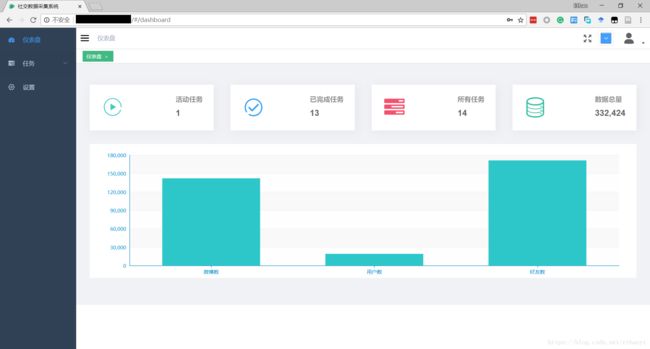
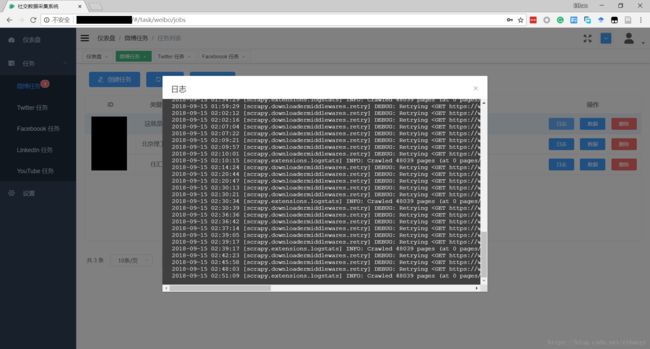
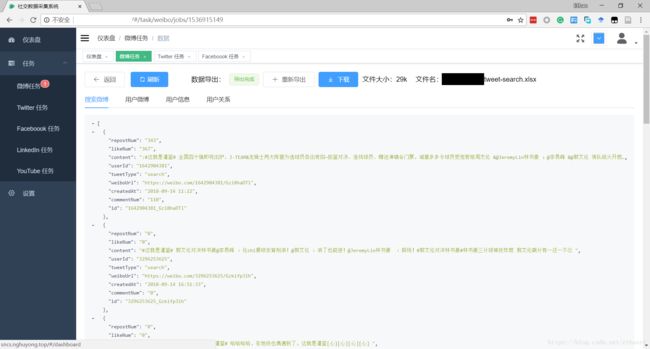
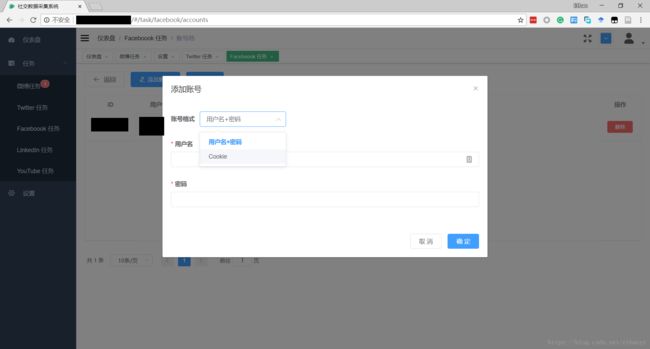
- android系统selinux中添加新属性property
辉色投像
1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property
- 谢谢你们,爱你们!
鹿游儿
昨天家人去泡温泉,二个孩子也带着去,出发前一晚,匆匆下班,赶回家和孩子一起收拾。饭后,我拿出笔和本子(上次去澳门时做手帐的本子)写下了1\2\3\4\5\6\7\8\9,让后让小壹去思考,带什么出发去旅游呢?她在对应的数字旁边画上了,泳衣、泳圈、肖恩、内衣内裤、tapuy、拖鞋……画完后,就让她自己对着这个本子,将要带的,一一带上,没想到这次带的书还是这本《便便工厂》(晚上姑婆发照片过来,妹妹累得
- 微服务下功能权限与数据权限的设计与实现
nbsaas-boot
微服务java架构
在微服务架构下,系统的功能权限和数据权限控制显得尤为重要。随着系统规模的扩大和微服务数量的增加,如何保证不同用户和服务之间的访问权限准确、细粒度地控制,成为设计安全策略的关键。本文将讨论如何在微服务体系中设计和实现功能权限与数据权限控制。1.功能权限与数据权限的定义功能权限:指用户或系统角色对特定功能的访问权限。通常是某个用户角色能否执行某个操作,比如查看订单、创建订单、修改用户资料等。数据权限:
- 小丽成长记(四十三)
玲玲54321
小丽发现,即使她好不容易调整好自己的心态下一秒总会有不确定的伤脑筋的事出现,一个接一个的问题,人生就没有停下的时候,小问题不断出现。不过她今天看的书,她接受了人生就是不确定的,厉害的人就是不断创造确定性,在Ta的领域比别人多的确定性就能让自己脱颖而出,显示价值从而获得的比别人多的利益。正是这样的原因,因为从前修炼自己太少,使得她现在在人生道路上打怪起来困难重重,她似乎永远摆脱不了那种无力感,有种习
- 学点心理知识,呵护孩子健康
静候花开_7090
昨天听了华中师范大学教育管理学系副教授张玲老师的《哪里才是学生心理健康的最后庇护所,超越教育与技术的思考》的讲座。今天又重新学习了一遍,收获匪浅。张玲博士也注意到了当今社会上的孩子由于心理问题导致的自残、自杀及伤害他人等恶性事件。她向我们普及了一个重要的命题,她说心理健康的一些基本命题,我们与我们通常的一些教育命题是不同的,她还举了几个例子,让我们明白我们原来以为的健康并非心理学上的健康。比如如果
- 扫地机类清洁产品之直流无刷电机控制
悟空胆好小
清洁服务机器人单片机人工智能
扫地机类清洁产品之直流无刷电机控制1.1前言扫地机产品有很多的电机控制,滚刷电机1个,边刷电机1-2个,清水泵电机,风机一个,部分中高端产品支持抹布功能,也就是存在抹布盘电机,还有追觅科沃斯石头等边刷抬升电机,滚刷抬升电机等的,这些电机有直流有刷电机,直接无刷电机,步进电机,电磁阀,挪动泵等不同类型。电机的原理,驱动控制方式也不行。接下来一段时间的几个文章会作个专题分析分享。直流有刷电机会自动持续
- Linux下QT开发的动态库界面弹出操作(SDL2)
13jjyao
QT类qt开发语言sdl2linux
需求:操作系统为linux,开发框架为qt,做成需带界面的qt动态库,调用方为java等非qt程序难点:调用方为java等非qt程序,也就是说调用方肯定不带QApplication::exec(),缺少了这个,QTimer等事件和QT创建的窗口将不能弹出(包括opencv也是不能弹出);这与qt调用本身qt库是有本质的区别的思路:1.调用方缺QApplication::exec(),那么我们在接口
- 我校举行新老教师师徒结对仪式暨名师专业工作室工作交流活动
李蕾1229
为促进我校教师专业发展,发挥骨干教师的引领带头作用,11月6日下午,我校举行新老教师师徒结对仪式暨名师专业工作室工作交流活动。图片发自App会议由教师发展处李蕾主任主持,首先,由范校长宣读新老教师结对名单及双方承担职责。随后,两位新调入教师陈玉萍、莫正杰分别和他们的师傅鲍元美、刘召彬老师签订了师徒结对协议书。图片发自App图片发自App师徒拥抱、握手。有了师傅就有了目标有了方向,相信两位新教师在师
- 向内而求
陈陈_19b4
10月27日,阴。阅读书目:《次第花开》。作者:希阿荣博堪布,是当今藏传佛家宁玛派最伟大的上师法王,如意宝晋美彭措仁波切颇具影响力的弟子之一。多年以来,赴海内外各地弘扬佛法,以正式授课、现场开示、发表文章等多种方法指导佛学弟子修行佛法。代表作《寂静之道》、《生命这出戏》、《透过佛法看世界》自出版以来一直是佛教类书籍中的畅销书。图片发自App金句:1.佛陀说,一切痛苦的根源在于我们长期以来对自身及外
- 消息中间件有哪些常见类型
xmh-sxh-1314
java
消息中间件根据其设计理念和用途,可以大致分为以下几种常见类型:点对点消息队列(Point-to-PointMessagingQueues):在这种模型中,消息被发送到特定的队列中,消费者从队列中取出并处理消息。队列中的消息只能被一个消费者消费,消费后即被删除。常见的实现包括IBM的MQSeries、RabbitMQ的部分使用场景等。适用于任务分发、负载均衡等场景。发布/订阅消息模型(Pub/Sub
- 《大清方方案》| 第二话
谁佐清欢
和珅究竟说了些什么?竟能令堂堂九五之尊龙颜失色!此处暂且按下不表;单说这位乾隆皇帝,果真不愧是康熙从小带过的,一旦决定了要做的事,便杀伐决断毫不含糊。他当即亲自拟旨,着令和珅为钦差大臣,全权负责处理方方事件,并钦赐尚方宝剑,遇急则三品以下官员可先斩后奏。和珅身负皇上重托,岂敢有半点怠慢,当夜即率领相关人等,马不停蹄杀奔江汉。这一路上,和珅的几位幕僚一直在商讨方方事件的处置方案。有位年轻幕僚建议快刀
- Python数据分析与可视化实战指南
William数据分析
pythonpython数据
在数据驱动的时代,Python因其简洁的语法、强大的库生态系统以及活跃的社区,成为了数据分析与可视化的首选语言。本文将通过一个详细的案例,带领大家学习如何使用Python进行数据分析,并通过可视化来直观呈现分析结果。一、环境准备1.1安装必要库在开始数据分析和可视化之前,我们需要安装一些常用的库。主要包括pandas、numpy、matplotlib和seaborn等。这些库分别用于数据处理、数学
- 怎么起诉借钱不还的人?怎样起诉欠款不还的人?
影子爱学习
怎么起诉借钱不还的人?怎样起诉欠款不还的人?如果遇到难以解决的法律问题,我们可以匹配专业律师。例如:婚姻家庭(离婚纠纷)、刑事辩护、合同纠纷、债权债务、房产(继承)纠纷、交通事故、劳动争议、人身损害、公司相关法律事务(法律顾问)等咨询推荐手机/微信:15633770876【全国案件皆可】借钱不还起诉对方需要哪些资料起诉欠钱不还的,一般需要的材料包括以下这些:借据、收据、欠条、付款凭证等证据,以及向
- 相信相信的力量
孙丽_cdb3
孙丽中级十期坚持分享第345天有一个特别有哲理的故事:有一只老鹰下了蛋,这个蛋,不知怎的就滚到了鸡窝里去了,鸡也下了一窝蛋,然后鸡妈妈把这些蛋全都浮出来了,孵出来之后等小鸡长大一点了,就觉得鹰蛋孵出来的那只小鹰怪模怪样,这些小鸡都嘲笑它,真难看,真笨,丑死了,那只小鹰觉得自己真是谁也不像,真是不好看,后来鸡妈妈也不喜欢他,我怎么生出你这样的孩子来了?真烦人,后来这群小鸡和小鹰一起生活,有一天,老鹰
- 从鸡肉高汤到记忆的魔法再到有效提示的艺术
步子哥
人工智能
还记得小时候那些天马行空的白日梦吗?也许只要按下键盘上的某个神奇组合,电脑就会发出滴滴的声响,一个隐藏的世界突然在你眼前展开,让你获得超凡的能力,摆脱平凡的生活。这听起来像是玩过太多电子游戏的幻想,但实际上,间隔重复系统给人的感觉惊人地相似。在最佳状态下,这些系统就像魔法一样神奇。本文将以一个看似平凡的鸡肉高汤食谱为例,深入浅出地探讨如何编写有效的间隔重复提示,让你像掌握烹饪技巧一样轻松地掌握记忆
- 感赏日志133
马姐读书
图片发自App感赏自己今天买个扫地机,以后可以解放出来多看点书,让这个智能小机器人替我工作了。感赏孩子最近进步很大,每天按时上学,认真听课,认真背书,主动认真完成老师布置的作业。感赏自己明白自己容易受到某人的影响,心情不好,每当此刻我就会舒缓,感赏,让自己尽快抽离,想好的一面。感赏儿子今天在我提醒他事情时,告诉我谢谢妈妈对我的提醒我明白了,而不是说我啰嗦,管事情,孩子更懂事了,懂得感恩了。投射父母
- PHP环境搭建详细教程
好看资源平台
前端php
PHP是一个流行的服务器端脚本语言,广泛用于Web开发。为了使PHP能够在本地或服务器上运行,我们需要搭建一个合适的PHP环境。本教程将结合最新资料,介绍在不同操作系统上搭建PHP开发环境的多种方法,包括Windows、macOS和Linux系统的安装步骤,以及本地和Docker环境的配置。1.PHP环境搭建概述PHP环境的搭建主要分为以下几类:集成开发环境:例如XAMPP、WAMP、MAMP,这
- 基于社交网络算法优化的二维最大熵图像分割
智能算法研学社(Jack旭)
智能优化算法应用图像分割算法php开发语言
智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码文章目录智能优化算法应用:基于社交网络优化的二维最大熵图像阈值分割-附代码1.前言2.二维最大熵阈值分割原理3.基于社交网络优化的多阈值分割4.算法结果:5.参考文献:6.Matlab代码摘要:本文介绍基于最大熵的图像分割,并且应用社交网络算法进行阈值寻优。1.前言阅读此文章前,请阅读《图像分割:直方图区域划分及信息统计介绍》htt
- 《中华小厨师》单行VS爱藏:姜是老的辣,书是新的好
cicoky
《汉书·郦食其传》有曰:“王者以民为天,而民以食为天。”自古以来,吃饱饭是每一个人的基本要求,而吃好饭却是每一个人的最终追求。于是,厨师这一职业孕育而生,其渊源之久,甚至可追溯到4000年前的奴隶时代。职业本身无贵贱,但职业能力却有高低之分。所以一家餐馆生意好不好,厨师的水平决定一切,而站在所有厨师顶端的就被称之为“特级厨师”。今天要说的就是一个关于“特级厨师刘昴星”的故事。连载历程1995年第4
- 读《人世间》有感
一0一
这个寒假,就如同朋友圈中的一段话:一闭眼,一睁眼假期还有5天,在一闭眼一睁眼假期还有12天;再一闭眼一睁眼假期还有20天;不敢睡,不敢睡啊……受疫情影响,这个假期变得漫长又煎熬,我也无时无刻不关注着疫情的变化。当然这样的一个假期,我还真得要感谢周翔,因为他有个爱看书的习惯,所以家里有不少他看过的书,可以让我随意挑选,因此也让我的假期不至于那么无所事事。这次我选了一本梁晓声的《人世间》,作为一名语文
- 2023-04-17|篮球女孩
长一木
1小学抑或初中阶段,在课外书了解到她的故事。“篮球女孩”。当时佩服她的顽强,也对生命多了一丝敬畏。今天刚好在公众号看到,长大后的“篮球女孩”。佩服之余又满是心疼。网络侵删祝那素未蒙面的女孩,未来一切顺遂。
- 【加密社】Solidity 中的事件机制及其应用
加密社
闲侃区块链智能合约区块链
加密社引言在Solidity合约开发过程中,事件(Events)是一种非常重要的机制。它们不仅能够让开发者记录智能合约的重要状态变更,还能够让外部系统(如前端应用)监听这些状态的变化。本文将详细介绍Solidity中的事件机制以及如何利用不同的手段来触发、监听和获取这些事件。事件存储的地方当我们在Solidity合约中使用emit关键字触发事件时,该事件会被记录在区块链的交易收据中。具体而言,事件
- 从0到500+,我是如何利用自媒体赚钱?
一列脚印
运营公众号半个多月,从零基础的小白到现在慢慢懂了一些运营的知识。做好公众号是很不容易的,要做很多事情;排版、码字、引流…通通需要自己解决,业余时间全都花费在这上面涨这么多粉丝是真的不容易,对比知乎大佬来说,我们这种没资源,没人脉,还没钱的小透明来说,想要一个月涨粉上万,怕是今天没睡醒(不过你有的方法,算我piapia打脸)至少我是清醒的,自己慢慢努力,实现我的万粉目标!大家快来围观、支持我吧!孩子
- 使用Faiss进行高效相似度搜索
llzwxh888
faisspython
在现代AI应用中,快速和高效的相似度搜索是至关重要的。Faiss(FacebookAISimilaritySearch)是一个专门用于快速相似度搜索和聚类的库,特别适用于高维向量。本文将介绍如何使用Faiss来进行相似度搜索,并结合Python代码演示其基本用法。什么是Faiss?Faiss是一个由FacebookAIResearch团队开发的开源库,主要用于高维向量的相似性搜索和聚类。Faiss
- 利用LangChain的StackExchange组件实现智能问答系统
nseejrukjhad
langchainmicrosoft数据库python
利用LangChain的StackExchange组件实现智能问答系统引言在当今的软件开发世界中,StackOverflow已经成为程序员解决问题的首选平台之一。而LangChain作为一个强大的AI应用开发框架,提供了StackExchange组件,使我们能够轻松地将StackOverflow的海量知识库集成到我们的应用中。本文将详细介绍如何使用LangChain的StackExchange组件
- 在一台Ubuntu计算机上构建Hyperledger Fabric网络
落叶无声9
区块链超级账本Hyperledgerfabric区块链ubuntu构建hyperledgerfabric
在一台Ubuntu计算机上构建HyperledgerFabric网络Hyperledgerfabric是一个开源的区块链应用程序平台,为开发基于区块链的应用程序提供了一个起点。当我们提到HyperledgerFabric网络时,我们指的是使用HyperledgerFabric的正在运行的系统。即使只使用最少数量的组件,部署Fabric网络也不是一件容易的事。Fabric社区创建了一个名为Cello
- GitHub上克隆项目
bigbig猩猩
github
从GitHub上克隆项目是一个简单且直接的过程,它允许你将远程仓库中的项目复制到你的本地计算机上,以便进行进一步的开发、测试或学习。以下是一个详细的步骤指南,帮助你从GitHub上克隆项目。一、准备工作1.安装Git在克隆GitHub项目之前,你需要在你的计算机上安装Git工具。Git是一个开源的分布式版本控制系统,用于跟踪和管理代码变更。你可以从Git的官方网站(https://git-scm.
- 春季养肝正当时
dxn悟
重温快乐2023年2月4日立春。春天来了,春暖花开,小鸟欢唱,那在这样的季节我们如何养肝呢?自然界的春季对应中医五行的木,人体五脏肝属木,“木曰曲直”,是以树干曲曲直直地向上、向外伸长舒展的生发姿态,来形容具有生长、升发、条达、舒畅等特征的食物及现象。根据中医天人相应的理念,肝五行属木,喜条达,主疏泄,与春天相应,所以春天最适合养肝。养肝首先要少生气,因为肝喜条达恶抑郁。人体五志肝为怒,生气发怒最
- 关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业javascripthtmlcss旅游风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- apache ftpserver-CentOS config
gengzg
apache
<server xmlns="http://mina.apache.org/ftpserver/spring/v1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://mina.apache.o
- 优化MySQL数据库性能的八种方法
AILIKES
sqlmysql
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很
- JeeSite 企业信息化快速开发平台
Kai_Ge
JeeSite
JeeSite 企业信息化快速开发平台
平台简介
JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的开源Java EE快速开发平台。
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓存,Activit为工作流
- 通过Spring Mail Api发送邮件
120153216
邮件main
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri
- Pysvn 程序员使用指南
2002wmj
SVN
源文件:http://ju.outofmemory.cn/entry/35762
这是一篇关于pysvn模块的指南.
完整和详细的API请参考 http://pysvn.tigris.org/docs/pysvn_prog_ref.html.
pysvn是操作Subversion版本控制的Python接口模块. 这个API接口可以管理一个工作副本, 查询档案库, 和同步两个.
该
- 在SQLSERVER中查找被阻塞和正在被阻塞的SQL
357029540
SQL Server
SELECT R.session_id AS BlockedSessionID ,
S.session_id AS BlockingSessionID ,
Q1.text AS Block
- Intent 常用的用法备忘
7454103
.netandroidGoogleBlogF#
Intent
应该算是Android中特有的东西。你可以在Intent中指定程序 要执行的动作(比如:view,edit,dial),以及程序执行到该动作时所需要的资料 。都指定好后,只要调用startActivity(),Android系统 会自动寻找最符合你指定要求的应用 程序,并执行该程序。
下面列出几种Intent 的用法
显示网页:
- Spring定时器时间配置
adminjun
spring时间配置定时器
红圈中的值由6个数字组成,中间用空格分隔。第一个数字表示定时任务执行时间的秒,第二个数字表示分钟,第三个数字表示小时,后面三个数字表示日,月,年,< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
测试的时候,由于是每天定时执行,所以后面三个数
- POJ 2421 Constructing Roads 最小生成树
aijuans
最小生成树
来源:http://poj.org/problem?id=2421
题意:还是给你n个点,然后求最小生成树。特殊之处在于有一些点之间已经连上了边。
思路:对于已经有边的点,特殊标记一下,加边的时候把这些边的权值赋值为0即可。这样就可以既保证这些边一定存在,又保证了所求的结果正确。
代码:
#include <iostream>
#include <cstdio>
- 重构笔记——提取方法(Extract Method)
ayaoxinchao
java重构提炼函数局部变量提取方法
提取方法(Extract Method)是最常用的重构手法之一。当看到一个方法过长或者方法很难让人理解其意图的时候,这时候就可以用提取方法这种重构手法。
下面是我学习这个重构手法的笔记:
提取方法看起来好像仅仅是将被提取方法中的一段代码,放到目标方法中。其实,当方法足够复杂的时候,提取方法也会变得复杂。当然,如果提取方法这种重构手法无法进行时,就可能需要选择其他
- 为UILabel添加点击事件
bewithme
UILabel
默认情况下UILabel是不支持点击事件的,网上查了查居然没有一个是完整的答案,现在我提供一个完整的代码。
UILabel *l = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, listV.frame.size.width - 60, listV.frame.size.height)]
- NoSQL数据库之Redis数据库管理(PHP-REDIS实例)
bijian1013
redis数据库NoSQL
一.redis.php
<?php
//实例化
$redis = new Redis();
//连接服务器
$redis->connect("localhost");
//授权
$redis->auth("lamplijie");
//相关操
- SecureCRT使用备注
bingyingao
secureCRT每页行数
SecureCRT日志和卷屏行数设置
一、使用securecrt时,设置自动日志记录功能。
1、在C:\Program Files\SecureCRT\下新建一个文件夹(也就是你的CRT可执行文件的路径),命名为Logs;
2、点击Options -> Global Options -> Default Session -> Edite Default Sett
- 【Scala九】Scala核心三:泛型
bit1129
scala
泛型类
package spark.examples.scala.generics
class GenericClass[K, V](val k: K, val v: V) {
def print() {
println(k + "," + v)
}
}
object GenericClass {
def main(args: Arr
- 素数与音乐
bookjovi
素数数学haskell
由于一直在看haskell,不可避免的接触到了很多数学知识,其中数论最多,如素数,斐波那契数列等,很多在学生时代无法理解的数学现在似乎也能领悟到那么一点。
闲暇之余,从图书馆找了<<The music of primes>>和<<世界数学通史>>读了几遍。其中素数的音乐这本书与软件界熟知的&l
- Java-Collections Framework学习与总结-IdentityHashMap
BrokenDreams
Collections
这篇总结一下java.util.IdentityHashMap。从类名上可以猜到,这个类本质应该还是一个散列表,只是前面有Identity修饰,是一种特殊的HashMap。
简单的说,IdentityHashMap和HashM
- 读《研磨设计模式》-代码笔记-享元模式-Flyweight
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java
- PS人像润饰&调色教程集锦
cherishLC
PS
1、仿制图章沿轮廓润饰——柔化图像,凸显轮廓
http://www.howzhi.com/course/retouching/
新建一个透明图层,使用仿制图章不断Alt+鼠标左键选点,设置透明度为21%,大小为修饰区域的1/3左右(比如胳膊宽度的1/3),再沿纹理方向(比如胳膊方向)进行修饰。
所有修饰完成后,对该润饰图层添加噪声,噪声大小应该和
- 更新多个字段的UPDATE语句
crabdave
update
更新多个字段的UPDATE语句
update tableA a
set (a.v1, a.v2, a.v3, a.v4) = --使用括号确定更新的字段范围
- hive实例讲解实现in和not in子句
daizj
hivenot inin
本文转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842855.html
当前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现。
假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注册用户,字段只有一个uid),这两个表都包含
- 一道24点的10+种非人类解法(2,3,10,10)
dsjt
算法
这是人类算24点的方法?!!!
事件缘由:今天晚上突然看到一条24点状态,当时惊为天人,这NM叫人啊?以下是那条状态
朱明西 : 24点,算2 3 10 10,我LX炮狗等面对四张牌痛不欲生,结果跑跑同学扫了一眼说,算出来了,2的10次方减10的3次方。。我草这是人类的算24点啊。。
然后么。。。我就在深夜很得瑟的问室友求室友算
刚出完题,文哥的暴走之旅开始了
5秒后
- 关于YII的菜单插件 CMenu和面包末breadcrumbs路径管理插件的一些使用问题
dcj3sjt126com
yiiframework
在使用 YIi的路径管理工具时,发现了一个问题。 <?php
- 对象与关系之间的矛盾:“阻抗失配”效应[转]
come_for_dream
对象
概述
“阻抗失配”这一词组通常用来描述面向对象应用向传统的关系数据库(RDBMS)存放数据时所遇到的数据表述不一致问题。C++程序员已经被这个问题困扰了好多年,而现在的Java程序员和其它面向对象开发人员也对这个问题深感头痛。
“阻抗失配”产生的原因是因为对象模型与关系模型之间缺乏固有的亲合力。“阻抗失配”所带来的问题包括:类的层次关系必须绑定为关系模式(将对象
- 学习编程那点事
gcq511120594
编程互联网
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- Reverse Linked List II
hcx2013
list
Reverse a linked list from position m to n. Do it in-place and in one-pass.
For example:Given 1->2->3->4->5->NULL, m = 2 and n = 4,
return
- Spring4.1新特性——页面自动化测试框架Spring MVC Test HtmlUnit简介
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Hadoop集群工具distcp
liyonghui160com
1. 环境描述
两个集群:rock 和 stone
rock无kerberos权限认证,stone有要求认证。
1. 从rock复制到stone,采用hdfs
Hadoop distcp -i hdfs://rock-nn:8020/user/cxz/input hdfs://stone-nn:8020/user/cxz/运行在rock端,即源端问题:报版本
- 一个备份MySQL数据库的简单Shell脚本
pda158
mysql脚本
主脚本(用于备份mysql数据库): 该Shell脚本可以自动备份
数据库。只要复制粘贴本脚本到文本编辑器中,输入数据库用户名、密码以及数据库名即可。我备份数据库使用的是mysqlump 命令。后面会对每行脚本命令进行说明。
1. 分别建立目录“backup”和“oldbackup” #mkdir /backup #mkdir /oldbackup
- 300个涵盖IT各方面的免费资源(中)——设计与编码篇
shoothao
IT资源图标库图片库色彩板字体
A. 免费的设计资源
Freebbble:来自于Dribbble的免费的高质量作品。
Dribbble:Dribbble上“免费”的搜索结果——这是巨大的宝藏。
Graphic Burger:每个像素点都做得很细的绝佳的设计资源。
Pixel Buddha:免费和优质资源的专业社区。
Premium Pixels:为那些有创意的人提供免费的素材。
- thrift总结 - 跨语言服务开发
uule
thrift
官网
官网JAVA例子
thrift入门介绍
IBM-Apache Thrift - 可伸缩的跨语言服务开发框架
Thrift入门及Java实例演示
thrift的使用介绍
RPC
POM:
<dependency>
<groupId>org.apache.thrift</groupId>