StopWordsRemover()
.setStopWords(stopwords)
.setInputCol("tokens")
.setOutputCol("removed")
val vectorizer = new CountVectorizer()
.setVocabSize(1000)
.setInputCol("removed")
.setOutputCol("features")
val converts = new IndexToString()
.setInputCol("prediction")
.setOutputCol("predictionTab")
.setLabels(indexer.labels)
3.逻辑回归代码
val lr = new LogisticRegression()
.setMaxIter(40)
.setTol(1e-7)
.setLabelCol("label")
.setFeaturesCol("features")
val lrStartTime = new Date().getTime
val lrPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,lr,converts))
val Array(train,test) = peopleNews.randomSplit(Array(0.8,0.2),12L)
val lrModel = lrPipeline.fit(train)
val lrValiad = lrModel.transform(train)
val lrPredictions = lrModel.transform(test)
val evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("label")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracyLrt = evaluator.evaluate(lrValiad)
println(s"逻辑回归验证集分类准确率 = $accuracyLrt")
val accuracyLrv = evaluator.evaluate(lrPredictions)
println(s"逻辑回归测试集分类准确率 = $accuracyLrv")
val lrEndTime = new Date().getTime
val lrCostTime = lrEndTime - lrStartTime
println(s"逻辑回归分类耗时:$lrCostTime")
4.决策树代码
// 训练决策树模型
val dtStartTime = new Date().getTime
val dt = new DecisionTreeClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
.setImpurity("entropy") // 不纯度
.setMaxBins(1000) // 离散化"连续特征"的最大划分数
.setMaxDepth(10) // 树的最大深度
.setMinInfoGain(0.01) //一个节点分裂的最小信息增益,值为[0,1]
.setMinInstancesPerNode(5) //每个节点包含的最小样本数
.setSeed(123456L)
val dtPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,dt,converts))
val dtModel = dtPipeline.fit(train)
val dtValiad = dtModel.transform(train)
val dtPredictions = dtModel.transform(test)
val accuracyDtt = evaluator.evaluate(dtValiad)
println(s"决策树验证集分类准确率 = $accuracyDtt")
val accuracyDtv = evaluator.evaluate(dtPredictions)
println(s"决策树测试集分类准确率 = $accuracyDtv")
val dtEndTime = new Date().getTime
val dtCostTime = dtEndTime - dtStartTime
println(s"决策树分类耗时:$dtCostTime")
5. 随机森林代码
// 训练随机森林模型
val rfStartTime = new Date().getTime
val rf = new RandomForestClassifier()
.setLabelCol("label")
.setFeaturesCol("features")
.setImpurity("entropy") // 不纯度
.setMaxBins(1000) // 离散化"连续特征"的最大划分数
.setMaxDepth(10) // 树的最大深度
.setMinInfoGain(0.01) //一个节点分裂的最小信息增益,值为[0,1]
.setMinInstancesPerNode(5) //每个节点包含的最小样本数
.setNumTrees(100)
.setSeed(123456L)
val rfPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,rf,converts))
val rfModel = rfPipeline.fit(train)
val rfValiad = rfModel.transform(train)
val rfPredictions = rfModel.transform(test)
val accuracyRft = evaluator.evaluate(rfValiad)
println(s"随机森林验证集分类准确率为:$accuracyRft")
val accuracyRfv = evaluator.evaluate(rfPredictions)
println(s"随机森林测试集分类准确率为:$accuracyRfv")
val rfEndTime = new Date().getTime
val rfCostTime = rfEndTime - rfStartTime
println(s"随机森林分类耗时:$rfCostTime")
6. 多层感知分类器代码
多层感知分类器(简单神经网络)网络节点设置可以参考:
m:输入层节点个数,n:输出层节点个数,h1:第一层隐含层节点个数=log2(m),h2:第一层隐含层节点个数=sqrt(m+n)+a,其中a取1-10
// 多层感知分类器
val inputLayers = vectorizer.getVocabSize
val hideLayer1 = Math.round(Math.log(inputLayers)/Math.log(2)).toInt
val outputLayers = peopleNews.select("tab").distinct().count().toInt
val hideLayer2 = Math.round(Math.sqrt(inputLayers + outputLayers) + 1).toInt
val layers = Array[Int](inputLayers, hideLayer1, hideLayer2, outputLayers)
val mpcstartTime = new Date().getTime
val mpc = new MultilayerPerceptronClassifier()
.setLayers(layers)
.setBlockSize(128)
.setTol(1e-7)
.setMaxIter(100)
.setLabelCol("label")
.setFeaturesCol("features")
.setSeed(1234L)
val mpcPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,mpc,converts))
val mpcModel = mpcPipeline.fit(train)
val mpcValiad = mpcModel.transform(train)
val mpcPredictions = mpcModel.transform(test)
val accuracyMpct = evaluator.evaluate(mpcValiad)
println(s"多层感知分类器验证集分类准确率:$accuracyMpct")
val accuracyMpcv = evaluator.evaluate(mpcPredictions)
println(s"多层感知分类器测试集分类准确率:$accuracyMpcv")
val mpcEndTime = new Date().getTime
val mpcCostTime = mpcEndTime - mpcstartTime
println(s"多层感知分类器分类耗时:$mpcCostTime")
7. XGBOOST代码
// xgboost训练模型
val xgbParam = Map("eta" -> 0.1f,
"max_depth" -> 10, //数的最大深度。缺省值为6 ,取值范围为:[1,∞]
"objective" -> "multi:softprob", //定义学习任务及相应的学习目标
"num_class" -> outputLayers,
"num_round" -> 10,
"num_workers" -> 1)
val xgbStartTime = new Date().getTime
val xgb = new XGBoostClassifier(xgbParam).
setFeaturesCol("features").
setLabelCol("label")
val xgbPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,xgb,converts))
val xgbModel = xgbPipeline.fit(train)
val xgbValiad = xgbModel.transform(train)
val xgbPredictions = xgbModel.transform(test)
val accuracyXgbt = evaluator.evaluate(xgbValiad)
println(s"xgboost验证集分类准确率为:$accuracyXgbt")
val accuracyXgbv = evaluator.evaluate(xgbPredictions)
println(s"xgboost测试集分类准确率为:$accuracyXgbv")
val xgbEndTime = new Date().getTime
val xgbCostTime = xgbEndTime - xgbStartTime
println(s"xgboost分类耗时:$xgbCostTime")8. 朴素贝叶斯代码
// 朴素贝叶斯分类
val nvbStartTime = new Date().getTime
val nvb = new NaiveBayes()
val nvbPipeline = new Pipeline()
.setStages(Array(indexer,segmenter,remover,vectorizer,nvb,converts))
val nvbModel = nvbPipeline.fit(train)
val nvbValiad = nvbModel.transform(train)
val nvbPredictions = nvbModel.transform(test)
val accuracyNvbt = evaluator.evaluate(nvbValiad)
println(s"朴素贝叶斯验证集分类准确率:$accuracyNvbt")
val accuracyNvbv = evaluator.evaluate(nvbPredictions)
println(s"朴素贝叶斯测试集分类准确率:$accuracyNvbv")
val nvbEndTime = new Date().getTime
val nvbCostTime = nvbEndTime - nvbStartTime
println(s"朴素贝叶斯分类耗时:$nvbCostTime")四、性能对比
| 验证集分类准确率 | 测试集分类准确率 | 耗时(ms) | |
| 逻辑回归(LR) | 100% | 79.53% | 44697 |
| 决策树(DT) | 81.58% | 73.68% | 34597 |
| 随机森林(RF) | 94.24% | 73.68% | 56608 |
| 多层感知分类器(MPC) | 97.98% | 68.42% | 30801 |
| XGBOOST | 99.71% | 79.53% | 31947 |
| 朴素贝叶斯分类(NVB) | 83.74% | 71.34% | 11510 |
以上算法,设计参数调优会在稍后进行尝试。
参考文献
https://blog.csdn.net/baymax_007/article/details/82748544
https://blog.csdn.net/liam08/article/details/79184159
http://spark.apache.org/docs/latest/ml-classification-regression.html
https://blog.csdn.net/u013421629/article/details/78329191
https://xgboost.readthedocs.io/en/latest/jvm/