DeepStream: 新一代智能城市视频分析
在Jetson TX2上试用TensorRT
https://jkjung-avt.github.io/tensorrt-cats-dogs/
NVIDIA提供了一个名为TensorRT的高性能深度学习推理库。它可以用来加速Jetson TX2上的深度学习推理(以每秒帧数衡量),与原始caffe + cudnn相比,增加几倍。在撰写本文时,TensorRT-2.1.2可用于Jetson TX2,并随JetPack-3.1自动安装。同时,可以在以下网址找到最新版本的TensorRT文档:http://docs.nvidia.com/deeplearning/sdk/tensorrt-user-guide/index.html
当我学习在Jetson TX2上使用TensorRT时,我想确保我可以使用TensorRT来加速我之前在Jetson TX2上训练的deeplearning-cats-dogs-tutorial模型。所以我首先在Jetson TX2上下载并运行了jetson-inference代码。
2018年01月25日 21:05:20 图波列夫 阅读数:2902 标签: DeepLearningNVIDIADeepStreamGPU 更多
个人分类: GPUDeepLearningDeepStream
以下主体内容翻译自:DeepStream: Next-Generation Video Analytics for Smart Cities
试想一下每个家长最糟糕的噩梦:一个孩子在拥挤的商场里迷路。现在想象一下,建筑物内部署的摄像机网络在几分钟之内就可以找到这个孩子的位置,并实时记录、检索和分析所有的视频。这只是视频分析领域提供的许多可能性之一。

虽然传统的视频分析使用基于计算机视觉的方法,但下一代解决方案愈发依赖深度学习技术。在GPU上运行这些算法可提供前所未有的准确性、功能和速度。实现视频分析潜力的关键在于构建可以经济高效扩展的应用程序。
NVIDIA新推出的DeepStream SDK借助NVIDIA Tesla GPU的硬件特性(包括卓越的解码性能,通过降低精度进行高速推理以及低功耗),帮助开发人员快速构建高效、高性能的视频分析应用程序。本博文将提供DeepStream SDK的概述,说明如何使用它来满足性能和可伸缩性需求,并基于目标检测示例展示其易用性。
为什么使用DeepStream?
视频分析的核心是标准的计算机视觉任务,包括图像分类、目标检测、识别和跟踪。图 1 显示了上述每个任务在图像上的应用。
图 1(左)基于类别概率识别出的物体。 (中)根据边界框检测到的物体。 (右)跨帧跟踪的目标。
现在已有很多网络能够有效地处理这些任务,通常为卷积神经网络。连续的数据帧通常通过这些网络来产生感兴趣的结果。高性能的应用程序建立在流水线上,能够为神经网络提供所需分辨率和格式的视频帧,从而最大化吞吐量。可扩展性要求并行处理多个视频流以获得更高的信道密度(在给定(机架)空间中处理的视频信道数量)。使用深度学习进行视频分析的计算成本很高,而实时视频的要求更为严格,因为它通常涉及使用定制逻辑和灵活工作流程的实时分析。
DeepStream视频分析工作流程
图 2 显示了使用DeepStream的典型应用程序流水线。由SDK提供的阶段以绿色显示,并且用户实现的阶段显示为蓝色,以示区分。用户只负责将视频解析并注入流水线,提供深度学习网络,以及获取流水线产生的推理结果。
图 2 DeepStream流水线
DeepStream SDK提供包含对输入视频流解码、预处理和推理的模块,所有模块都经过精细调整,以提供最大的帧吞吐量。解码模块接受以H.264、H.265和MPEG-4等格式编码的视频,并对它们进行解码以渲染NV12颜色格式的原始帧。视频解码使用硬件加速的NVIDIA Video Codec SDK。
预处理阶段将颜色格式从NV12转换为BGR,并将帧的大小调整为神经网络所需的分辨率。色彩空间转换和缩放使用自定义CUDA内核和NVIDIA Performance Primitives(NPP)库函数的组合。
推理模块利用一个由TensorRT导入和执行的神经网络批量处理这些帧。TensorRT优化的网络具备高吞吐量和低延迟以及一流的功率效率。DeepStream目前支持基于Caffe的网络; 在不久之后会支持TensorFlow。
这些模块紧密集成在一起,以确保在正确使用数据传输和软件同步的同时获得最大的硬件并发性。
DeepStream User API
DeepStream提供了一个C++ API,其核心是三个实体:用作流水线各个构建块的module、封装整个流水线本身的 device worker以及在模块之间进行通信的 tensor。模块表示流水线中的各个阶段,可以分为预定义(解码器、预处理和推理)或添加定制逻辑的用户定义模块。
要构建流水线,可以通过调用createDeviceWorker()来创建device worker的实例:
// Create a deviceWorker on a GPU device, the user needs to set the channel number.
IDeviceWorker *pDeviceWorker = createDeviceWorker(g_nChannels, g_devID);
- 1
- 2
然后,通过定义用于解码的输入编解码器类型、预处理阶段要输出的颜色格式以及推理模型的网络细节,来启用和配置流水线的预定义阶段。
// Add decode task, the parameter is the format of codec. pDeviceWorker->addDecodeTask(cudaVideoCodec_H264);
// Add post processing task and define color format for inference
pDeviceWorker->addColorSpaceConvertorTask(BGR_PLANAR);
// Enable inference module and define model details
pDeviceWorker->addInferenceTask(preModule_infer, deployFile, modelFile, meanFile,
inputLayerName, outputLayerNames);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
该应用程序现在可以运行了。
//finally, start the pipeline!
pDeviceWorker->start();
- 1
- 2
自定义流水线
用户可以通过向流水线添加自定义的模块来扩展此模型。创建一个模块包括定义输入、执行程序和输出张量。您可以通过将输出张量连接到后续模块中的适当输入来扩展和配置流水线。张量具有形状和数据类型属性,以及值为CPU或GPU的“存储器类型”,允许与其相关的数据进行适当的处理和复制。输入张量的数据类型必须与模块预期的类型相匹配。
自定义模块通过插入手写kernel、OpenCV算法等到流水线,可以实现更复杂的多阶段分析,以补充深度神经网络。图 3 中的示例演示了将基于OpenCV的目标跟踪算法集成到DeepStream流水线中。推理模块将包含边界框的张量输出到目标跟踪模块中,然后在后续帧中跟踪检测到的对象。跟踪和边界框信息一起在屏幕显示上呈现以便可视化。

图 3 定制模块集成
专为 Tesla P4/P40 而打造
虽然DeepStream可以在任何最新的、其计算力支持对应CUDA和TensorRT版本的GPU上运行,但它的设计旨在利用基于Pascal系列的Tesla P4和P40 GPU的特殊推理和视频功能。结合高浮点吞吐量和高效率,这些GPU支持最新的(H265)编码格式,可同时解码30多个高清视频信道。这使得软件能够以这种前所未有的速率向这些GPU上执行的深度神经网络提供帧进行推理。DeepStream软件架构通过解码模块的多线程实现,以及为进入NVDECODE API的每个信道设置数据包缓存,来利用这种硬件解码功能。这造就了最大的硬件解码器(NVDEC)利用率和解码性能。
解码吞吐量的提高使得更大的推理批量成为可能,从而提高推理吞吐量。GPU支持8位整数(INT8)操作,提供了进一步提高系统吞吐量的机会。TensorRT 2.1引入了将单精度浮点(FP32)深度学习网络(CNN)转换为使用INT8精度而无需任何调整或再训练的能力。通过使用校准技术,尽管INT8的范围和精度有所降低,但在推断过程中没有明显的精度损失。DeepStream提供校准表以及在运行时启用或禁用INT8的API。这允许TensorRT在执行网络时以最佳方式在FP32和INT8精度之间进行转换。
Tesla P4是紧凑型的加速卡,最大功耗为75W,专为每台服务器有多个卡的高密度数据中心部署而设计。根据这一要求,DeepStream可以在不同的GPU上执行多条流水线,以实现更高的信道密度。您可以通过createDeviceWorker()的deviceID参数将GPU的ID传递给流水线。
IDeviceWorker *createDeviceWorker(const int nChannels, const int deviceId);
- 1
这一目的是让更高层的软件根据使用情况、利用率和服务质量等因素来创建和管理各种流水线,并在适当的GPU上调度视频流。
目标检测示例
DeepStream版本包含名为nvDecInfer_detection的目标检测示例,基于未剪枝的Resnet-18网络。该示例展示了DeepStream使用的各个方面,包括流水线创建和配置,H264流解析和注入,自定义模块的添加以及推理结果的使用。这些代码大部分是可重用的,可以很容易地应用到用户项目。
示例流水线
图 4 显示了目标检测样本的端到端流水线。
图 4 目标检测示例流水线
像之前一样,SDK提供的模块是绿色的,用户提供的逻辑是蓝色的。作为DeepStream中解码模块的多线程实现的补充,示例中的用户逻辑使用单独的线程将数据包注入到流水线中相应的信道输入中,如以下代码所示:
//per thread injection of packets into pipeline
pDeviceWorker->pushPacket(pBuf, nBuf, laneID);
- 1
- 2
虽然该示例使用基于文件的视频输入,但是对于其他情况(例如相机馈入或网络流式传输),该概念可以类似地进行扩展。推理模块使用的Resnet-18网络输出两个张量,包含每帧中检测到的各类对象的边界框和覆盖信息。这些结果由parser模块聚合,该模块通过基于覆盖阈值的过滤以及剩余边界框聚合来输出整理过的边界框信息。presenter模块将边界框渲染到原始帧并显示在显示器上。
Profiling
DeepStream提供分析器来帮助您测量通过解码和推理模块的帧吞吐量。每个信道报告解码吞吐量,而推理吞吐量提供了总吞吐量,因为所有信道都合并到一个共享缓冲区中,以进行分析。下面的清单显示了解码分析的结果:
[DEBUG][11:51:33] Video [0]: Decode Performance: 718.89 frames/second || Decoded Frames: 500
[DEBUG][11:51:33] Video [1]: Decode Performance: 711.68 frames/second || Decoded Frames: 500
[DEBUG][11:51:33] Video [0]: Decode Performance: 762.77 frames/second || Decoded Frames: 1000
[DEBUG][11:51:33] Video [1]: Decode Performance: 748.20 frames/second || Decoded Frames: 1000
- 1
- 2
- 3
- 4
您可以通过累加每个信道吞吐量来确定总解码吞吐量。
分析器报告结果的速率可根据DecodeProfiler类中的定义进行配置,DecodeProfiler类实现了处理分析结果的逻辑。
在屏幕上显示
有了视频分析,通常需要查看覆盖在视频上的分析结果。目标检测示例以一个自定义模块演示了这个功能的实现,它接受两个输入张量——由预处理模块提供的解码帧输出和从推理模块中检测出的边界框的坐标。该示例使用OpenGL glut library来渲染边界框,这需要基础的窗口系统和显示。由于Tesla GPU不能直接驱动显示器,因此该示例可以使用单独的图形卡(例如GeForce或Quadro GPU卡)进行显示。因而,该示例演示了如何将DeepStream视频流水线扩展到第二个GPU。图 5 显示了示例带边框的目标检测结果。
图 5 多信道目标检测可视化
性能
与大多数基于GPU的工作负载一样,视频分析应用程序的性能受可用内存大小和带宽(设备内存带宽以及主机到设备内存传输接口带宽 PCI-E)、GPU核心数量、GPU时钟频率的影响。这些因素决定了视频流水线中每个阶段的块级吞吐量。基于DeepStream的应用程序通常是解码限制或推理(计算)限制,取决于所使用的深度学习网络的复杂性。使用nvidia-smi等工具来确定哪个硬件解码器(NVDEC)或GPU内核接近100%利用率(如果有)可以获得哪个阶段是瓶颈的快速提示。
目标检测示例在基于P4的系统上执行时受到推理的限制,在处理30 fps高清视频时,如果信道数达到16时出现GPU的满使用率,如下面的nvidia-smi输出所示。信道数量的进一步增加会导致吞吐量下降到视频帧速率以下,从而使实时处理不可行。
$ nvidia-smi -i 0 -q -d UTILIZATION
GPU 0000:05:00.0
Utilization
Gpu : 96 %
Memory : 41 %
Encoder : 0 %
Decoder : 56 %
- 1
- 2
- 3
- 4
- 5
- 6
- 7
改为等效(但较小)的Resnet-10网络可以以30 fps处理多达30个信道。以下nvidia-smi输出显示解码器利用率达到100%,表明应用程序是解码限制的。
$ nvidia-smi -i 0 -q -d UTILIZATION
GPU 0000:05:00.0
Utilization
Gpu : 76 %
Memory : 56 %
Encoder : 0 %
Decoder : 100 %
- 1
- 2
- 3
- 4
- 5
- 6
- 7
由于较高的计算成本,使用较大网络的应用程序在相对较低的信道数下受到推断限制。最佳做法是在网络功能和性能方面进行最佳折衷,充分修剪网络,并使用INT8推断实现最大信道数,并榨取GPU中所有可用性能。
通过实现这一平衡,我们能够以前所未有的规模和能力支持激动人心的新用例。 图 6 显示了基于Resnet-10的检测应用程序的解码分析器输出,该应用程序列出了匹配30 fps输入帧速率的所有30个通道的吞吐量。图 6 还显示了nvidia-smi输出,证明Tesla P4 GPU在执行工作负载时仅消耗47 W,仅为1.56 W/信道。这为部署在服务器场内的机器提供了在可接受的功率预算范围内实现卓越的信道密度的机会。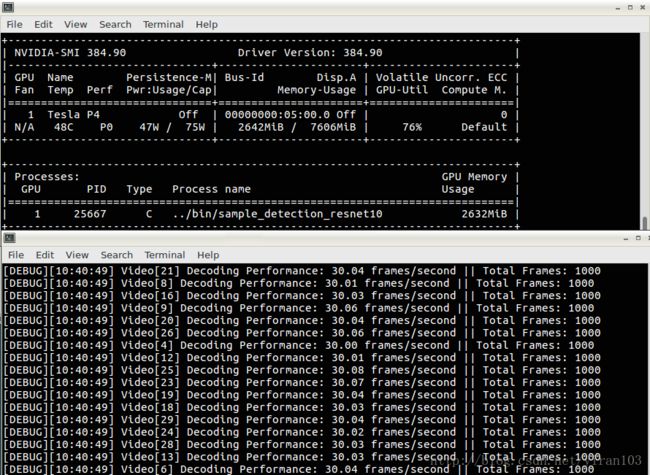
图 6 目标检测的执行度量:(顶部)nvidia-smi显示的GPU功耗。 (底部)每信道帧吞吐量。
立即尝试DeepStream!
Tesla GPU为深度学习驱动的视频分析应用带来了全新的机遇,而NVIDIA DeepStream SDK使其更易于构建。DeepStream使您能够利用深度学习中的前沿概念。您可以依照此博客中描述的想法来实现级联网络和实时目标跟踪器等功能。DeepStream团队很高兴看到使用SDK实现的创新。立即下载DeepStream SDK。
我们欢迎您在DeepStream开发者论坛上提出您的问题和意见。我们的目标是根据您的反馈继续扩展和发展DeepStream,所以请让我们了解您的想法。发掘你的视频告诉你的一切从未如此简单!
#补充内容:
许可证
DeepStream SDK仅支持datacenter GPU。
“The following files are for use with datacenter GPUs such as Tesla P4 and P40.”
网页连接的 NVIDIA DeepStream SDK 1.5 Software License Agreement为deepstream-sdk-eula-pdf,但是在网站上打不开。
NVIDIA DeepStream SDK 1.5
目前DeepStream SDK 1.5已经发布,其特性为:
- 所有新的功能借助于NVIDIA CUDA 9.0,NVIDIA TensorRT 3.0和cuDNN 7
- 支持可变的批量大小,以最大限度地提高所有用例的吞吐量
- 通过TensorRT 3.0支持TensorFlow模型
- 智能解码仅解码用于分析的帧,以显着提高通过GPU的信道密度
快速启动指南
网站给出的指南内容如下:
- 验证您的系统上是否安装了以下软件
1. Ubuntu 16.04 LTS(带GCC 5.4)
2. NVIDIA显示驱动程序版本384
3. NVIDIA VideoSDK 8.0
4. cuDNN 7和TensorRT 3.0
5. NVIDIA CUDA 9.0 - 下载DeepStream 1.5 tar文件
- 在您选择的位置提取软件包
- 按照下载包中的Deepstream_User_guide.pdf的使用说明进行操作。
上述系统要求与Deepstream_User_guide.pdf并不一致,软件包自带文档中为:
- Ubuntu 16.04 LTS(带GCC 5.4)
- NVIDIA显示驱动程序版本375
- NVIDIA VideoSDK 7.14
- cuDNN 6 & TensorRT 2.1
- NVIDIA CUDA 8.0
似乎文档未及更新。