1. PageRank的由来和发展历史
0x1:源自搜索引擎的需求
Google早已成为全球最成功的互联网搜索引擎,在Google出现之前,曾出现过许多通用或专业领域搜索引擎。Google最终能击败所有竞争对手,很大程度上是因为它解决了困扰前辈们的最大难题:对搜索结果按重要性排序。而解决这个问题的算法就是PageRank。毫不夸张的说,是PageRank算法成就了Google今天的地位。
1. 搜索引擎的核心框架
从本质上说,搜索引擎是一个资料检索系统,搜索引擎拥有一个资料库(具体到这里就是互联网页面),用户提交一个检索条件(例如关键词),搜索引擎返回符合查询条件的资料列表。
理论上检索条件可以非常复杂,为了简单起见,我们不妨设检索条件是一至多个以空格分隔的词,而其表达的语义是同时含有这些词的资料(等价于布尔代数的逻辑与)。例如,提交“littlehann 博客”,意思就是“给我既含有‘littlehann’又含有‘博客’词语的页面”,以下是Google对这条关键词的搜索结果:
当然,实际上现在的搜索引擎都是有分词机制的,例如如果以“littlehann的博客”为关键词,搜索引擎会自动将其分解为“littlehann 的 博客”三个词,而“的”作为停止词(Stop Word)会被过滤掉。
建立一个搜索引擎的核心问题就是以下几个:
1. 建立资料库; 2. 建立一种数据结构,根据关键词找到含有这个词的页面; 3. 将结果按照重要程度排序后呈现给用户;
1)建立资料库
这个问题一般是通过一种叫爬虫(Spider)的特殊程序实现的(专业领域搜索引擎例如某个学术会议的论文检索系统可能直接从数据库建立资料库)。
简单来说,爬虫就是从一个页面出发(例如新浪首页),通过HTTP协议通信获取这个页面的所有内容,把这个页面url和内容记录下来(记录到资料库),然后分析页面中的链接,再去分别获取这些链接链向页面的内容,记录到资料库后再分析这个页面的链接。
上述过程不断重复,就可以将整个互联网的页面全部获取下来(当然这是理想情况,要求整个Web是一个强连通(Strongly Connected),并且所有页面的robots协议允许爬虫抓取页面,为了简单,我们仍然假设Web是一个强连通图,且不考虑robots协议)。
抽象来看,可以将资料库看做一个巨大的key-value结构,key是页面url,value是页面内容。
2)建立一种数据结构,根据关键词找到含有这个词的页面
这个问题是通过一种叫倒排索引(inverted index)的数据结构实现的。
抽象来说倒排索引也是一组key-value结构,key是关键词,value是一个页面编号集合(假设资料库中每个页面有唯一编号),表示这些页面含有这个关键词。
搜索引擎获取“littlehann 博客”查询条件,将其分为“littlehann”和“博客”两个词。
然后分别从倒排索引中找到“littlehann”所对应的集合,假设是{1, 3, 6, 8, 11, 15};
“博客”对应的集合是{1, 6, 10, 11, 12, 17, 20, 22},
将两个集合做交运算(intersection),结果是{1, 6, 11}。即寻找同时出现了这2个词的页面。
最后,从资料库中找出1、6、11对应的页面返回给用户就可以了。
3)将结果按照重要程度排序后呈现给用户
上面两个问题解决后,我们很自然会想到,Web页面数量非常巨大,所以一个检索的结果条目数量也非常多,例如上面“littlehann 博客”的检索返回了上万条条结果。用户不可能从如此众多的结果中一一查找对自己有用的信息。
所以,一个好的搜索引擎必须想办法将“质量”较高的页面排在前面。
其实直观上也可以感觉出,在使用搜索引擎时,我们并不太关心页面是否够全(上百万的结果,全不全有什么区别?而且实际上搜索引擎都是取top,并不会真的返回全部结果。),而很关心前一两页是否都是质量较高的页面,是否能满足我们的实际需求。
因此,对搜索结果按重要性合理的排序就成为搜索引擎的最大核心问题。
3.1)早期搜索引擎的做法
1. 不评价 早期的搜索引擎直接按照某自然顺序(例如时间顺序或编号顺序)返回结果。这在结果集比较少的情况下还说得过去,但是一旦结果集变大,用户叫苦不迭,试想让你从几万条质量参差不齐的页面中寻找需要的内容,简直就是一场灾难,这也注定这种方法不可能用于现代的通用搜索引擎。 2. 基于检索词的评价 后来,一些搜索引擎引入了基于检索关键词去评价搜索结构重要性的方法,实际上,这类方法如TF-IDF算法在现代搜索引擎中仍在使用。
3.2)早期搜索引擎遇到的问题 - Term Spam
早期一些搜索引擎基于类似的算法评价网页重要性的。这种评价算法看似依据充分、实现直观简单,但却非常容易受到一种叫“Term Spam”的攻击。
其实从搜索引擎出现的那天起,spammer和搜索引擎反作弊的斗法就没有停止过。Spammer是这样一群人——试图通过搜索引擎算法的漏洞来提高目标页面(通常是一些广告页面、博彩或垃圾页面)的重要性,使目标页面在搜索结果中排名靠前。
现在假设Google单纯使用关键词占比评价页面重要性,而我想让我的博客在搜索结果中排名更靠前(最好排第一)。
那么我可以这么做:在页面中加入一个隐藏的html元素(例如一个div),然后其内容是“littlehann”重复一万次。这样,搜索引擎在计算“littlehann 博客”的搜索结果时,我的博客关键词占比就会非常大(TF-IDF的公式决定了),从而做到排名靠前的效果。
更进一步,我甚至可以干扰别的关键词搜索结果,例如我知道现在欧洲杯很火热,我就在我博客的隐藏div里加一万个“欧洲杯”,当有用户搜索欧洲杯时,我的博客就能出现在搜索结果较靠前的位置。这种行为就叫做“Term Spam”。
早期搜索引擎深受这种作弊方法的困扰,加之基于关键词的评价算法本身也不甚合理,因此经常是搜出一堆质量低下的结果,用户体验大大打了折扣。而Google正是在这种背景下,提出了PageRank算法,并申请了专利保护。此举充分保护了当时相对弱小Google,也使得Google一举成为全球首屈一指的搜索引擎。
Relevant Link:
http://blog.codinglabs.org/articles/intro-to-pagerank.html
2. PageRank算法描述
0x1:PageRank的思想
1. 每一个一个网页本身具有一定的重要性,它的重要性是通过其他网络的链接到该网页来评价的。其他网页链接到该网页可以形象地理解为给这个网页投票。 2. 一个网页的链接会把该网页的重要性传递到链接的网页中,而一个网页的重要性又必须通过链接它的网页来确定。这是一个互相依赖的递归过程。 3. 公平起见,一个网页X若链接了m个网页,那么这m个网页的每个网页接收到的来自网页X的重要性是PR(X)/m。
PageRank算法的目标就是计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。
它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank就是估计这个悠闲的上网者分布在各个网页上的概率。
0x2:从感性层面认识一个简单pagerank模型
在这个小节我们以一个悠闲上网者的视角来讨论PageRank的算法过程,以便建立起一个感性的概念性认识,方便我们记忆和拦截核心概念。
互联网中的WWW网页可以看出是一个有向图,其中网页是结点。如果网页A有链接到网页B,则存在一条有向边A->B。下面是一个简单的示例:
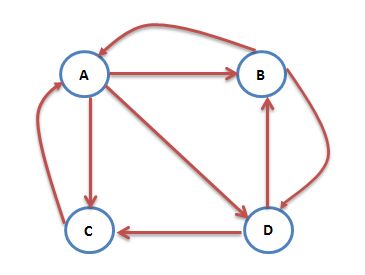
这个例子中只有四个网页。分别是A、B、C、D。这4个网页分别拥有各自不同的“跳转选择选项”,悠闲上网者在每个网页中,可以往哪一个网页去进行下一跳,是由这个选项规定的。
如果当前在A网页,那么悠闲的上网者将会各以1/3的概率跳转到B、C、D,这里的3表示A有3条出链。如果一个网页有k条出链,那么跳转任意一个出链上的概率是1/k;
同理D到B、C的概率各为1/2;
而B到C的概率为0。
一般用转移矩阵表示上网者的跳转概率(注意,这个跳转概率是在建立网络图的时候就确定好的,后面不会再改变)。
如果用n表示网页的数目,则转移矩阵M是一个n*n的方阵(每一个网页都可能转移到任意的网页,包括它自己)。
如果网页j 有 k 个出链,那么对每一个出链指向的网页i,有M[i][j]=1/k(权重是等分的),而其他网页的M[i][j]=0(没有出链就意味着不给那个网页投票);
上面示例图对应的转移矩阵的转置如下(注意,下面的矩阵是列向量的形式):

好了,现在我们已经得到了所有网页的转移矩阵,也即确定了所有网页各自的“跳转选择选项”。接下来要让我们的悠闲上网者开始在网页上不断游走,希望这个上网者通过不断地游走,给出一个最终的评估,对A、B、C、D这4个网页的重要性权重给出一个数值结果。
根据最大熵原则,悠闲上网者对这4个网页的权重没有任何先验知识,所以假设每一个网页的概率都是相等的,即1/n。
于是初试的概率分布就是一个所有值都为1/n的n维列向量V0,用V0去右乘转移矩阵M,就得到了第一步之后上网者的概率分布向量MV0。n x n)* (n x 1)依然得到一个n x 1的矩阵。

M的第一行乘以 V0,表示累加所有网页到网页A的概率即得到9/24;
M的第二行乘以 V0,表示累加所有网页到网页B的概率即得到9/24;
M的第三行乘以 V0,表示累加所有网页到网页C的概率即得到9/24;
M的第四行乘以 V0,表示累加所有网页到网页D的概率即得到9/24;
这一轮结束后,上网者对各个网页的权重值得到了一次调整,从思想上很类似EM优化过程。
可以把矩阵M和向量r相乘当做M的列以向量r为权重进行线性组合,矩阵M同一列的不同行代表该节点向其他节点的分发连接。
得到了V1后,再用V1去右乘M得到V2,一直下去,最终V会收敛,
即Vn=M * V(n-1)。

不断的迭代,最终V = [3/9,2/9,2/9,2/9]'
这个[3/9,2/9,2/9,2/9]'就代表了上网者对这4个网页权重的最终评价。显然,这个权重评价是根据 M矩阵 的拟合而来的。
直观上可以这么理解:这个悠闲上网者看到转移矩阵M,他在想,这个M矩阵就代表了当前整个网络的拓朴结构,那么这个拓朴结构背后一定隐含了某种规律,这个规律就是每个网页的权重。这个规则“支撑”着网络成为今天我看到的样本。那我要努力去游走,让我的评价无限接近网络背后的真实规律。恩,加油,我一定行的!
笔者思考:这种渐进收敛的思路,本质上体现了极大似然估计的思想,即从结果反推最有可能产生这个结果的模型参数。笔者建议读者朋友翻出极大似然估计的书籍参照着学习,笔者也有一篇blog讨论了极大似然估计的话题。
0x3:从马尔科夫过程的视角看PageRank
现在我们从马尔科夫过程的角度来看PageRank的训练和收敛过程。关于markvo的讨论,可以参阅另一篇blog。
1. 马尔科夫假设
假设我们在上网的时候浏览页面并选择下一个页面,这个过程与过去浏览过哪些页面无关,而仅依赖于当前所在的页面。这个假设前提符合马尔科夫的有限状态依赖假设。
我们可以把PageRank的这一选择过程可以认为是一个有限状态、离散时间的随机过程,其状态转移规律可用Markov链描述。
2. 概率转移矩阵
在PageRank算法中,网页拓朴间互相链接的邻接矩阵,就对应了概率转移矩阵。
- 互联网是一个有向图
- 每一个网页是图的一个顶点
- 网页间的每一个超链接是图的一个有向边
- 用邻接矩阵G来表示有向图, 即,若网页j 到网页i 有超链接, 则gij=1, 否则为gij=0
可以想象,在一个庞大的网络中,邻接矩阵是一个十分庞大有相当稀疏的方阵(用黑色代表1, 用白色代表0)。例如下图:
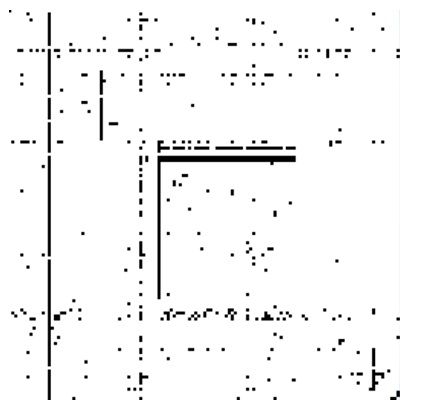
矩阵中的的空行代表了没有被其他网页链接过,可能代表是新网页(例如新的新闻html页面),或者是异常的恶意url。
定义矩阵G的“列和”与“行和”,在PageRank场景下,概率转移矩阵的“行和”和“列和”是有明确含义的。
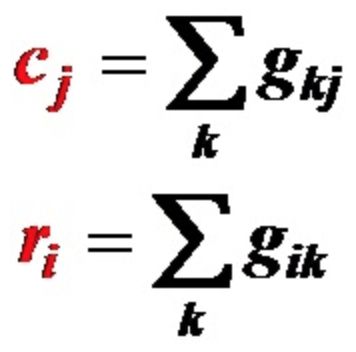
1. cj(列和) 是页面j 的导出链接数目。也就是该页面给其他页面的“投票”。当然,在PageRank中,列和是有明确约束的,即一个页面能给其他页面投票的总权重和是1,不能超过1。 2. ri(行和) 是页面 i 的导入链接数目。也就是该页面收到的权重投票。
3. 权重向量计算过程 - 隐状态序列(网页权重向量)收敛过程
在讨论马尔科夫收敛问题前,我们要对PageRank的迭代公式进行一个明确定义。但是,在讨论PageRank公式之前还要先讨论两个在实际中会遇到的问题:
1)Spider Traps问题
,即Spider Traps问题(自循环节点),因为这个问题的存在,导致PageRank的迭代公式需要作出一些变形。
可以预见,如果把真实的Web组织成转移矩阵,那么这将是一个极为稀疏的矩阵。
从矩阵论知识可以推断,极度稀疏的转移矩阵迭代相乘可能会使得向量v变得非常不平滑,即一些节点拥有很大的rank,而大多数节点rank值接近0。
而一种叫做Spider Traps节点的存在加剧了这种不平滑。例如下图:
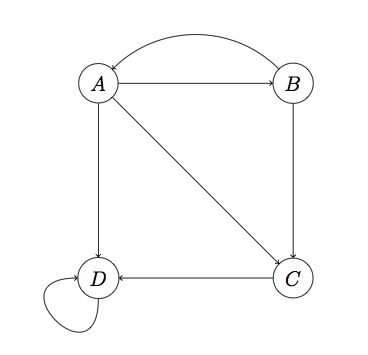
D有外链所以不是Dead Ends,但是它只链向自己(注意链向自己也算外链,当然同时也是个内链)。这种节点叫做Spider Trap。
如果对这个图进行计算,会发现D的rank越来越大趋近于1(因为每轮迭代它都只给自己投票),而其它节点rank值几乎归零。
2)Dead Ends问题
所谓Dead Ends,就是这样一类节点:它们不存在外链。看下面的图:
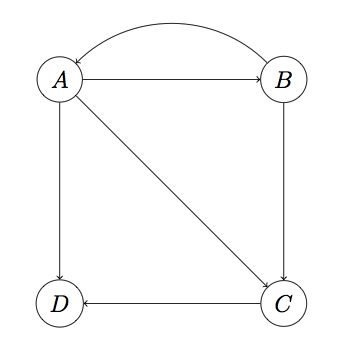
注意这里D页面不存在外链,是一个Dead End。
在这个图中,M第四列(D对应的那列)将全为0。在没有Dead Ends的情况下,每次迭代后向量v各项的和始终保持为1,而有了Dead Ends,迭代结果将最终归零。
3)随机转移概率(心灵转移)
为了克服这种由于矩阵稀疏性、Spider Traps、以及Dead Ends带来的问题,需要对PageRank计算方法进行一个平滑处理,具体做法是加入“随机转移概率”。
所谓随机转移,就是我们认为在任何一个页面浏览的用户都有可能以一个极小的概率瞬间转移到另外一个随机页面。
当然,这两个页面可能不存在超链接,随机转移只是为了算法需要而强加的一种纯数学意义的概率数字。
笔者思考:大家仔细体会这种做法的思想,它本质上就是一个结构化风险最小化思想。和在机器学习算法中加入正则项、惩罚项、剪枝;在深度学习中 Dropout 的核心思想都是一致的。我们可以这么来理解,加入了随机转移概率后,每个节点向其他节点转移的概率是不是更加倾向于“均等化”了,这就等于削弱了原本的网络结构的先验特性。
4)PageRank序列迭代公式
加入随机概率转移后,向量迭代公式变为:
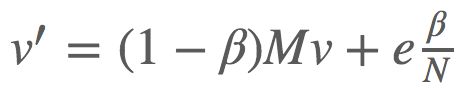
其中 β 往往被设置为一个比较小的参数(0.2或更小),它的作用就是在原本模型基础上加入惩罚因子;
e为N维单位向量,加入e的原因是这个公式的前半部分是向量,因此必须将β/N转为向量才能相加。
经过随机转移概率的修正后,整个计算就变得平滑,因为每次迭代的结果除了依赖转移矩阵外,还依赖一个小概率的随机概率转移。
以该图为例:
原始转移矩阵M为:
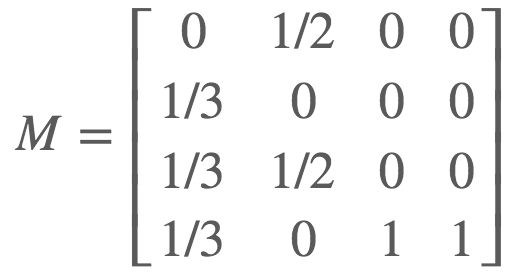
设β为0.2,则计算公式为:

如果按这个公式迭代算下去,会发现Spider Traps的效应被抑制了,从而每个页面都拥有一个合理的pagerank。
同时,即使是出现了Dead Ends,因为随机概率矩阵的存在,实际的M 也因此不存在为0的行了。
问题得到了完美的解决。
0x4:PR值计算方法
1. 幂迭代法
首先给每个页面赋予随机的PR值,然后通过![]() 不断地迭代PR值。当满足下面的不等式后迭代结束,获得所有页面的PR值:
不断地迭代PR值。当满足下面的不等式后迭代结束,获得所有页面的PR值:
# -*- coding: utf-8 -*- from pygraph.classes.digraph import digraph class PRIterator: __doc__ = '''计算一张图中的PR值''' def __init__(self, dg): self.damping_factor = 0.85 # 阻尼系数,即α self.max_iterations = 100 # 最大迭代次数 self.min_delta = 0.00001 # 确定迭代是否结束的参数,即ϵ self.graph = dg def page_rank(self): # 先将图中没有出链的节点改为对所有节点都有出链 for node in self.graph.nodes(): if len(self.graph.neighbors(node)) == 0: for node2 in self.graph.nodes(): digraph.add_edge(self.graph, (node, node2)) nodes = self.graph.nodes() graph_size = len(nodes) if graph_size == 0: return {} # 给每个节点赋予初始的PR值,第一轮的PR值是均等的,即 1/N page_rank = dict.fromkeys(nodes, 1.0 / graph_size) # 公式中的(1−α)/N部分 damping_value = (1.0 - self.damping_factor) / graph_size flag = False for i in range(self.max_iterations): change = 0 for node in nodes: rank = 0 # 遍历所有“入射”的页面 for incident_page in self.graph.incidents(node): # "入射"页面的权重根据其出链个数均分,然后传递给当前页面 rank += self.damping_factor * (page_rank[incident_page] / len(self.graph.neighbors(incident_page))) # 增加随机概率转移矩阵的部分 rank += damping_value change += abs(page_rank[node] - rank) # 绝对值 page_rank[node] = rank print("This is NO.%s iteration" % (i + 1)) print(page_rank) if change < self.min_delta: flag = True break if flag: print("finished in %s iterations!" % node) else: print("finished out of 100 iterations!") return page_rank if __name__ == '__main__': # 创建一个网络拓朴图 dg = digraph() dg.add_nodes(["A", "B", "C", "D", "E"]) dg.add_edge(("A", "B")) dg.add_edge(("A", "C")) dg.add_edge(("A", "D")) dg.add_edge(("B", "D")) dg.add_edge(("C", "E")) dg.add_edge(("D", "E")) dg.add_edge(("B", "E")) dg.add_edge(("E", "A")) # PRrank迭代计算 pr = PRIterator(dg) page_ranks = pr.page_rank() print("The final page rank is\n", page_ranks)
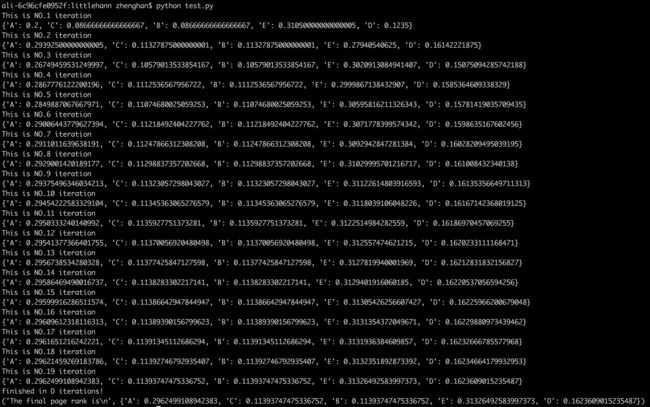
从结果上可以看出两个比较明显的规律:
1. E节点的权重是最高的,因为E的入链最多,这很显然; 2. A节点的权重次之,也很高,因为高权重E节点存在向A节点的入链;
2. 特征值法
我们知道,当Markov链收敛时,必有:

3. 代数法
类似地,当提到Markov链收敛时,必有:

Relevant Link:
http://www.cnblogs.com/fengfenggirl/p/pagerank-introduction.html https://www.letiantian.me/2014-06-10-pagerank/ https://wizardforcel.gitbooks.io/dm-algo-top10/content/pagerank.html https://blog.csdn.net/cannel_2020/article/details/7672042 https://blog.csdn.net/Young_Gy/article/details/70169649?utm_source=blogxgwz2 http://blog.codinglabs.org/articles/intro-to-pagerank.html https://blog.csdn.net/golden1314521/article/details/41597605 https://blog.csdn.net/rubinorth/article/details/52215036 https://blog.csdn.net/leadai/article/details/81230557
4. PageRank的数学原理
0x1:讨论该问题涉及到的几个数学概念
1. Perron - Frobenius定理
设 A = (aij) 是一个 n x n 的正矩阵: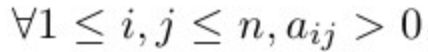 ,该矩阵有以下几个性质:
,该矩阵有以下几个性质:
1. A 存在一个正实数的特征值![]() ,叫做 Perron根 或者 Perron - Frobenius特征值,使得其他所有特征值(包括复数特征值)的规模都比它小;
,叫做 Perron根 或者 Perron - Frobenius特征值,使得其他所有特征值(包括复数特征值)的规模都比它小;
2. ![]() 只对应一个特征向量 v;
只对应一个特征向量 v;
3. ![]() 所对应的特征向量 v 的所有元素都为正实数;
所对应的特征向量 v 的所有元素都为正实数;
4. ![]() 以外的其他特征值所对应的特征向量的元素至少有一个为负数或者复数;
以外的其他特征值所对应的特征向量的元素至少有一个为负数或者复数;
5. 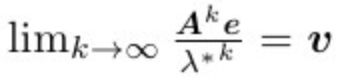
6. 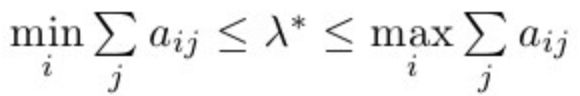
2. 正矩阵(Positive matrix)
每个矩阵元都大于0的矩阵称之为正矩阵;
每个矩阵元都大于等于0的矩阵是非负矩阵(Nonnegative matrix)
3. 素阵(Primitive matrix)
素阵是指自身的某个次幂为正矩阵(Positive matrix)的矩阵。设 A 为一个 n x n 的方阵,如果存在正整数 k 使得矩阵满足:
![]()
那么,称矩阵 A 为素矩阵。
4. 随机矩阵(stochastic matrix)
随机矩阵又叫做概率矩阵(probability matrix)、转移矩阵(transition matrix)、马尔科夫矩阵(markov matrix)等。
随机矩阵通常表示左随机矩阵(left stochastic matrix)。
如果方阵![]() 为左随机矩阵,则其满足以下条件:
为左随机矩阵,则其满足以下条件:
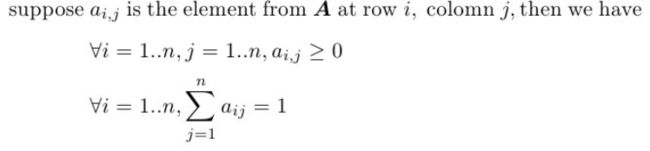
即“列和”为1
5. 不可约矩阵(irreducible matrix)
方阵A 是不可约的,当且仅当与矩阵A 对应的有向图是强连通的。
有向图 G = (V,E) 是强连通的当且仅当对每一节点对![]() ,存在 u 到 v 的路径(不一定是直接相连)。
,存在 u 到 v 的路径(不一定是直接相连)。
6. 周期图(Periodicity)
说状态 i 是周期的,并且具有周期 k > 1,是指存在一个最小的正整数 k,使得从某状态 i 出发又回到状态 i 的所有路径的长度都是 k 的整数倍。
如果一个状态不是周期的或者 k = 1,那它就是非周期的。
如果一个马尔柯夫链的所有状态都是非周期的,那么就说这个马尔柯夫链是非周期的。
下图所示,从状态1 出发回到状态1 的路径只有一条,即 1-2-3-1,需要的转移次数是3,所以这是一个周期为3 的马尔柯夫链。
0x2:权重向量收敛性问题
1. 权重向量数学公式化表示
我们从排序声望(rank prestige)的角度进一步阐述PageRank的思想:
1. 从一个网页指向另一个网页的超链接是PageRank值的隐含式传递,网页的PageRank值是由指向它的所有的网页所传递过来的PageRank值总和决定的。这样,网页 i 的入链越多,它的PageRank值就越高,它得到的声望就越高。 2. 一个网页指向多个其他网页,那么它传递的声望值就会被它所指向的多个网页分享。也就是说,即使网页 i 被一个PageRank值很高的网页 j 所指向,但是如果网页 i 的出链非常多,网页 i 从网页 j 得到的声望值可能因此被稀释地也很小
我们可以把web网络抽象成一个有向图 G = (V,E),其中 V 是图的节点集合(一个节点对应一个网页),E 是图的有向边集合(有向边对应超链接)。
设web上的网页总数为 n,即 n = | V |。上述四项可以形式化为:
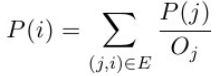 ,i = 1,2....,n
,i = 1,2....,n
其中 P(i) 表示网页 i 的PageRank值,![]() 是网页 j 出链的数量,(j,i) 表示存在网页 j 指向网页 i 的超链接。
是网页 j 出链的数量,(j,i) 表示存在网页 j 指向网页 i 的超链接。
从数学的观点看就是存在一个包含 n 个未知量的线性方程组,每个网页的权重都是一个未知量。
可以用一个矩阵来表示,首先作一个符号的约定,用列向量 P 表示 n 个网页的PageRank值,如下:
![]()
再用矩阵 A 表示有向图的邻接矩阵,并按如下规则未每条有向边赋值:
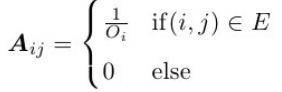
例如如下邻接矩阵 A:

我们可以得到如下方程组:
![]()
我们的任务是在已知矩阵 A 的条件下,求解向量 P。这个 P 是循环定义的,所以采用幂迭代方法求解 P。
我们定义给定初值 ![]() ,定义
,定义![]() 是经过第 n 次迭代得到的 P 值,可以形式化如下:
是经过第 n 次迭代得到的 P 值,可以形式化如下:
![]()
满足上述方程组的解![]() 就是
就是![]() 。
。
当然,也可以用马尔柯夫链(markov chain)进行建模,这时![]() 就可以看成是markov chain的一个状态(state),A 可以表示状态转移矩阵(state transition matrix),这样就可以转换成马尔柯夫链的遍历性和极限分布问题。
就可以看成是markov chain的一个状态(state),A 可以表示状态转移矩阵(state transition matrix),这样就可以转换成马尔柯夫链的遍历性和极限分布问题。
2. 收敛性的充要条件
![]() 是否收敛,取决于下面几个条件是否成立:
是否收敛,取决于下面几个条件是否成立:
1. ![]() 是否存在?
是否存在?
2. 如果极限存在,它是否与![]() 的选取有关?即收敛性是否初始值敏感?
的选取有关?即收敛性是否初始值敏感?
3. 如果极限存在,并且与![]() 的选取无关,它作为网页排序的依据是否真的合理?
的选取无关,它作为网页排序的依据是否真的合理?
如果要满足前2个问题, 转移矩阵A 必须满足以下3个条件:
1. 转移矩阵A 必须是随机矩阵; 随机矩阵要求矩阵的每一个行和都为1,即不能出现dead end节点(不存在任何出链的节点),如果web网络拓朴中存在dead end,则原始随机矩阵的条件不能成立。 但是不要忘了,因为随机概率转移矩阵(心灵矩阵)的存在,实际的M不存在为0的行,所以这第一个条件时满足的。 2. 转移矩阵A 是不可约的; 同样的道理,正常的web拓朴不一定能满足完全强连通的条件(因为Dead Ends的存在),但是因为随机概率转移矩阵(心灵矩阵)的存在,这第二个条件也成立 3. 转移矩阵A 是非周期的; 同样因为随机概率转移矩阵(心灵矩阵)的存在,周期性的定义无法满足,所以最终的转移矩阵可以说满足非周期性
上述的3个条件使得收敛性的前两个条件得到了满足。接下来还剩最后一个问题,即'网页排序的依据是否是真的合理'。
这个问题笔者是这么认为的:
所谓的“重要”,其实要看我们的目的是什么。这就跟你买车一样,有的人认为性能重要,就会更看重性能方面的指标;有的人认为颜值重要,就会更关注外观相关的指标。
而 PageRank 的发明场景是互联网网页搜索排序,佩奇认为网页之间的互相链接程度体现了网页的重要性,毕竟互联网的本质就是万物互联,一个孤立存在的网页会被认为是没有价值的,或者很不因特内的。
这又引申出另一个重要的问题,PageRank算法可以直接移植到网络安全攻防检测领域吗?先抛出一个观点:要慎重!就算可以,在大多数情况下,也需要改造原始的算法公式。
实际上,这也是笔者在项目中遇到的最多的一个问题之一。很多很秀的算法,从原理上看,明明是可以适用于网络安全领域,但是当你真的移植到你的业务场景中后,会发现,结果并不是和你预期中那么完美。造成这种问题的根本原因是什么呢?
笔者认为这是因为现在机器学习经典教材中的经典算法,虽然说起来是通用算法,但是其实它们都是因为一些具体的场景被创造出来的,最适合的也是其当初被创造出来的场景。移植到其他的问题领域后,最核心的假设前提可能改变了,算法是否能发挥出原来一样惊艳的作用,也就需要打一个问号了。
所以在实际的项目中,我们需要根据具体场景问题具体分析,对多个算法进行stacking组合,形成一个最合适的pipeline。甚至需要修改原始算法核心公式,为具体问题定制化一个专用的算法。这样才有可能真正发挥出作用。
Relevant Link:
http://www.doc88.com/p-8018027982328.html
5. 基于知乎用户粉丝进行PageRank排名
0x1:数据集
https://pan.baidu.com/s/11I8G8Wnc0W1u8RVHXDjeQA

每一行由 “账户 - 粉丝”组成。
0x2:代码示例
# -*- coding: utf-8 -*- from pygraph.classes.digraph import digraph import sqlite3 class PRIterator: __doc__ = '''计算一张图中的PR值''' def __init__(self, dg): self.damping_factor = 0.85 # 阻尼系数,即α self.max_iterations = 1000 # 最大迭代次数 self.min_delta = 0.00001 # 确定迭代是否结束的参数,即ϵ self.graph = dg def page_rank(self): # 先将图中没有出链的节点改为对所有节点都有出链 for node in self.graph.nodes(): if len(self.graph.neighbors(node)) == 0: for node2 in self.graph.nodes(): digraph.add_edge(self.graph, (node, node2)) nodes = self.graph.nodes() graph_size = len(nodes) if graph_size == 0: return {} # 给每个节点赋予初始的PR值,第一轮的PR值是均等的,即 1/N page_rank = dict.fromkeys(nodes, 1.0 / graph_size) # 公式中的(1−α)/N部分 damping_value = (1.0 - self.damping_factor) / graph_size flag = False for i in range(self.max_iterations): change = 0 for node in nodes: rank = 0 # 遍历所有“入射”的页面 for incident_page in self.graph.incidents(node): # "入射"页面的权重根据其出链个数均分,然后传递给当前页面 rank += self.damping_factor * (page_rank[incident_page] / len(self.graph.neighbors(incident_page))) # 增加随机概率转移矩阵的部分 rank += damping_value change += abs(page_rank[node] - rank) # 绝对值 page_rank[node] = rank print("This is NO.%s iteration" % (i + 1)) print(page_rank) if change < self.min_delta: flag = True break if flag: print("finished in %s iterations!" % node) else: print("finished out of 100 iterations!") return page_rank if __name__ == '__main__': # 创建一个网络拓朴图 dg = digraph() conn = sqlite3.connect('zhihu.db') c = conn.cursor() nodes = [] cursor = c.execute("SELECT DISTINCT user_url, followee_url FROM Following;") for row in cursor: #print row if row[0] not in nodes: nodes.append(row[0]) if row[1] not in nodes: nodes.append(row[1]) # 添加实体节点 dg.add_nodes(nodes) cursor = c.execute("SELECT DISTINCT user_url, followee_url FROM Following;") for row in cursor: user_url = str(row[0]) followee_url = str(row[1]) # 添加实体间link(边) followee_url -> user_url #print "followee_url:{0} -> user_url:{1}".format(followee_url, user_url) dg.add_edge((followee_url, user_url)) conn.close() # PRrank迭代计算 pr = PRIterator(dg) page_ranks = pr.page_rank() with open("page_ranks.txt", 'w') as fp: fp.write(str(page_ranks)) print("The final page rank is\n", page_ranks)

使用大数据组件进行100轮训练后,得到的pagerank排序结果如下:
node weight chengbailao 0.01406879 wind 0.00608487 neaton 0.00568152 jixin 0.00488994 zeng-kai-87 0.004726 yskin 0.00370338 hou-ye-60 0.00326399 followstars 0.00305445 yu-chen-41-39 0.00276672 gmf8541 0.00273379 _zhao_xu_ 0.0026574 zhai-huo-18 0.0026528 xushiyuzhihu 0.0025693 yueyihe 0.00212099 peng 0.00210883 bing-hou-20 0.00208451 oogoo 0.00201606 liuya802 0.0018386 mengtoy 0.0018233 yvancao 0.00176921 tang-chen 0.00174643 guo-shu-86-30 0.00168231 bhuztez 0.00165525 wang-wen-ping 0.00164296 chenxix 0.00163695 melinywu 0.0016331 chen-chen-66-21 0.00161215 ihate 0.00156636 stephen-cheng 0.00152092 boxun 0.00148928 wang-wen-ping-27 0.00148886 lxjts 0.0014828 tan-ri-tian 0.00144296 wangxiaofeng 0.00143438 zhong-ye-zi-49 0.0014341 james-swineson 0.00141263 puloon 0.0013969 mym95 0.00139541 lie-feng-2 0.00138813 susus 0.00137226 gymitat 0.00136749 fang-wen-32 0.00135586 joyneop 0.0013496 xuzhihong 0.00134178 qi-yuan-yuan-52 0.00131502 wannian 0.00130875 qiao-yang-76-30 0.00130659 bettercallsaul 0.00129384 du-forever 0.00128617 yuningyichen 0.00128111 xiao-chu 0.00126434 chen-yin-dong 0.00124541 shen0101 0.00124078 liu-yi-han-46 0.00123879 403Forbidden 0.00123664 eodoso 0.00123578 shenpp 0.00123555 dian-qian-du-dian-jian 0.00122604 anyan 0.00121871 qianjin 0.00119378 guaguaguaguaguagua 0.00115795 xie-wei-you 0.00114612 lu-zheng-29-24 0.00113225 yang-hu-85 0.00113176 yuba100 0.00113136 jueshihaojian 0.00112986 whale 0.00111578 fashiontop 0.0011137 cklover 0.00110348 zhu-yixin-42 0.00110276 mcbuder 0.00110074 quiver 0.00110009 lewhwa 0.00110006 zuo-qing-96 0.00108733 niu-yue-lao-li-xiao-chang 0.00108432 patli 0.00108025 sapereaude 0.00107575 hipara 0.00107537 GilgameshK 0.00107137 zkaip 0.00107053 sddcreerf 0.00106716 ling-er-ding-dang 0.00106533 liqiang123 0.00104595 david-du 0.00103702 aguaithefreak 0.00101756 chong 0.00100256 miaomiaomiao 0.00099407 hu-qian-qiu 0.00098814 han-yan-hui 0.00097521 songtsee 0.00096843 sun-peng-70-45 0.00096207 johnsonwang 0.00095147 hu-bi-teng 0.0009501 deutsch-99 0.00092026 lubenyuan.com 0.00091791 shijun 0.00091377 chengyuan 0.00091036 gazhi-liu 0.0008935 luo-li-10 0.00088078
0x3:通过Gephi进行可视化
Relevant Link:
http://www.cnblogs.com/fengfenggirl/p/pagerank-cnblogs.html https://github.com/BigPeng/cnblogs-user-pagerank https://www.jianshu.com/p/60ffb949113f https://www.jianshu.com/p/3b2a1895a12d