Python3网络爬虫(十二):初识Scrapy之再续火影情缘
转载请注明作者和出处: http://blog.csdn.net/c406495762
运行平台: Windows
Python版本: Python3.x
IDE: Sublime text3
- 前言
- Scrapy框架之初窥门径
- 1 Scrapy简介
- 2 Scrapy安装
- 3 Scrapy基础
- 31 创建项目
- 32 Shell分析
- 4 Scrapy程序编写
- 41 Spiders程序测试
- 42 Items编写
- 43 Settings编写
- 44 Comic_spider编写
- 45 Pipelines编写
- 运行结果
- 总结
1 前言
如果有人问我,你最喜欢的动漫是什么?我会毫不犹豫地告诉他:《火影忍者》。因为,这是唯一的一部贯穿我小学、初中、高中、大学、研究生生活的动漫。小学五年级的时候,家里的电视安装了机顶盒,那时候的动漫频道还不是清一色的《天线宝宝》、《熊出没》这样的国产动漫。大部分都是日本动漫,《火影忍者》、《海贼王》、《浪客剑心》这样的热血动漫充斥着整个动漫频道。就从那时开始,我走上了追《火影忍者》的道路。虽然,这是一个暴露年龄的事情,可是我还是想说,我也算是一个资深的火影迷了。鸣人的火之意志、鸣人和佐助的羁绊的故事,看得我热血沸腾。初中的时候,我还曾傻傻地学习忍术的结印手势,以为只要学会了结印手势就能放出忍术,现在想想,真的是无忧无虑的童年啊!可能,有朋友会问,《火影忍者》不是已经完结了吗?《火影忍者》是完结了,但是鸣人儿子的故事才刚刚开始,《博人传之火影忍者新时代》正在热播中。因此,我又开始追动漫了,虽然现在不会像儿时那样激动到上蹿下跳,但是我依然喜欢看,现在感觉,继续看火影,更多的是一种情怀吧!
今天的闲话有点多,就此打住,回归正题。为了了解动漫的进展,看相应的漫画是个不错的选择。而KuKu动漫又是免费的试看平台,满足我的需求。奉上URL:http://comic.kukudm.com/
可以看到,这个网站的第一个推荐动漫就是《火影忍者》。这个网站不提供下载功能,但是又很想收藏怎么办?那就用分布式爬虫Scrapy搞下来吧!当然,在此之前,不得不说的一句话就是:请勿将程序用于任何商业用途,仅供交流学习。尊重著作权,请购买正版漫画。
2 Scrapy框架之初窥门径
2.1 Scrapy简介
Scrapy Engine(Scrapy核心) 负责数据流在各个组件之间的流。Spiders(爬虫)发出Requests请求,经由Scrapy Engine(Scrapy核心) 交给Scheduler(调度器),Downloader(下载器)Scheduler(调度器) 获得Requests请求,然后根据Requests请求,从网络下载数据。Downloader(下载器)的Responses响应再传递给Spiders进行分析。根据需求提取出Items,交给Item Pipeline进行下载。Spiders和Item Pipeline是需要用户根据响应的需求进行编写的。除此之外,还有两个中间件,Downloaders Mddlewares和Spider Middlewares,这两个中间件为用户提供方面,通过插入自定义代码扩展Scrapy的功能,例如去重等。因为中间件属于高级应用,本次教程不涉及,因此不做过多讲解。

2.2 Scrapy安装
关于Scrapy的安装,可以查看我之前的笔记:http://blog.csdn.net/c406495762/article/details/60156205
2.3 Scrapy基础
安装好Scrapy之后,我们就可以开启我们的Scrapy之旅了。官方的详细中文教程,请参见:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html 。我这里只讲本次实战用到的知识。
简单流程如下:
- 创建一个Scrapy项目;
- 定义提取的Item;
- 编写爬取网站的 spider 并提取 Item;
- 编写 Item Pipeline 来存储提取到的Item(即数据)。
2.3.1 创建项目
在开始爬取之前,我们必须创建一个新的Scrapy项目。 进入打算存储代码的目录中,运行下列命令:
scrapy startproject cartoonscrapy startproject是固定命令,后面的cartoon是自己想起的工程名字。这里,我起名为cartoon(漫画)。
该命令将会创建包含下列内容的cartoon目录:
cartoon/
scrapy.cfg
cartoon/
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
spiders/
__init__.py
...这些文件分别是:
- scrapy.cfg: 项目的配置文件;
- cartoon/: 该项目的python模块。之后将在此加入Spider代码;
- cartoon/items.py: 项目中的item文件;
- cartoon/middlewares .py:项目中的中间件;
- cartoon/pipelines.py: 项目中的pipelines文件;
- cartoon/settings.py: 项目的设置文件;
- cartoon/spiders/: 放置spider代码的目录。
2.3.2 Shell分析
在编写程序之前,我们可以使用Scrapy内置的Scrapy shell,分析下目标网页,为后编写梳理思路。先分析下《火影忍者》主界面:
scrapy shell "http://comic.kukudm.com/comiclist/3/"
在Scrapy shell中,我们可以通过如下指令打印网页的body信息:
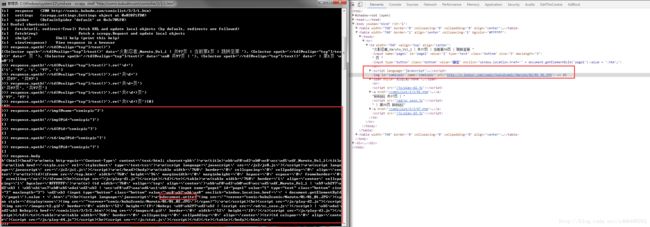
response.body通过返回的内容,我们可以寻找自己想要的链接,但是这种方法,显然有些麻烦,因为内容太多,不好找。这里,我们还是使用审查元素的方式进行分析:

可以看到,每个章节的链接和名字都存放在了dd标签下的a标签中。在shell中输入如下指令提取链接:
response.xpath('//dd/a[1]')xpath之前讲过了,如果忘记了,可翻阅我之前整理的笔记。从输出结果可以看到,每个链接都已经提取出来了,但是没有显示a标签里面的内容。

想要显示全,就需要extract()方法,转换成字符串输出,指令如下:
response.xpath('//dd/a[1]').extract()从运行结果可以看出,这样就显示完全了。现在开始思考一个问题,如果我想保存每个章节的图片,需要哪些东西?链接必不可少,当然还有每个章节的名字,我们要以文件夹的形式存储每个章节,文件夹的命名就是章节的名字,这样更规整。

我们使用text()获取每个章节的名字,指令如下:
response.xpath('//dd/a[1]/text()').extract()瞧,每个章节的名字被我们轻松的提取出来了,记住这个指令,在编写程序的时候,需要用到。

获取完章节名字,接下来就是获取链接了,使用指令如下:
response.xpath('//dd/a[1]/@href').extract()Scrapy还是蛮好用的嘛~省去了使用Beautifulsoup这些工具的使用。当然,它的强大不仅仅于此,让我们慢慢道来。

《火影忍者》首页分析完了。接下来,我们分析每个章节里的内容,看看如何获取每个图片的链接。还是使用审查元素的方式,我们可以看到,这个网页提供的信息如下。再思考一个问题,从这个网页我们要获取哪些信息?第一个当然还是图片的链接,第二个呢?将一个章节里的每个图片保存下来,我们如何命名图片?用默认名字下载下来的图片,顺序也就乱了。仔细一点的话,不难发现,第一页的链接为:http://comic.kukudm.com/comiclist/3/3/1.htm,第二页的链接为:http://comic.kukudm.com/comiclist/3/3/2.htm,第三页的链接为:http://comic.kukudm.com/comiclist/3/3/3.htm 依此类推,所以我们可以根据这个规律进行翻页,而为了翻页,首先需要获取的就是每个章节的图片数,也就是页数,随后,我们根据每页的地址就可以为每个图片命名:第1页、第2页、第3页…,这样命名就可以了。不会出现乱序,并且很工整,方便我们阅读。由于有的章节图片的链接不是规律的,所以只能先获取页面地址,再获取图片地址,这样递进爬取。
使用ctrl+c退出之前的shell,分析章节页面,以第一章为例,使用指令如下:
scrapy shell "http://comic.kukudm.com/comiclist/3/1.htm"套路已经想好,那就开始测试吧。通过审查元素可以知道,页数存放在valign属性i为top的td标签中。获取的内容由于有好多信息,我们再使用re()方法,通过正则表达式获取页数。获取页数代码如下:
response.xpath('//td[@valign="top"]/text()').re('共(\d+)页')[0]可以看到,通过几次测试就把页数提取出来了。最终的这个指令页要记住,编写程序需要用到。

图片页获取完了,下面该获取图片的链接了,通过审查元素我们会发现,图片链接保存再img标签下的src属性中,理想状态,使用如下指令就可以获取图片链接:
response.xpath('//img[@id="comipic"]/@src').extract()但是你会发现,返回为空。这是为什么?通过response.body打印信息不难发现,这个链接是使用JS动态加载进去的。直接获取是不行的,网页分为静态页面和动态页面,对于静态页面好说,对于动态页面就复杂一些了。可以使用PhantomJS、发送JS请求、使用Selenium、运行JS脚本等方式获取动态加载的内容。(该网站动态加载方式简单,不涉及这些,后续教程会讲解其他动态加载方法)
该网站是使用如下指令加载图片的:
document.write("<img src='"+server+"comic/kuku2comic/Naruto/01/01_01.JPG'><span style='display:none'><img src='"+server+"comic/kuku2comic/Naruto/01/01_02.JPG'>span>");JS脚本放在网页里,没有使用外部JS脚本,这就更好办了,直接获取脚本信息,不就能获取图片链接了?使用指令如下:
response.xpath('//script/text()').extract()通过运行结果可以看出,我们已经获取到了图片链接,server的值是通过运行JS外部脚本获得的,但是这里,我们仔细观察server的值为http://n.1whour.com/,其他页面也是一样,因此也就简化了流程。同样,记住这个指令,编写程序的时候会用到。

就这样这个思路已经梳理清楚,需要的内容有章节链接、章节名、图片链接、每张页数。shell分析完毕,接下来开始编写程序。
2.4 Scrapy程序编写
2.4.1 Spiders程序测试
在cortoon/spiders目录下创建文件comic_spider.py,编写内容如下:
# -*- coding:UTF-8 -*-
import scrapy
class ComicSpider(scrapy.Spider):
name = "comic"
allowed_domains = ['comic.kukudm.com']
start_urls = ['http://comic.kukudm.com/comiclist/3/']
def parse(self, response):
link_urls = response.xpath('//dd/a[1]/@href').extract()
for each_link in link_urls:
print('http://comic.kukudm.com' + each_link)- name:自己定义的内容,在运行工程的时候需要用到的标识;
- allowed_domains:允许爬虫访问的域名,防止爬虫跑飞。让爬虫只在指定域名下进行爬取,值得注意的一点是,这个域名需要放到列表里;
- start_urls:开始爬取的url,同样这个url链接也需要放在列表里;
- def parse(self, response) :请求分析的回调函数,如果不定义start_requests(self),获得的请求直接从这个函数分析;
parse函数中的内容,就是之前我们获取链接的解析内容,在cmd中使用如下指令运行工程:
scrapy crawl comic打印输出了这个章节的链接:

再打印章节名字看看,代码如下:
# -*- coding:UTF-8 -*-
import scrapy
class ComicSpider(scrapy.Spider):
name = "comic"
allowed_domains = ['comic.kukudm.com']
start_urls = ['http://comic.kukudm.com/comiclist/3/']
def parse(self, response):
# link_urls = response.xpath('//dd/a[1]/@href').extract()
dir_names = response.xpath('//dd/a[1]/text()').extract()
for each_name in dir_names:
print(each_name)章节名字打印成功!

2.4.2 Items编写
刚刚进行了简单的测试,了解下Spiders的编写。现在开始进入正题,按步骤编写爬虫。第一步,填写items.py,内容如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class ComicItem(scrapy.Item):
dir_name = scrapy.Field()
link_url = scrapy.Field()
img_url = scrapy.Field()
image_paths = scrapy.Field()- dir_name:文件名,也就是章节名;
- link_url:每个章节的每一页的链接,根据这个链接保存图片名;
- img_url:图片链接;
- image_paths:图片保存路径。
2.4.3 Settings编写
填写settings.py,内容如下:
BOT_NAME = 'cartoon'
SPIDER_MODULES = ['cartoon.spiders']
NEWSPIDER_MODULE = 'cartoon.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'cartoon (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'cartoon.pipelines.ComicImgDownloadPipeline': 1,
}
IMAGES_STORE = 'J:/火影忍者'
COOKIES_ENABLED = False
DOWNLOAD_DELAY = 0.25 # 250 ms of delay- BOT_NAME:自动生成的内容,根名字;
- SPIDER_MODULES:自动生成的内容;
- NEWSPIDER_MODULE:自动生成的内容;
- ROBOTSTXT_OBEY:自动生成的内容,是否遵守robots.txt规则,这里选择不遵守;
- ITEM_PIPELINES:定义item的pipeline;
- IMAGES_STORE:图片存储的根路径;
- COOKIES_ENABLED:Cookie使能,这里禁止Cookie;
- DOWNLOAD_DELAY:下载延时,这里使用250ms延时。
2.4.4 Comic_spider编写
在comic_spider.py文件中,编写代码如下,代码进行了详细的注释:
# -*- coding: utf-8 -*-
import re
import scrapy
from scrapy import Selector
from cartoon.items import ComicItem
class ComicSpider(scrapy.Spider):
name = 'comic'
def __init__(self):
#图片链接server域名
self.server_img = 'http://n.1whour.com/'
#章节链接server域名
self.server_link = 'http://comic.kukudm.com'
self.allowed_domains = ['comic.kukudm.com']
self.start_urls = ['http://comic.kukudm.com/comiclist/3/']
#匹配图片地址的正则表达式
self.pattern_img = re.compile(r'\+"(.+)\'>)
#从start_requests发送请求
def start_requests(self):
yield scrapy.Request(url = self.start_urls[0], callback = self.parse1)
#解析response,获得章节图片链接地址
def parse1(self, response):
hxs = Selector(response)
items = []
#章节链接地址
urls = hxs.xpath('//dd/a[1]/@href').extract()
#章节名
dir_names = hxs.xpath('//dd/a[1]/text()').extract()
#保存章节链接和章节名
for index in range(len(urls)):
item = ComicItem()
item['link_url'] = self.server_link + urls[index]
item['dir_name'] = dir_names[index]
items.append(item)
#根据每个章节的链接,发送Request请求,并传递item参数
for item in items[-13:-1]:
yield scrapy.Request(url = item['link_url'], meta = {'item':item}, callback = self.parse2)
#解析获得章节第一页的页码数和图片链接
def parse2(self, response):
#接收传递的item
item = response.meta['item']
#获取章节的第一页的链接
item['link_url'] = response.url
hxs = Selector(response)
#获取章节的第一页的图片链接
pre_img_url = hxs.xpath('//script/text()').extract()
#注意这里返回的图片地址,应该为列表,否则会报错
img_url = [self.server_img + re.findall(self.pattern_img, pre_img_url[0])[0]]
#将获取的章节的第一页的图片链接保存到img_url中
item['img_url'] = img_url
#返回item,交给item pipeline下载图片
yield item
#获取章节的页数
page_num = hxs.xpath('//td[@valign="top"]/text()').re(u'共(\d+)页')[0]
#根据页数,整理出本章节其他页码的链接
pre_link = item['link_url'][:-5]
for each_link in range(2, int(page_num) + 1):
new_link = pre_link + str(each_link) + '.htm'
#根据本章节其他页码的链接发送Request请求,用于解析其他页码的图片链接,并传递item
yield scrapy.Request(url = new_link, meta = {'item':item}, callback = self.parse3)
#解析获得本章节其他页面的图片链接
def parse3(self, response):
#接收传递的item
item = response.meta['item']
#获取该页面的链接
item['link_url'] = response.url
hxs = Selector(response)
pre_img_url = hxs.xpath('//script/text()').extract()
#注意这里返回的图片地址,应该为列表,否则会报错
img_url = [self.server_img + re.findall(self.pattern_img, pre_img_url[0])[0]]
#将获取的图片链接保存到img_url中
item['img_url'] = img_url
#返回item,交给item pipeline下载图片
yield item 代码看上去可能不好理解,自己动手尝试一下,一步一步来,最终你就会找到答案的。这部分代码不能一步一步讲解,思路已经讲完,其他的就靠自己尝试与体悟了。关于python的yield,简单地讲,yield 的作用就是把一个函数变成一个 generator,带有 yield 的函数不再是一个普通函数,Python 解释器会将其视为一个 generator。想要保持代码的整洁,又要想获得 iterable 的效果,就可以使用yield了,这部分内容,可以查看廖雪峰老师的教程。
2.4.5 Pipelines编写
pipelines.py主要负责图片的下载,我们根据item保存的信息,进行图片的分类保存,代码如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from cartoon import settings
from scrapy import Request
import requests
import os
class ComicImgDownloadPipeline(object):
def process_item(self, item, spider):
#如果获取了图片链接,进行如下操作
if 'img_url' in item:
images = []
#文件夹名字
dir_path = '%s/%s' % (settings.IMAGES_STORE, item['dir_name'])
#文件夹不存在则创建文件夹
if not os.path.exists(dir_path):
os.makedirs(dir_path)
#获取每一个图片链接
for image_url in item['img_url']:
#解析链接,根据链接为图片命名
houzhui = image_url.split('/')[-1].split('.')[-1]
qianzhui = item['link_url'].split('/')[-1].split('.')[0]
#图片名
image_file_name = '第' + qianzhui + '页.' + houzhui
#图片保存路径
file_path = '%s/%s' % (dir_path, image_file_name)
images.append(file_path)
if os.path.exists(file_path):
continue
#保存图片
with open(file_path, 'wb') as handle:
response = requests.get(url = image_url)
for block in response.iter_content(1024):
if not block:
break
handle.write(block)
#返回图片保存路径
item['image_paths'] = images
return item代码依旧进行了注释,自己动手尝试吧!
3 运行结果
由于工程文件较多,我将我的整体代码上传到了我的Github,欢迎Follow、Star。URL:https://github.com/Jack-Cherish/python-spider/tree/master/cartoon
我下载了后面火影忍者博人传的内容,可以使用代码,直接爬取漫画所有章节,效果如下所示:
短短了两分钟,这些图片就都保存好了,是不是体会到了分布式Scrapy爬虫的强大了?

4 总结
- 自己测试的时候,记住加个time.sleep(1)延时,否则说不定哪里爬快了,服务器就会锁IP了;
- Scrapy的分布式爬取真的很强大,认真学习一下还是有必要的;
- 不要一味想着爬快点、爬快点、爬快点,为服务器考虑下;
- 程序请勿用于任何商业用途,仅供交流学习;
- 如有问题,请留言。如有错误,还望指正,谢谢!
最后感谢看我博客的朋友们,长久以来的支持~后续,爬虫教程可能就出的慢一些了,但是也会更新。过段时间,重点将会放在机器学习和深度学习方面,如有兴趣,欢迎届时前来捧场!
PS: 如果觉得本篇本章对您有所帮助,欢迎关注、评论、顶!