pandas读取文件官方提供的文档
在使用pandas读取文件之前,必备的内容,必然属于官方文档,官方文档查阅地址
http://pandas.pydata.org/pandas-docs/version/0.24/reference/io.html
文档操作属于pandas里面的Input/Output也就是IO操作,基本的API都在上述网址,接下来本文核心带你理解部分常用的命令
pandas读取txt文件
读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,` ,,`等特殊的分隔符
txt文件举例
下面的文件为空格间隔
1 2019-03-22 00:06:24.4463094 中文测试
2 2019-03-22 00:06:32.4565680 需要编辑encoding
3 2019-03-22 00:06:32.6835965 ashshsh
4 2017-03-22 00:06:32.8041945 eggg读取命令采用 read_csv或者 read_table都可以
import pandas as pd
df = pd.read_table("./test.txt")
print(df)
import pandas as pd
df = pd.read_csv("./test.txt")
print(df)但是,注意,这个地方读取出来的数据内容为3行1列的DataFrame类型,并没有按照我们的要求得到3行4列
import pandas as pd
df = pd.read_csv("./test.txt")
print(type(df))
print(df.shape)
(3, 1) read_csv函数
默认: 从文件、URL、文件新对象中加载带有分隔符的数据,默认分隔符是逗号。
上述txt文档并没有逗号分隔,所以在读取的时候需要增加sep分隔符参数
df = pd.read_csv("./test.txt",sep=' ')参数说明,官方Source : https://github.com/pandas-dev/pandas/blob/v0.24.0/pandas/io/parsers.py#L531-L697
中文说明以及重点功能案例
filepath_or_buffer
可以是URL,可用URL类型包括:http, ftp, s3和文件,本地文件读取实例:file://localhost/path/to/table.csv
sep
str类型,默认',' 指定分隔符。如果不指定参数,则会尝试使用默认值逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:'\r\t'
delimiter定界符,备选分隔符(如果指定该参数,则sep参数失效) 一般不用
delimiter_whitespaceTrue or False 默认False, 用空格作为分隔符等价于spe=’\s+’如果该参数被调用,则delimite不会起作用
header
指定第几行作为列名(忽略注解行),如果没有指定列名,默认header=0; 如果指定了列名header=None
names
指定列名,如果文件中不包含header的行,应该显性表示header=None ,header可以是一个整数的列表,如[0,1,3]。未指定的中间行将被删除(例如,跳过此示例中的2行)
index_col(案例1)
默认为None 用列名作为DataFrame的行标签,如果给出序列,则使用MultiIndex。如果读取某文件,该文件每行末尾都有带分隔符,考虑使用index_col=False使panadas不用第一列作为行的名称。
usecols
默认None 可以使用列序列也可以使用列名,如 [0, 1, 2] or [‘foo’, ‘bar’, ‘baz’] ,使用这个参数可以加快加载速度并降低内存消耗。
squeeze
默认为False, True的情况下返回的类型为Series,如果数据经解析后仅含一行,则返回Series
prefix
自动生成的列名编号的前缀,如: ‘X’ for X0, X1, ... 当header =None 或者没有设置header的时候有效
mangle_dupe_cols
默认为True,重复的列将被指定为’X.0’…’X.N’,而不是’X’…’X’。如果传入False,当列中存在重复名称,则会导致数据被覆盖。
dtype
例子: {‘a’: np.float64, ‘b’: np.int32} 指定每一列的数据类型,a,b表示列名
engine
使用的分析引擎。可以选择C或者是python,C引擎快但是Python引擎功能更多一些
converters(案例2)
设置指定列的处理函数,可以用"序号"也可以使用“列名”进行列的指定
true_values / false_values
没有找到实际的应用场景,备注一下,后期完善
skipinitialspace
忽略分隔符后的空格,默认false
skiprows
默认值 None 需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)
skipfooter
从文件尾部开始忽略。 (c引擎不支持)
nrows
从文件中只读取多少数据行,需要读取的行数(从文件头开始算起)
na_values
空值定义,默认情况下, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’. 都表现为NAN
keep_default_na
如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加
na_filter
是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有N/A空值,使用na_filter=False可以提升读取速度 。
verbose
是否打印各种解析器的输出信息,例如:“非数值列中缺失值的数量”等。
skip_blank_lines
如果为True,则跳过空行;否则记为NaN。
parse_dates
有如下的操作
infer_datetime_format
如果设定为True并且parse_dates 可用,那么pandas将尝试转换为日期类型,如果可以转换,转换方法并解析。在某些情况下会快5~10倍
keep_date_col
如果连接多列解析日期,则保持参与连接的列。默认为False
date_parser
用于解析日期的函数,默认使用dateutil.parser.parser来做转换。Pandas尝试使用三种不同的方式解析,如果遇到问题则使用下一种方式。
dayfirst
DD/MM格式的日期类型
iterator
返回一个TextFileReader 对象,以便逐块处理文件。
chunksize
文件块的大小
compression
直接使用磁盘上的压缩文件。如果使用infer参数,则使用 gzip, bz2, zip或者解压文件名中以‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。
新版本0.18.1版本支持zip和xz解压
thousands
千分位符号,默认‘,’
decimal
小数点符号,默认‘.’
lineterminator
行分割符,只在C解析器下使用
quotechar
引号,用作标识开始和解释的字符,引号内的分割符将被忽略
quoting
控制csv中的引号常量。可选 QUOTE_MINIMAL (0), QUOTE_ALL (1), QUOTE_NONNUMERIC (2) or QUOTE_NONE (3)
doublequote
双引号,当单引号已经被定义,并且quoting 参数不是QUOTE_NONE的时候,使用双引号表示引号内的元素作为一个元素使用。
escapechar
当quoting 为QUOTE_NONE时,指定一个字符使的不受分隔符限值。
comment
标识着多余的行不被解析。如果该字符出现在行首,这一行将被全部忽略。这个参数只能是一个字符,空行(就像skip_blank_lines=True)注释行被header和skiprows忽略一样。例如如果指定comment='#' 解析‘#empty\na,b,c\n1,2,3’ 以header=0 那么返回结果将是以’a,b,c'作为header
encoding
编码方式,指定字符集类型,通常指定为'utf-8'
dialect
如果没有指定特定的语言,如果sep大于一个字符则忽略。具体查看csv.Dialect 文档
error_bad_lines
如果一行包含太多的列,那么默认不会返回DataFrame ,如果设置成false,那么会将改行剔除(只能在C解析器下使用)
warn_bad_lines
如果error_bad_lines =False,并且warn_bad_lines =True 那么所有的“bad lines”将会被输出(只能在C解析器下使用)
low_memory
分块加载到内存,再低内存消耗中解析。但是可能出现类型混淆。确保类型不被混淆需要设置为False。或者使用dtype 参数指定类型。注意使用chunksize 或者iterator 参数分块读入会将整个文件读入到一个Dataframe,而忽略类型(只能在C解析器中有效)
delim_whitespace
New in version 0.18.1: Python解析器中有效
memory_map
如果为filepath_or_buffer提供了文件路径,则将文件对象直接映射到内存上,并直接从那里访问数据。使用此选项可以提高性能,因为不再有任何I / O开销,使用这种方式可以避免文件再次进行IO操作
float_precision
指定C引擎应用于浮点值的转换器
该表格部分参考 博客 https://www.cnblogs.com/datablog/p/6127000.html 感谢博主的翻译,O(∩_∩)O哈哈~
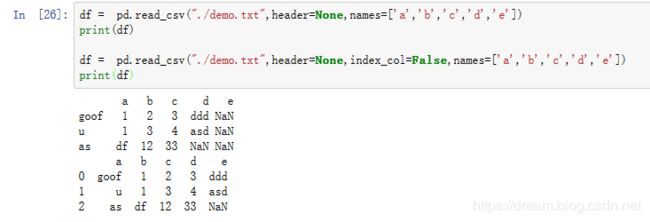
案例1
index_col 使用
goof,1,2,3,ddd,
u,1,3,4,asd,
as,df,12,33,编写如下代码
df = pd.read_csv("./demo.txt",header=None,names=['a','b','c','d','e'])
print(df)
df = pd.read_csv("./demo.txt",header=None,index_col=False,names=['a','b','c','d','e'])
print(df)
在读取文件的时候,如果不设置index_col列索引,默认会使用从0开始的整数索引。当对表格的某一行或列进行操作之后,在保存成文件的时候你会发现总是会多一列从0开始的列,如果设置index_col参数来设置列索引,就不会出现这种问题了。
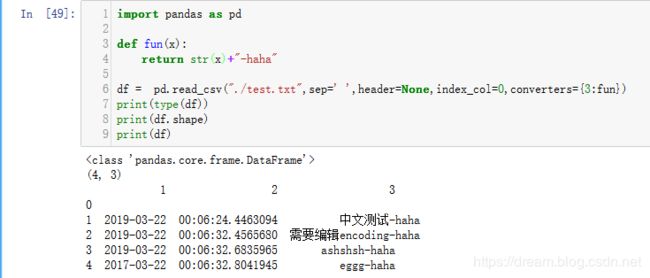
案例2
converters 设置指定列的处理函数,可以用"序号"也可以使用“列名”进行列的指定
import pandas as pd
def fun(x):
return str(x)+"-haha"
df = pd.read_csv("./test.txt",sep=' ',header=None,index_col=0,converters={3:fun})
print(type(df))
print(df.shape)
print(df)
read_csv函数过程中常见的问题
有的IDE中利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错。
解决办法
import pandas as pd
#df=pd.read_csv('F:/测试文件夹/测试数据.txt')
f=open('F:/测试文件夹/测试数据.txt')
df=pd.read_csv(f)
排除某些行 使用 参数 skiprows.它的功能为排除某一行。
对于不规则分隔符,使用正则表达式 读取文件
data = pd.read_csv("data.txt",sep="\s+") 读取的文件中如果出现中文编码错误
为行和列添加索引
read_csv该命令有相当数量的参数。大多数都是不必要的,因为你下载的大部分文件都有标准格式。
read_table函数
基本用法是一致的,区别在于separator分隔符。
read_fwf 函数
读取具有固定宽度列的文件,例如文件
id8141 360.242940 149.910199 11950.7
id1594 444.953632 166.985655 11788.4
id1849 364.136849 183.628767 11806.2
id1230 413.836124 184.375703 11916.8
id1948 502.953953 173.237159 12468.3read_fwf 命令有2个额外的参数可以设置
colspecs :
需要给一个元组列表,元组列表为半开区间,[from,to) ,默认情况下它会从前100行数据进行推断。
例子:
import pandas as pd
colspecs = [(0, 6), (8, 20), (21, 33), (34, 43)]
df = pd.read_fwf('demo.txt', colspecs=colspecs, header=None, index_col=0)widths:colspecs参数
widths = [6, 14, 13, 10]
df = pd.read_fwf('demo.txt', widths=widths, header=None)read_fwf 使用并不是很频繁,可以参照 http://pandas.pydata.org/pandas-docs/stable/user_guide/io.html#files-with-fixed-width-columns 学习
read_msgpack 函数
pandas支持的一种新的可序列化的数据格式,这是一种轻量级的可移植二进制格式,类似于二进制JSON,这种数据空间利用率高,在写入(序列化)和读取(反序列化)方面都提供了良好的性能。
read_clipboard 函数
读取剪贴板中的数据,可以看作read_table的剪贴板版本。在将网页转换为表格时很有用
这个地方出现如下的BUG
module 'pandas' has no attribute 'compat'
我更新了一下pandas 既可以正常使用了
打开site-packages\pandas\io\clipboard.py 这个文件需要自行检索
在 text = clipboard_get() 后面一行 加入这句: text = text.decode('UTF-8')
保存,然后就可以使用了
read_excel 函数
依旧是官方文档一码当先:http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html#pandas.read_excel
io
文件类对象 ,pandas Excel 文件或 xlrd 工作簿。该字符串可能是一个URL。URL包括http,ftp,s3和文件。例如,本地文件可写成file://localhost/path/to/workbook.xlsx
sheet_name
默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe,表名用字符串表示,索引表位置用整数表示;
header
指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None;
names
指定列的名字,传入一个list数据
index_col
指定列为索引列,也可以使用u”strings” ,如果传递一个列表,这些列将被组合成一个MultiIndex。
squeeze
如果解析的数据只包含一列,则返回一个Series
dtype
数据或列的数据类型,参考read_csv即可
engine
如果io不是缓冲区或路径,则必须将其设置为标识io。 可接受的值是None或xlrd
converters
参照read_csv即可
其余参数
基本和read_csv一致
pandas 读取excel文件如果报错,一般处理为
错误为:ImportError: No module named 'xlrd'
read_json 函数
path_or_buf
一个有效的JSON文件,默认值为None,字符串可以为URL,例如file://localhost/path/to/table.json
orient (案例1)
预期的json字符串格式,orient的设置有以下几个值:
typ
返回的格式(series or frame), 默认是 ‘frame’
dtype
数据或列的数据类型,参考read_csv即可
convert_axes
boolean,尝试将轴转换为正确的dtypes,默认值为True
convert_dates
解析日期的列列表;如果为True,则尝试解析类似日期的列,默认值为True
keep_default_dates
boolean,default True。如果解析日期,则解析默认的日期样列
numpy
直接解码为numpy数组。默认为False;仅支持数字数据,但标签可能是非数字的。还要注意,如果numpy=True,JSON排序MUST
precise_float
boolean,默认False。设置为在将字符串解码为双精度值时启用更高精度(strtod)函数的使用。默认值(False)是使用快速但不太精确的内置功能
date_unit
string,用于检测转换日期的时间戳单位。默认值无。默认情况下,将检测时间戳精度,如果不需要,则通过's','ms','us'或'ns'之一分别强制时间戳精度为秒,毫秒,微秒或纳秒。
encoding
json编码
lines
每行将文件读取为一个json对象。
如果JSON不可解析,解析器将产生ValueError/TypeError/AssertionError之一。
案例1
orient='split'
import pandas as pd
s = '{"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,5],[6,9]]}'
df = pd.read_json(s,orient='split')
orient='records'
import pandas as pd
s = '[{"a":1,"b":2},{"a":3,"b":4}]'
df = pd.read_json(s,orient='records')
orient='index'
s = '{"0":{"a":1,"b":2},"1":{"a":2,"b":4}}'orient='columns' 或者 values 自己推断即可
部分中文翻译,可以参考github> https://github.com/apachecn/pandas-doc-zh
read_json()常见BUG
读取json文件出现 ValueError: Trailing data ,JSON格式问题
{"a":1,"b":1},{"a":2,"b":2}调整为
[{"a":1,"b":1},{"a":2,"b":2}]或者使用lines参数,并且JSON调整为每行一条数据
{"a":1,"b":1}
{"a":2,"b":2}若JSON文件中有中文,建议加上encoding参数,赋值'utf-8',否则会报错
read_html 函数
io
接收网址、文件、字符串。网址不接受https,尝试去掉s后爬去
match
正则表达式,返回与正则表达式匹配的表格
flavor
解析器默认为‘lxml’
header
指定列标题所在的行,list为多重索引
index_col
指定行标题对应的列,list为多重索引
skiprows
跳过第n行(序列标示)或跳过n行(整数标示)
attrs
属性,比如 attrs = {'id': 'table'}
parse_dates
解析日期
使用方法,在网页中右键如果发现表格 也就是 table 即可使用
例如: http://data.stcn.com/2019/0304/14899644.shtml
: 定义表格
: 定义表格的页眉
: 定义表格的主体
: 定义表格的行
: 定义表格的表头
: 定义表格单元
常见BUG
出现如下报错 ImportError: html5lib not found, please install it
安装html5lib即可,或者使用参数
import pandas as pd
df = pd.read_html("http://data.stcn.com/2019/0304/14899644.shtml",flavor ='lxml')更多参考源码,可以参考 > http://pandas.pydata.org/pandas-docs/stable/user_guide/io.html
尾声
截止到现在,本篇博客已经完成,对于pandas读取文件,相信你应该已经有一个深入的理解了。在pandas读取文件的过程中,最常出现的问题,就是中文问题与格式问题,希望当你碰到的时候,可以完美的解决。
有任何问题,希望可以在评论区给我回复,期待和你一起进步,博客园-梦想橡皮擦
你可能感兴趣的:(深入理解pandas读取excel,txt,csv文件等命令)
微服务下功能权限与数据权限的设计与实现
nbsaas-boot
微服务 java 架构
在微服务架构下,系统的功能权限和数据权限控制显得尤为重要。随着系统规模的扩大和微服务数量的增加,如何保证不同用户和服务之间的访问权限准确、细粒度地控制,成为设计安全策略的关键。本文将讨论如何在微服务体系中设计和实现功能权限与数据权限控制。1.功能权限与数据权限的定义功能权限:指用户或系统角色对特定功能的访问权限。通常是某个用户角色能否执行某个操作,比如查看订单、创建订单、修改用户资料等。数据权限:
学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
扫地机类清洁产品之直流无刷电机控制
悟空胆好小
清洁服务机器人 单片机 人工智能
扫地机类清洁产品之直流无刷电机控制1.1前言扫地机产品有很多的电机控制,滚刷电机1个,边刷电机1-2个,清水泵电机,风机一个,部分中高端产品支持抹布功能,也就是存在抹布盘电机,还有追觅科沃斯石头等边刷抬升电机,滚刷抬升电机等的,这些电机有直流有刷电机,直接无刷电机,步进电机,电磁阀,挪动泵等不同类型。电机的原理,驱动控制方式也不行。接下来一段时间的几个文章会作个专题分析分享。直流有刷电机会自动持续
Linux下QT开发的动态库界面弹出操作(SDL2)
13jjyao
QT类 qt 开发语言 sdl2 linux
需求:操作系统为linux,开发框架为qt,做成需带界面的qt动态库,调用方为java等非qt程序难点:调用方为java等非qt程序,也就是说调用方肯定不带QApplication::exec(),缺少了这个,QTimer等事件和QT创建的窗口将不能弹出(包括opencv也是不能弹出);这与qt调用本身qt库是有本质的区别的思路:1.调用方缺QApplication::exec(),那么我们在接口
向内而求
陈陈_19b4
10月27日,阴。阅读书目:《次第花开》。作者:希阿荣博堪布,是当今藏传佛家宁玛派最伟大的上师法王,如意宝晋美彭措仁波切颇具影响力的弟子之一。多年以来,赴海内外各地弘扬佛法,以正式授课、现场开示、发表文章等多种方法指导佛学弟子修行佛法。代表作《寂静之道》、《生命这出戏》、《透过佛法看世界》自出版以来一直是佛教类书籍中的畅销书。图片发自App金句:1.佛陀说,一切痛苦的根源在于我们长期以来对自身及外
消息中间件有哪些常见类型
xmh-sxh-1314
java
消息中间件根据其设计理念和用途,可以大致分为以下几种常见类型:点对点消息队列(Point-to-PointMessagingQueues):在这种模型中,消息被发送到特定的队列中,消费者从队列中取出并处理消息。队列中的消息只能被一个消费者消费,消费后即被删除。常见的实现包括IBM的MQSeries、RabbitMQ的部分使用场景等。适用于任务分发、负载均衡等场景。发布/订阅消息模型(Pub/Sub
《大清方方案》| 第二话
谁佐清欢
和珅究竟说了些什么?竟能令堂堂九五之尊龙颜失色!此处暂且按下不表;单说这位乾隆皇帝,果真不愧是康熙从小带过的,一旦决定了要做的事,便杀伐决断毫不含糊。他当即亲自拟旨,着令和珅为钦差大臣,全权负责处理方方事件,并钦赐尚方宝剑,遇急则三品以下官员可先斩后奏。和珅身负皇上重托,岂敢有半点怠慢,当夜即率领相关人等,马不停蹄杀奔江汉。这一路上,和珅的几位幕僚一直在商讨方方事件的处置方案。有位年轻幕僚建议快刀
Python数据分析与可视化实战指南
William数据分析
python python 数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
git常用命令笔记
咩酱-小羊
git 笔记
###用习惯了idea总是不记得git的一些常见命令,需要用到的时候总是担心旁边站了人~~~记个笔记@_@,告诉自己看笔记不丢人初始化初始化一个新的Git仓库gitinit配置配置用户信息gitconfig--globaluser.name"YourName"gitconfig--globaluser.email"
[email protected] "基本操作克隆远程仓库gitclone查看
怎么起诉借钱不还的人?怎样起诉欠款不还的人?
影子爱学习
怎么起诉借钱不还的人?怎样起诉欠款不还的人?如果遇到难以解决的法律问题,我们可以匹配专业律师。例如:婚姻家庭(离婚纠纷)、刑事辩护、合同纠纷、债权债务、房产(继承)纠纷、交通事故、劳动争议、人身损害、公司相关法律事务(法律顾问)等咨询推荐手机/微信:15633770876【全国案件皆可】借钱不还起诉对方需要哪些资料起诉欠钱不还的,一般需要的材料包括以下这些:借据、收据、欠条、付款凭证等证据,以及向
相信相信的力量
孙丽_cdb3
孙丽中级十期坚持分享第345天有一个特别有哲理的故事:有一只老鹰下了蛋,这个蛋,不知怎的就滚到了鸡窝里去了,鸡也下了一窝蛋,然后鸡妈妈把这些蛋全都浮出来了,孵出来之后等小鸡长大一点了,就觉得鹰蛋孵出来的那只小鹰怪模怪样,这些小鸡都嘲笑它,真难看,真笨,丑死了,那只小鹰觉得自己真是谁也不像,真是不好看,后来鸡妈妈也不喜欢他,我怎么生出你这样的孩子来了?真烦人,后来这群小鸡和小鹰一起生活,有一天,老鹰
将cmd中命令输出保存为txt文本文件
落难Coder
Windows cmd window
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)
编程经验分享
开发工具 服务器 ssh linux
目录前言基本使用教程新建远程连接连接主机自定义命令路由追踪前言后端开发,必然需要和服务器打交道,部署应用,排查问题,查看运行日志等等。一般服务器都是集中部署在机房中,也有一些直接是云服务器,总而言之,程序员不可能直接和服务器直接操作,一般都是通过ssh连接来登录服务器。刚接触远程连接时,使用的是XSHELL来远程连接服务器,连接上就能够操作远程服务器了,但是仅用XSHELL并没有上传下载文件的功能
Git常用命令-修改远程仓库地址
猿大师
Linux Java git java
查看远程仓库地址gitremote-v返回结果originhttps://git.coding.net/*****.git(fetch)originhttps://git.coding.net/*****.git(push)修改远程仓库地址gitremoteset-urloriginhttps://git.coding.net/*****.git先删除后增加远程仓库地址gitremotermori
深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库 python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
春季养肝正当时
dxn悟
重温快乐2023年2月4日立春。春天来了,春暖花开,小鸟欢唱,那在这样的季节我们如何养肝呢?自然界的春季对应中医五行的木,人体五脏肝属木,“木曰曲直”,是以树干曲曲直直地向上、向外伸长舒展的生发姿态,来形容具有生长、升发、条达、舒畅等特征的食物及现象。根据中医天人相应的理念,肝五行属木,喜条达,主疏泄,与春天相应,所以春天最适合养肝。养肝首先要少生气,因为肝喜条达恶抑郁。人体五志肝为怒,生气发怒最
关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业 javascript html css 旅游 风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业 web设计网页规划与设计 html css javascript dreamweaver 前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
log4j配置
yy爱yy
#log4j.rootLogger配置的是大于等于当前级别的日志信息的输出#log4j.rootLogger用法:(注意appenderName可以是一个或多个)#log4j.rootLogger=日志级别,appenderName1,appenderName2,....#log4j.appender.appenderName2定义的是日志的输出方式,有两种:一种是命令行输出或者叫控制台输出,另一
【目标检测数据集】卡车数据集1073张VOC+YOLO格式
熬夜写代码的平头哥∰
目标检测 YOLO 人工智能
数据集格式:PascalVOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):1073标注数量(xml文件个数):1073标注数量(txt文件个数):1073标注类别数:1标注类别名称:["truck"]每个类别标注的框数:truck框数=1120总框数:1120使用标注工具:labelImg标注
人工智能时代,程序员如何保持核心竞争力?
jmoych
人工智能
随着AIGC(如chatgpt、midjourney、claude等)大语言模型接二连三的涌现,AI辅助编程工具日益普及,程序员的工作方式正在发生深刻变革。有人担心AI可能取代部分编程工作,也有人认为AI是提高效率的得力助手。面对这一趋势,程序员应该如何应对?是专注于某个领域深耕细作,还是广泛学习以适应快速变化的技术环境?又或者,我们是否应该将重点转向AI无法轻易替代的软技能?让我们一起探讨程序员
每日算法&面试题,大厂特训二十八天——第二十天(树)
肥学
⚡算法题⚡面试题每日精进 java 算法 数据结构
目录标题导读算法特训二十八天面试题点击直接资料领取导读肥友们为了更好的去帮助新同学适应算法和面试题,最近我们开始进行专项突击一步一步来。上一期我们完成了动态规划二十一天现在我们进行下一项对各类算法进行二十八天的一个小总结。还在等什么快来一起肥学进行二十八天挑战吧!!特别介绍小白练手专栏,适合刚入手的新人欢迎订阅编程小白进阶python有趣练手项目里面包括了像《机器人尬聊》《恶搞程序》这样的有趣文章
2022现在哪个打车软件比较好用又便宜 实惠的打车软件合集
高省APP珊珊
这是一个信息高速传播的社会。信息可以通过手机,微信,自媒体,抖音等方式进行传播。但同时这也是一个交通四通发达的社会。高省APP,是2022年推出的平台,0投资,0风险、高省APP佣金更高,模式更好,终端用户不流失。【高省】是一个自用省钱佣金高,分享推广赚钱多的平台,百度有几百万篇报道,也期待你的加入。珊珊导师,高省邀请码777777,注册送2皇冠会员,送万元推广大礼包,教你如何1年做到百万团队。高
webpack图片等资源的处理
dmengmeng
需要的loaderfile-loader(让我们可以引入这些资源文件)url-loader(其实是file-loader的二次封装)img-loader(处理图片所需要的)在没有使用任何处理图片的loader之前,比如说css中用到了背景图片,那么最后打包会报错的,因为他没办法处理图片。其实你只想能够使用图片的话。只加一个file-loader就可以,打开网页能准确看到图片。{test:/\.(p
走向以教育叙事为载体的教育叙事研究
666小飞鱼
今天我读了吴松超老师的《给教师的68条建写作建议》中的第23条《如何通过教育叙事走向研究》,吴老师在文中与我们分享了一个德育案例,这是一个反面的案例,意在告知我们在处理问题时,不能就考虑的点太窄,思考要全面。走向教育叙事研究,教师要有敏锐的“感知力”,这个感知力来自于背后专业知识的支撑,思维能力以及广阔的视野和见识等。所以对于同一件事处理方法不同,这个就是教师背后“敏锐力”的不同造成的,也就是说是
钢筋长度超限检测检数据集VOC+YOLO格式215张1类别
futureflsl
数据集 YOLO 深度学习 机器学习
数据集格式:PascalVOC格式+YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):215标注数量(xml文件个数):215标注数量(txt文件个数):215标注类别数:1标注类别名称:["iron"]每个类别标注的框数:iron框数=215总框数:215使用标注工具:labelImg标注规则:对类别进
CX8903:Ebike自行车仪表电源方案开发,Ebike智能仪表电源芯片
诚芯微科技
社交电子
CX8903:电动Ebike自行车仪表电源方案开发,Ebike智能仪表电源芯片推荐。电动助力自行车EBIKE凭借其环保、健康、低噪、和便捷等特点,成为了越来越受欢迎的骑行便利交通工具。提供电动Ebike自行车仪表电源方案开发、E-BIKE电动助力自行车仪表供电电源解决方案。CX8903采用100V高压制造工艺(芯片最高耐压可到100V以上),SOP-8L贴片封装,CX8903内置100V/90mΩ
CX8836:小体积大功率升降压方案推荐(附Demo设计指南)
诚芯微科技
社交电子
CX8836是一颗同步四开关单向升降压控制器,在4.5V-40V宽输入电压范围内稳定工作,持续负载电流10A,能够在输入高于或低于输出电压时稳定调节输出电压,可适用于USBPD快充、车载充电器、HUB、汽车启停系统、工业PC电源等多种升降压应用场合,为大功率TYPE-CPD车载充电器提供最优解决方案。提供CX8836Demo测试、CX8836样品申请及CX8836方案开发技术支持。CX8836同升
穷人做什么生意最赚钱?10个适合穷人赚钱的路子?
氧惠爱高省
不管在什么地方,一般都是穷人占大量数,而富人只有少数,但是它们却掌握着大量的财富。对于穷人来说,想要买车、买房等奢侈品就难如登天,因为他们只能通过打工来赚取几千元的月薪。➤推荐网购返利app“氧惠”,一个领隐藏优惠券+现金返利的平台。氧惠只提供领券返利链接,下单全程都在淘宝、京东、拼多多等原平台,更支持抖音、快手电商、外卖红包返利等。(应用市场搜“氧惠”下载,邀请码:521521,全网优惠上氧惠!
高级 ECharts 技巧:自定义图表主题与样式
SnowMan1993
echarts 信息可视化 数据分析
ECharts是一个强大的数据可视化库,提供了多种内置主题和样式,但你也可以根据项目的设计需求,自定义图表的主题与样式。本文将介绍如何使用ECharts自定义图表主题,以提升数据可视化的吸引力和一致性。1.什么是ECharts主题?ECharts的主题是指定义图表样式的配置项,包括颜色、字体、线条样式等。通过预设主题,你可以快速更改图表的整体风格,而自定义主题则允许你在此基础上进行个性化设置。2.
对于规范和实现,你会混淆吗?
yangshangchuan
HotSpot
昨晚和朋友聊天,喝了点咖啡,由于我经常喝茶,很长时间没喝咖啡了,所以失眠了,于是起床读JVM规范,读完后在朋友圈发了一条信息:
JVM Run-Time Data Areas:The Java Virtual Machine defines various run-time data areas that are used during execution of a program. So
android 网络
百合不是茶
网络
android的网络编程和java的一样没什么好分析的都是一些死的照着写就可以了,所以记录下来 方便查找 , 服务器使用的是TomCat
服务器代码; servlet的使用需要在xml中注册
package servlet;
import java.io.IOException;
import java.util.Arr
[读书笔记]读法拉第传
comsci
读书笔记
1831年的时候,一年可以赚到1000英镑的人..应该很少的...
要成为一个科学家,没有足够的资金支持,很多实验都无法完成
但是当钱赚够了以后....就不能够一直在商业和市场中徘徊......
随机数的产生
沐刃青蛟
随机数
c++中阐述随机数的方法有两种:
一是产生假随机数(不管操作多少次,所产生的数都不会改变)
这类随机数是使用了默认的种子值产生的,所以每次都是一样的。
//默认种子
for (int i = 0; i < 5; i++)
{
cout<<
PHP检测函数所在的文件名
IT独行者
PHP 函数
很简单的功能,用到PHP中的反射机制,具体使用的是ReflectionFunction类,可以获取指定函数所在PHP脚本中的具体位置。 创建引用脚本。
代码:
[php]
view plain
copy
// Filename: functions.php
<?php&nbs
银行各系统功能简介
文强chu
金融
银行各系统功能简介 业务系统 核心业务系统 业务功能包括:总账管理、卡系统管理、客户信息管理、额度控管、存款、贷款、资金业务、国际结算、支付结算、对外接口等 清分清算系统 以清算日期为准,将账务类交易、非账务类交易的手续费、代理费、网络服务费等相关费用,按费用类型计算应收、应付金额,经过清算人员确认后上送核心系统完成结算的过程 国际结算系
Python学习1(pip django 安装以及第一个project)
小桔子
python django pip
最近开始学习python,要安装个pip的工具。听说这个工具很强大,安装了它,在安装第三方工具的话so easy!然后也下载了,按照别人给的教程开始安装,奶奶的怎么也安装不上!
第一步:官方下载pip-1.5.6.tar.gz, https://pypi.python.org/pypi/pip easy!
第二部:解压这个压缩文件,会看到一个setup.p
php 数组
aichenglong
PHP 排序 数组 循环 多维数组
1 php中的创建数组
$product = array('tires','oil','spark');//array()实际上是语言结构而不 是函数
2 如果需要创建一个升序的排列的数字保存在一个数组中,可以使用range()函数来自动创建数组
$numbers=range(1,10)//1 2 3 4 5 6 7 8 9 10
$numbers=range(1,10,
安装python2.7
AILIKES
python
安装python2.7
1、下载可从 http://www.python.org/进行下载#wget https://www.python.org/ftp/python/2.7.10/Python-2.7.10.tgz
2、复制解压
#mkdir -p /opt/usr/python
#cp /opt/soft/Python-2
java异常的处理探讨
百合不是茶
JAVA异常
//java异常
/*
1,了解java 中的异常处理机制,有三种操作
a,声明异常
b,抛出异常
c,捕获异常
2,学会使用try-catch-finally来处理异常
3,学会如何声明异常和抛出异常
4,学会创建自己的异常
*/
//2,学会使用try-catch-finally来处理异常
getElementsByName实例
bijian1013
element
实例1:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/x
探索JUnit4扩展:Runner
bijian1013
java 单元测试 JUnit
参加敏捷培训时,教练提到Junit4的Runner和Rule,于是特上网查一下,发现很多都讲的太理论,或者是举的例子实在是太牵强。多搜索了几下,搜索到两篇我觉得写的非常好的文章。
文章地址:http://www.blogjava.net/jiangshachina/archive/20
[MongoDB学习笔记二]MongoDB副本集
bit1129
mongodb
1. 副本集的特性
1)一台主服务器(Primary),多台从服务器(Secondary)
2)Primary挂了之后,从服务器自动完成从它们之中选举一台服务器作为主服务器,继续工作,这就解决了单点故障,因此,在这种情况下,MongoDB集群能够继续工作
3)挂了的主服务器恢复到集群中只能以Secondary服务器的角色加入进来
2
【Spark八十一】Hive in the spark assembly
bit1129
assembly
Spark SQL supports most commonly used features of HiveQL. However, different HiveQL statements are executed in different manners:
1. DDL statements (e.g. CREATE TABLE, DROP TABLE, etc.)
Nginx问题定位之监控进程异常退出
ronin47
nginx在运行过程中是否稳定,是否有异常退出过?这里总结几项平时会用到的小技巧。
1. 在error.log中查看是否有signal项,如果有,看看signal是多少。
比如,这是一个异常退出的情况:
$grep signal error.log
2012/12/24 16:39:56 [alert] 13661#0: worker process 13666 exited on s
No grammar constraints (DTD or XML schema).....两种解决方法
byalias
xml
方法一:常用方法 关闭XML验证
工具栏:windows => preferences => xml => xml files => validation => Indicate when no grammar is specified:选择Ignore即可。
方法二:(个人推荐)
添加 内容如下
<?xml version=
Netty源码学习-DefaultChannelPipeline
bylijinnan
netty
package com.ljn.channel;
/**
* ChannelPipeline采用的是Intercepting Filter 模式
* 但由于用到两个双向链表和内部类,这个模式看起来不是那么明显,需要仔细查看调用过程才发现
*
* 下面对ChannelPipeline作一个模拟,只模拟关键代码:
*/
public class Pipeline {
MYSQL数据库常用备份及恢复语句
chicony
mysql
备份MySQL数据库的命令,可以加选不同的参数选项来实现不同格式的要求。
mysqldump -h主机 -u用户名 -p密码 数据库名 > 文件
备份MySQL数据库为带删除表的格式,能够让该备份覆盖已有数据库而不需要手动删除原有数据库。
mysqldump -–add-drop-table -uusername -ppassword databasename > ba
小白谈谈云计算--基于Google三大论文
CrazyMizzz
Google 云计算 GFS
之前在没有接触到云计算之前,只是对云计算有一点点模糊的概念,觉得这是一个很高大上的东西,似乎离我们大一的还很远。后来有机会上了一节云计算的普及课程吧,并且在之前的一周里拜读了谷歌三大论文。不敢说理解,至少囫囵吞枣啃下了一大堆看不明白的理论。现在就简单聊聊我对于云计算的了解。
我先说说GFS
&n
hadoop 平衡空间设置方法
daizj
hadoop balancer
在hdfs-site.xml中增加设置balance的带宽,默认只有1M:
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>10485760</value>
<description&g
Eclipse程序员要掌握的常用快捷键
dcj3sjt126com
编程
判断一个人的编程水平,就看他用键盘多,还是鼠标多。用键盘一是为了输入代码(当然了,也包括注释),再有就是熟练使用快捷键。 曾有人在豆瓣评
《卓有成效的程序员》:“人有多大懒,才有多大闲”。之前我整理了一个
程序员图书列表,目的也就是通过读书,让程序员变懒。 程序员作为特殊的群体,有的人可以这么懒,懒到事情都交给机器去做,而有的人又可以那么勤奋,每天都孜孜不倦得
Android学习之路
dcj3sjt126com
Android学习
转自:http://blog.csdn.net/ryantang03/article/details/6901459
以前有J2EE基础,接触JAVA也有两三年的时间了,上手Android并不困难,思维上稍微转变一下就可以很快适应。以前做的都是WEB项目,现今体验移动终端项目,让我越来越觉得移动互联网应用是未来的主宰。
下面说说我学习Android的感受,我学Android首先是看MARS的视
java 遍历Map的四种方法
eksliang
java HashMap java 遍历Map的四种方法
转载请出自出处:
http://eksliang.iteye.com/blog/2059996
package com.ickes;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
/**
* 遍历Map的四种方式
【精典】数据库相关相关
gengzg
数据库
package C3P0;
import java.sql.Connection;
import java.sql.SQLException;
import java.beans.PropertyVetoException;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class DBPool{
自动补全
huyana_town
自动补全
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml&quo
jquery在线预览PDF文件,打开PDF文件
天梯梦
jquery
最主要的是使用到了一个jquery的插件jquery.media.js,使用这个插件就很容易实现了。
核心代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.
ViewPager刷新单个页面的方法
lovelease
android viewpager tag 刷新
使用ViewPager做滑动切换图片的效果时,如果图片是从网络下载的,那么再子线程中下载完图片时我们会使用handler通知UI线程,然后UI线程就可以调用mViewPager.getAdapter().notifyDataSetChanged()进行页面的刷新,但是viewpager不同于listview,你会发现单纯的调用notifyDataSetChanged()并不能刷新页面
利用按位取反(~)从复合枚举值里清除枚举值
草料场
enum
以 C# 中的 System.Drawing.FontStyle 为例。
如果需要同时有多种效果,
如:“粗体”和“下划线”的效果,可以用按位或(|)
FontStyle style = FontStyle.Bold | FontStyle.Underline;
如果需要去除 style 里的某一种效果,
Linux系统新手学习的11点建议
刘星宇
编程 工作 linux 脚本
随着Linux应用的扩展许多朋友开始接触Linux,根据学习Windwos的经验往往有一些茫然的感觉:不知从何处开始学起。这里介绍学习Linux的一些建议。
一、从基础开始:常常有些朋友在Linux论坛问一些问题,不过,其中大多数的问题都是很基础的。例如:为什么我使用一个命令的时候,系统告诉我找不到该目录,我要如何限制使用者的权限等问题,这些问题其实都不是很难的,只要了解了 Linu
hibernate dao层应用之HibernateDaoSupport二次封装
wangzhezichuan
DAO Hibernate
/**
* <p>方法描述:sql语句查询 返回List<Class> </p>
* <p>方法备注: Class 只能是自定义类 </p>
* @param calzz
* @param sql
* @return
* <p>创建人:王川</p>
* <p>创建时间:Jul