神经网络③——sklearn参数介绍及应用
一、MLPClassifier&MLPRegressor参数和方法
MLPClassifier(solver=’sgd’, activation=’relu’,alpha=1e-4,hidden_layer_sizes=(50,50), random_state=1,max_iter=10,learning_rate_init=.1)
参数说明(分类和回归参数一致):
- hidden_layer_sizes :例如hidden_layer_sizes=(50, 50),表示有两层隐藏层,第一层隐藏层有50个神经元,第二层也有50个神经元。
- activation :激活函数,{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认relu
- identity:f(x) = x
- logistic:其实就是sigmod,f(x) = 1 / (1 + exp(-x)).
- tanh:f(x) = tanh(x).
- relu:f(x) = max(0, x)
- solver: 权重优化器,{‘lbfgs’, ‘sgd’, ‘adam’}, 默认adam
- lbfgs:quasi-Newton方法的优化器
- sgd:随机梯度下降
- adam: Kingma, Diederik, and Jimmy Ba提出的机遇随机梯度的优化器
注意:默认solver ‘adam’在相对较大的数据集上效果比较好(几千个样本或者更多),对小数据集来说,lbfgs收敛更快效果也更好。
- alpha :float,可选的,默认0.0001,正则化项参数
- batch_size : int , 可选的,默认’auto’,随机优化的minibatches的大小batch_size=min(200,n_samples),如果solver是’lbfgs’,分类器将不使用minibatch
- learning_rate :学习率,用于权重更新,只有当solver为’sgd’时使用,{‘constant’,’invscaling’, ‘adaptive’},默认constant
- ‘constant’: 有’learning_rate_init’给定的恒定学习率
- ‘incscaling’:随着时间t使用’power_t’的逆标度指数不断降低学习率learning_rate_ ,effective_learning_rate = learning_rate_init / pow(t, power_t)
- ‘adaptive’:只要训练损耗在下降,就保持学习率为’learning_rate_init’不变,当连续两次不能降低训练损耗或验证分数停止升高至少tol时,将当前学习率除以5.
- power_t: double, 可选, default 0.5,只有solver=’sgd’时使用,是逆扩展学习率的指数.当learning_rate=’invscaling’,用来更新有效学习率。
- max_iter: int,可选,默认200,最大迭代次数。
- random_state:int 或RandomState,可选,默认None,随机数生成器的状态或种子。
- shuffle: bool,可选,默认True,只有当solver=’sgd’或者‘adam’时使用,判断是否在每次迭代时对样本进行清洗。
- tol:float, 可选,默认1e-4,优化的容忍度
- learning_rate_int:double,可选,默认0.001,初始学习率,控制更新权重的补偿,只有当solver=’sgd’ 或’adam’时使用。
属性说明:
- coefs_包含w的矩阵,可以通过迭代获得每一层神经网络的权重矩阵
- classes_:每个输出的类标签
- loss_:损失函数计算出来的当前损失值
- coefs_:列表中的第i个元素表示i层的权重矩阵
- intercepts_:列表中第i个元素代表i+1层的偏差向量
- n_iter_ :迭代次数
- n_layers_:层数
- n_outputs_:输出的个数
- out_activation_:输出激活函数的名称
二、使用MLPClassifier进行分类
import numpy as np
import matplotlib.pyplot as plt
from sklearn.neural_network import MLPRegressor,MLPClassifier
from sklearn.preprocessing import StandardScaler
data1 = np.array(data)
X = data1[:, 0:2]
Y = data1[:, 2]
scaler = StandardScaler() # 标准化转换
scaler.fit(X) # 训练标准化对象
X = scaler.transform(X) # 转换数据集
clf_class= MLPClassifier(solver='lbfgs', alpha=1e-5,hidden_layer_sizes=(5,2), random_state=1)
clf_class.fit(X,Y)
y_pred = clf_class.predict([[9.317029, 14.739025]])
print('分类预测结果:', y_pred)
y_pred_pro = clf_class.predict_proba([[9.317029, 14.739025]])
print('分类预测概率:', y_pred_pro)
![]()
index=0
for w in clf_class.coefs_:
index += 1
print('第{}层网络层:'.format(index))
print('仅重矩阵:', w.shape)
print('系数矩阵:', w)
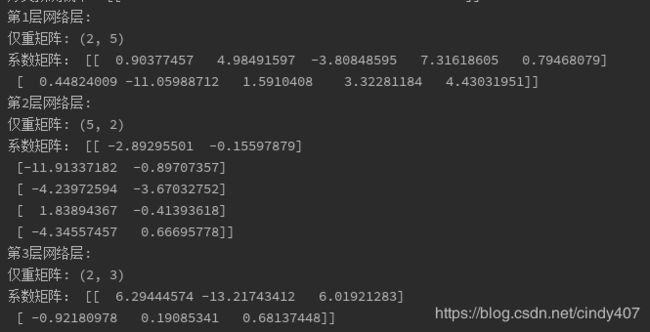
print(clf_class.classes_)
print(clf_class.loss_)
print(clf_class.activation)
print(clf_class.intercepts_)
print(clf_class.n_iter_)

三、使用MLPRegressor进行回归
data_ = [
[ -0.017612,14.053064,14.035452],[ -1.395634, 4.662541, 3.266907],[ -0.752157, 6.53862,5.786463],[ -1.322371, 7.152853, 5.830482],
[0.423363,11.054677,11.47804 ],[0.406704, 7.067335, 7.474039],[0.667394,12.741452,13.408846],[ -2.46015,6.866805, 4.406655],
[0.569411, 9.548755,10.118166],[ -0.026632,10.427743,10.401111],[0.850433, 6.920334, 7.770767],[1.347183,13.1755,14.522683],
[1.176813, 3.16702,4.343833],[ -1.781871, 9.097953, 7.316082],[ -0.566606, 5.749003, 5.182397],[0.931635, 1.589505, 2.52114 ],
[ -0.024205, 6.151823, 6.127618],[ -0.036453, 2.690988, 2.654535],[ -0.196949, 0.444165, 0.247216],[1.014459, 5.754399, 6.768858],
[1.985298, 3.230619, 5.215917],[ -1.693453,-0.55754, -2.250993],[ -0.576525,11.778922,11.202397],[ -0.346811,-1.67873, -2.025541],
[ -2.124484, 2.672471, 0.547987],[1.217916, 9.597015,10.814931],[ -0.733928, 9.098687, 8.364759],[1.416614, 9.619232,11.035846],
[1.38861,9.341997,10.730607],[0.317029,14.739025,15.056054]
]
data1 = np.array(data_)
print(data1)
X = data1[:, 0:2]
Y = data1[:, 2]
scaler = StandardScaler() # 标准化转换
scaler.fit(X) # 训练标准化对象
X = scaler.transform(X) # 转换数据集
clf = MLPRegressor(solver='lbfgs',alpha=1e-5, hidden_layer_sizes=(5,2), random_state=1)
clf.fit(X,Y)
pred = clf.predict([[0.317029, 14.739025]])
print('回归预测结果:', pred)
![]()
index=0
for w in clf.coefs_:
index += 1
print('第{}层网络层:'.format(index))
print('仅重矩阵:', w.shape)
print('系数矩阵:', w)

四、使用手写数据集进行分类训练
from sklearn.datasets import load_digits
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
data = load_digits()
x = data.data
y = data.target
print(x.shape,y.shape)
stander = MinMaxScaler()
x = stander.fit_transform(x)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3)
clf = MLPClassifier(hidden_layer_sizes=(100,100))
clf.fit(x_train,y_train)
y_pred = clf.predict((x_test))
print("训练集评分:", clf.score(x_train,y_train))
print("测试集评分:", clf.score(x_test,y_test))
print("混淆矩阵:")
print(metrics.confusion_matrix(y_test,y_pred))
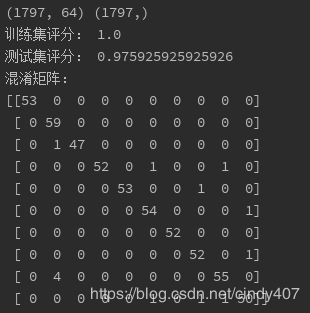
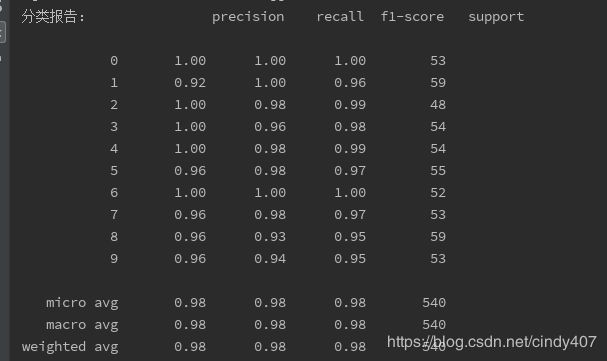
print("分类报告:", metrics.classification_report(y_test,y_pred))
print("W权重:",clf.coefs_[:1])
print("损失值:",clf.loss_)
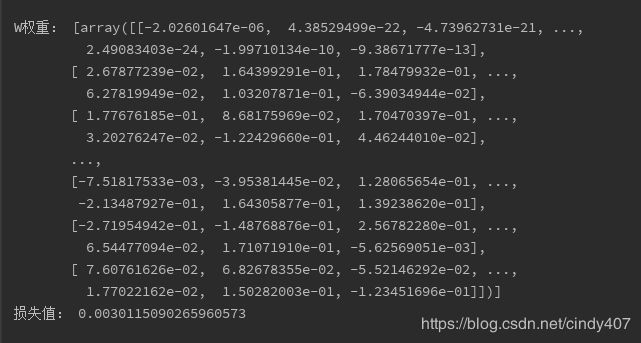
不得不说,神经网络的分类精确度真的是非常高,比其它分类器要优秀得多。