机器学习(五)--- FTRL一路走来,从LR -> SGD -> TG -> FOBOS -> RDA -> FTRL
本文会尝试总结FTRL的发展由来,总结从LR -> SGD -> TG -> FOBOS -> RDA -> FTRL 的发展历程。本文的主要目录如下:
一、 反思魏则西事件。
二、 LR模型
三、 SGD算法
四、 TG算法
五、 FOBOS算法
六、 RDA算法
七、 FTRL算法
注:本文中间大部分引用了@fengyoung的博文。为了加深自己的理解,也把知识稍微整理了一下。
一、 反思魏则西事件
在文章刚开始,先谈到最近很火热的魏则西事件。魏则西是我的校友,我也比他大不了几岁,他因为患滑膜肉瘤在百度上搜索广告误导,在武警二院接受了未经验证允许临床使用的生物医疗疗法耗费了几乎所有的家产和延误了最佳治疗时机,最终去世人财两空。首先滑膜肉瘤目前医疗条件几乎是绝症,魏则西也已经是病程四期,而对待绝症时国内很多医生或者医院都会有两种选择: 1. 守着职业道德,直接说明结果建议不要继续尝试,以免人财两空; 2. 昧着良心,推荐很多赚钱的药物和治疗方案,挣大量的黑心钱。患者因为求生的意志和家人的爱,会抓住一点点的希望并且放大,而且会因为病程的发展留下的治疗急迫性,判断力会下降很多很多的。这件事情是很残酷的,医生挣了黑心钱,广告主挣了钱,患者却没有得到最佳的治疗方案。但其实仔细分析,整件事情的责任方医院和国家监管机构应该承担主要责任,违规临床使用生物疗法的公司也应当承担主要责任,然后百度也应当承担次要责任。魏则西和家人面对一点点的希望也选择搏一把,虽然失败了,但是很悲壮和值得尊敬。面对社会和现实,人总是那么渺小。也许我将来有一天也会得病,也许也是绝症,也许这对我和我家人很残酷,虽然很难但我希望我是理性的,可以默念生亦何欢,死亦何苦。但就现在来说,我希望我要珍惜生活、珍惜生命、珍惜身边的人。我也希望我要多多锻炼身体,保持健康的作息,多多开心珍惜每一天,多多爱我爱的人和爱我的人。
在广告这个问题上,其实广告的目的是连接广告主和消费者,最大化广告服务商的利润的时最大化广告主的投资会报比。其实这就有一个隐藏的问题,广告服务商其实并未太多考虑消费者的利益和广告后面服务和商品的满意度,所以很多做广告的就会调侃,希望有一天在马路上,大家知道他是做广告的不会扔鸡蛋和鞋子。也许以后广告会有了更多的准入限制和广告后服务效果的追踪后,会好点。。。
二、 逻辑回归
言归正传,因为广告大部分是按照CPC计费的,而我们手里的流量是固定的,因此对每条广告请求我们就需要保证这条广告的展示收益更大。而广告收益是可以根据点击率、广告计费价格、广告质量度均衡决定的,所以我们就需要评估广告的质量度和点击率,本文就主要研究广告点击率预估中广泛使用的逻辑回归模型。在实际广告点击率预估的应用中,样本数目和特征(逻辑回归粗暴离散化后)的数目均可以达到上亿纬度,而LR因为其简单和易并行,并且基于复杂的特征工程后也能得到非常好的效果,所以在工业界获得了广泛的应用。
逻辑回归,相对于线性回归是用来处理目标函数是离散数值的情况。它的映射函数和损失函数分别为:
 (1)
(1) ![]() (2)
(2)
使用梯度下降法进行求解,得到迭代公式:

1. 逻辑回归的优缺点:
优点:
a. 简单
b. 易于并行、速度快
缺点:
a. 需要复杂的特征工程
注意事项:
a. 输入特征需要离散化。
三、 SGD算法
对于如上LR的迭代公式来说,我们可以得到GD(Gradient Descent)的求解算法。(W为求解的参数,l(w, z)为损失函数)。

可是如果我们对参数做一轮迭代求解,都需要遍历所有的样本,这在实际应用中未免迭代速度太慢,模型更新速度也太慢。而且做机器学习的时候往往更多的数据意味着更好的效果,我们能把线上实时的数据和样本标注也利用进来么?答案是 Yes。仔细研究参数的迭代我们可以发现,都是给定一个初始的参数W,通过迭代逐步求解出当前W下降的方向并更新W直到损失函数稳定在最小点。那么我们是不是可以取部分训练集作为原训练集的子集,使用这些子集做迭代,并逐步求解W的下降方向,逐步对W进行更新(理论证明未知)。特别的,如果我们每次取原训练样本的一个训练样本,对W的值逐步进行更新,那么我们就得到了SGD算法。

与SGD比较,GD需要每次扫描所有的样本以计算一个全局梯度,SGD则每次只针对一个观测到的样本进行更新。通常情况下SGD可以更快的逼近最优值,而且SGD每次更新只需要一个样本,使得它很适合进行增量或者在线计算(也就是所谓的Online learning)。
特别的,迭代和选取模型的时候我们经常希望得到更加稀疏的模型,这不仅仅起到了特征选择的作用,也降低了预测计算的复杂度。在实际使用LR的时候我们会使用L1或者L2正则,避免模型过拟合和增加模型的鲁棒性。在GD算法下,L1正则化通常能得到更加稀疏的解;可是在SGD算法下模型迭代并不是沿着全局梯度下降,而是沿着某个样本的梯度进行下降,这样即使是L1正则也不一定能得到稀疏解。在后面的优化算法中,稀疏性是一个主要追求的目标。
四、 TG算法
1. L1 正则化法
由于L1正则项在0处不可导,往往会造成平滑的凸优化问题变成非平滑的凸优化问题,因此可以采用次梯度(Subgradient)来计算L1正则项的梯度。权重更新方式为:
![]()
其中![]() 是一个标量,为L1正则化的参数;v是一个向量,sgn(v)为符号函数;
是一个标量,为L1正则化的参数;v是一个向量,sgn(v)为符号函数;![]() 称为学习率,通常将其设置为
称为学习率,通常将其设置为![]() 的函数;
的函数;![]() 代表第t次迭代中损失函数的梯度。
代表第t次迭代中损失函数的梯度。
2. 简单截断法
既然L1正则化在Online模式下也不能产生更好的稀疏性,而稀疏性对于高维特征向量以及大数据集又特别的重要,我们应该如何处理的呢?
简单粗暴的方法是设置一个阀值,当W的某纬度的系数小于这个阀值的时候,将其直接设置为0。这样我们就得到了简单截断法。简单截断法以k为窗口,当t/k不为整数时采用标准的SGD进行迭代,当t/k为整数时,权重更新方式如下:
![]()
![]()
这里![]() 是一个正数;V是一个向量。
是一个正数;V是一个向量。
3. 梯度截断法
简单截断法法简单且易于理解,但是在实际训练过程中的某一步,W的某个特征系数可能因为该特征训练不足引起的,简单的截断过于简单粗暴(too aggresive),会造成该特征的缺失。那么我们有没有其他的方法,使得权重的归零和截断处理稍微温柔一些呢?对,这就是梯度截断法,简单截断法和梯度截断法对特征权重的处理映射图对比如下:
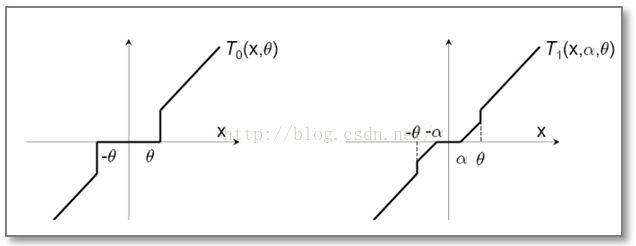
梯度截断法的迭代公式如下:
![]()
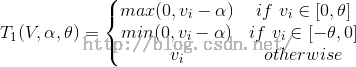 (3)
(3)
同样的梯度截断法也是以k为窗口,每k步进行一次截断。当t/k不为整数时![]() ,当t/k为整数时
,当t/k为整数时![]() 。从公式(3)可以看出
。从公式(3)可以看出![]() 和
和![]() 决定了截断的区域,也决定了W的稀疏程度。这两个数值越大,截断区域越大,稀疏性也越强。尤其这两个值相等的时候,只需要调节一个参数就能控制稀疏性。根据公式(3),得到TG的算法逻辑如下:
决定了截断的区域,也决定了W的稀疏程度。这两个数值越大,截断区域越大,稀疏性也越强。尤其这两个值相等的时候,只需要调节一个参数就能控制稀疏性。根据公式(3),得到TG的算法逻辑如下:

特别的对(3)进行改写,得到描述特征权重的更新方式为:


如果令![]()
,截断公式变成:
![]()
此时TG退化成简单截断法。同样如果令![]() ,我们就可以得到L1正则化方法。
,我们就可以得到L1正则化方法。
四、 FOBOS算法
FOBOS(Forward-Backward Splitting)是由John Duchi和Yoram Singer提出的。FOBOS算法把正则化的梯度下降问题分成一个经验损失梯度下降迭代和一个最优化问题。其中第二个最优化问题有两项:第一项2范数那项表示不能离loss损失迭代结果太远,第二项是正则化项,用来限定模型复杂度、抑制过拟合和做稀疏化等。

由于求和公式中的每一项都是大于等于0的,所以公式(2)可以拆解成对特征权重每一纬度单独求解:
![]() (2)
(2)
首先假设w是(2)的最优解,则有![]() 。反正时代入,可以得到w=0是(2)的最优解。。。
。反正时代入,可以得到w=0是(2)的最优解。。。
对v和w的取值分别进行求解可以得到:
![]()
![]()
其中g_i^(t)为梯度G^(t)在纬度i上的取值。然后我们可以得到L1-FOBOS的算法逻辑:

1. L1-FOBOS与TG的关系
从公式3)可以看出,L1-FOBOS 在每次更新W的时,对W的每个纬度都会加以判定,当满足 时对该纬度的特征进行截断,这个判定的含义是当一条样本的梯度不足以令对应纬度上的权重值发生足够大的变化时,认为在本次更新中该纬度不够重要,应当令其权重为0。
时对该纬度的特征进行截断,这个判定的含义是当一条样本的梯度不足以令对应纬度上的权重值发生足够大的变化时,认为在本次更新中该纬度不够重要,应当令其权重为0。
对于L1-FOBOS特征权重的各个纬度更新公式(3),也可以写为如下形式:

如果令![]() ,L1-FOBOS与TG完全一致,L1-FOBOS是TG在特定条件下的特殊形式。
,L1-FOBOS与TG完全一致,L1-FOBOS是TG在特定条件下的特殊形式。
五、 RDA算法
之前的算法都是在SGD的基础上,属于梯度下降类型的方法,这类型的方法的优点是精度比较高,并且TG、FOBOS也能在稀疏性上得到提升。但是RDA却从另一个方面进行在线求解,并且有效提升了特征权重的稀疏性。RDA是Simple Dual Averaging Scheme的一个扩展,由Lin Xiao发表与2010年。
在RDA中,特征权重的更新策略包含一个梯度对W的积分平均值,正则项和一个辅助的严格凸函数。具体为:
 。其中
。其中![]() 为正则化项,
为正则化项,![]() 表示一个非负且非自减序列,
表示一个非负且非自减序列,![]() 是一个严格的凸函数。
是一个严格的凸函数。
1. 算法原理
之前的算法都是在SGD的基础上,属于梯度下降类型的方法,这类型的方法的优点是精度比较高,并且TG、FOBOS也能在稀疏性上得到提升。但是RDA却从另一个方面进行在线求解,并且有效提升了特征权重的稀疏性。RDA是Simple Dual Averaging Scheme的一个扩展,由Lin Xiao发表于2010年。
L1-RDA特征权重各个纬度更新方式为:

这里当某个纬度上累积梯度平均值小于阀值的时候,该纬度权重将被设置为0,特征稀疏性由此产生。
对比L1-FOBOS我们可以发现,L1-FOBOS是TG的一种特殊形式,在L1-FOBOS中,进行截断的判定条件是
![]() ,通常会定义为正相关函数
,通常会定义为正相关函数![]() 。因此L1-FOBOS的截断阀值为
。因此L1-FOBOS的截断阀值为![]() ,随着t增加,这个阀值会逐渐降低。而相比较而言L1-RDA的截断阀值为,是一个固定的常数,因此可以认定L1-RDA比L1-FOBOS更加aggressive。此外L1-FOBOS判定是针对单次梯度计算进行判定,避免由于训练不足导致的截断问题。并且通过调节一个参数,很容易在精度和稀疏性上进行权衡。
,随着t增加,这个阀值会逐渐降低。而相比较而言L1-RDA的截断阀值为,是一个固定的常数,因此可以认定L1-RDA比L1-FOBOS更加aggressive。此外L1-FOBOS判定是针对单次梯度计算进行判定,避免由于训练不足导致的截断问题。并且通过调节一个参数,很容易在精度和稀疏性上进行权衡。
六、FTRL算法
有实验证明,L1-FOBOS这一类基于梯度下降的方法有较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。如何能把这两者的优点同时体现出来的呢?这就是
1. L1-FOBOS与L1-RDA在形式上的统一:
L1-FOBOS在形式上,每次迭代都可以表示为(这里我们令)
FTRL综合考虑了FOBOS和RDA对于正则项和W的限制,其特征权重为:

注意,公式(3)中出现了L2正则项![]() ,而论文[2]的公式中并没有这一项,但是在2013年发表的FTRL工程化实现的论文中却使用了L2正则化项。事实上该项的引入并不影响FTRL的稀疏性,仅仅相当于对最优化过程多了一个约束,使得结果求解更加平滑。
,而论文[2]的公式中并没有这一项,但是在2013年发表的FTRL工程化实现的论文中却使用了L2正则化项。事实上该项的引入并不影响FTRL的稀疏性,仅仅相当于对最优化过程多了一个约束,使得结果求解更加平滑。
公司(3)看上去很复杂,更新特征权重貌似非常困难。不妨将其改写。将其最后一项展开等价于求解下面的这样一个最优化问题:
,于是针对特征权重的各个纬度将其拆解成N个独立的标量最小化问题。上式最后一项相对于W说是一个常数项,并且令 ,上式等价于:
,上式等价于:
到这里,我们遇到了与RDA求解类似的最优化问题。用相同的分析方法可以得到:

上式可以看出,引入L2正则化对于FTRL结果的稀疏性产生任何影响。
在一个标准OGD中使用的是一个全局学习策略,这个策略保证了学习率是一个正的非增长序列,对于每个特征的纬度都是一样的。
考虑特征纬度的变化率:如果特征1比特征2的变化更快,那么纬度1上学习率应该下降的比较快。我们就很容易可以用某个纬度上梯度分量来反映这种变化率。在FTRL中纬度i上的学习率是这样计算的:
。由于,所以公式(4)中有,这里的伪码采用的事L1和L2混合正则,即实际的迭代是如下形式:

总结:
从类型上来看,简单截断法、TG、FOBOS属于同一类,都是梯度下降类的算法,并且TG在特定条件可以转换成简单截断法和FOBOS;RDA属于简单对偶平均的扩展应用;FTRL可以视作RDA和FOBOS的结合,同时具备二者的优点。目前来看,RDA和FTRL是最好的稀疏模型Online Training的算法。FTRL并行化处理,一方面可以参考ParallelSGD,另一方面可以使用高维向量点乘,及梯度分量并行计算的思路。
参考文献:
1. http://www.wbrecom.com/?p=342 本文显然大量参考了该文章。 作者写的确实好,我再写一遍以便加深自己的理解。