在python编辑器中输入中文注释的问题
问题描述:
这次新学了python中有特色的文档注释功能,用一对三引号括起多行注释,如
def make_great(magicians):
'''add the great '''
for i in range(0,len(magicians)):
magicians[i] = 'the Great '+ magicians[i]
这个操作在Geany编辑器中,注释为英文时是没有问题的,但是当注释是中文时就会报错:
包括#中文注释也不行
# 8-5
# 测试中文注释
def describe_city(city,nation='China'):
'''表示国家和城市'''
print(city.title() + ' is in ' + nation.title())
describe_city('shandong')
describe_city('paris','france')
describe_city('beijing')
原因:Geany 保存代码时默认的编码格式是GBK(不支持中文注释),而UTF-8才支持中文注释的识别。
尝试:在Geany的编码设置中将默认编码设置成utf-8,发现并没有什么用,看来是保存时候的编码问题,而Geany在保存时没有修改编码格式的选项
法一:
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。
当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python //为了告诉Linux系统,这个是python可执行程序
# _*_ coding:utf-8 _*_ //为了告诉python解释器,按照utf-8编码读取源代码,否则,你在源代码中写的中文输出可能会由乱码
#coding=utf-8 //上一行代码也可以写成这种形式
通过这个方法,用#加中文的单行注释已经不报错了,但多行注释仍报错。
法二:用notepad++转换编码格式
即将文件用notepad++打开,在编码选项中转为UTF编码格式,再用Geany打开
此时两种中文注释都可以正常输入,程序正常运行(不需添加任何其他代码)
但我觉得这种方法太过麻烦,想要直接在Geany上就可以转为UTF格式
法三:最简便的方法就是,在Geany打开python文件时,设置打开的编码格式如图
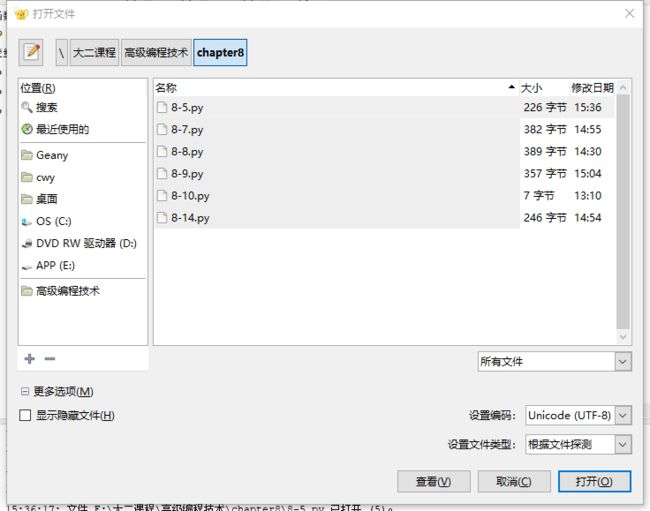
这样就可以顺利添加中文注释了。(不需添加代码)
法四:换成pycharm(默认编码格式为utf)编辑器
另外注意,sublime,vim编辑器的默认编码格式是ANS,也需要转换。