hive面试之【自连接,行转列,列转行】
hive面试之【自连接,行转列,列转行】
1.hive自连接
现有这么一批数据,现要求出:
每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数
三个字段的意思:
用户名,月份,访问次数
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,11
最后结果展示:
用户 月份 最大访问次数 总访问次数 当月访问次数
A 2015-01 33 33 33
A 2015-02 33 43 10
A 2015-03 38 81 38
B 2015-01 30 30 30
B 2015-02 30 45 15
B 2015-03 44 89 44
根据答案总结出来的规律:
1、按照用户分组
2、按照月份排序
3、求max和sum(在以上两点的基础之上)
准备数据和表:
create database exercise;
use exercise;
drop table if exists visit;
create table visit(username string, month string, visit int) row format delimited fields terminated by ",";
load data local inpath "/home/hadoop/visit.txt" into table visit;
select * from visit;
思路:
1、从数据当中发现数据规律:
每个用户在每月的访问记录有多条
解决方法:先求每个用户在每个月份里面的总访问次数
// 第一个HQL语句:
create table visit_month as select username, month , sum(visit) visit from visit group by username, month order by username, month;
用户 月份 当月访问次数
A 2015-01 33
A 2015-02 10
A 2015-03 38
B 2015-01 30
B 2015-02 15
B 2015-03 44
2、求出截止到每月时的单月最大访问次数 和总访问次数
A 2015-01 33 ====> A 2015-01 33 33 33
A 2015-01 33
A 2015-02 10 =====> A 2015-02 10 33 43
......
最终的数据结果:
A 2015-01 (33)
A 2015-02 (33,10)
A 2015-03 (33,10, 43)
B 2015-01 (33)
B 2015-02 (33,10)
B 2015-03 (33,10, 43)
转换数据形式:
A 2015-01 33 2015-01
A 2015-02 33 2015-01
A 2015-02 10 2015-02
a.username a.month b.visit b.month
A 2015-03 | 33 2015-01
A 2015-03 | 10 2015-02
A 2015-03 | 43 2015-03
a.username a.month a.visit b.visit b.month b.username
A 2015-01 33 33 2015-01 A
A 2015-01 33 10 2015-02 A XXX
A 2015-01 33 43 2015-03 A xxx
A 2015-02 10 33 2015-01 A
A 2015-02 10 10 2015-02 A
A 2015-02 10 43 2015-03 A xxx
A 2015-03 43 33 2015-01 A
A 2015-03 43 10 2015-02 A
A 2015-03 43 43 2015-03 A
正常数据;
A 2015-01 33
A 2015-02 10
A 2015-03 43
select username, month, sum(visit) totalVisit, max(visit) maxVisit from visit_month;
使用自连接的方式就能造出能够分组,能够求聚合的字段列:
// 第二个 HQL 语句,, 创建一个view
create view visit_join as select a.username aname, a.month amonth, a.visit avisit,
b.username bname, b.month bmonth, b.visit bvisit from visit_month a
join visit_month b on a.username = b.username;
结果:该view当中 总共有 18 条记录 3*3 + 3*3
// 第三个 qhl语句,, 最终的sql语句:
create table lastvisit as select aname, amonth, avisit, sum(bvisit) as totalvisit, max(bvisit) as maxvisit from visit_join where amonth >= bmonth group by aname, amonth, avisit;
A 2015-01 33 33 33
A 2015-02 10 43 33
A 2015-03 38 81 38
B 2015-01 30 30 30
B 2015-02 15 45 30
B 2015-03 44 89 44
sum(yuwen) max() 聚合操作 : 把多行当中的相同的列的值做聚合操作
sum(yingyu, shuxue, yuwen) = 把一行当中的多列的值 做累加2.hive行转列
explode使用场景:
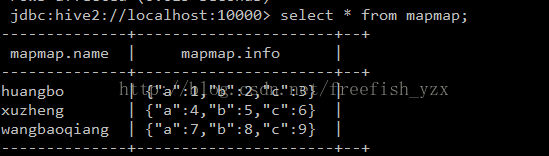
huangbo
a,1:b,2:c,3
xuzheng a,4:b,5:c,6
wangbaoqiang a,7:b,8:c,9
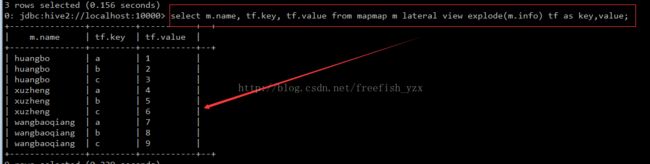
huangbo a 1
huangbo b 2
huangbo c 3
xuzhegn a 4
xuzheng b 5
xuzheng a,4:b,5:c,6
wangbaoqiang a,7:b,8:c,9
huangbo a 1
huangbo b 2
huangbo c 3
xuzhegn a 4
xuzheng b 5
.
.
.
create table mapmap(name string, info map) row format delimited fields terminated by "\t" collection items terminated by ":" map keys terminated by ",";
load data local inpath "/home/hadoop/mapmap.txt" into table mapmap;
select * from mapmap;
select m.name, tf.key, tf.value from mapmap m lateral view explode(m.info) tf as key,value;
3.hive列转行
// 建表语句:
CREATE TABLE `course` (
`id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`sid` int(11) DEFAULT NULL,
`course` varchar(255) DEFAULT NULL,
`score` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
// 插入数据
// 字段解释:id, 学号, 课程, 成绩
INSERT INTO `course` VALUES (1, 1, 'yuwen', 43);
INSERT INTO `course` VALUES (2, 1, 'shuxue', 55);
INSERT INTO `course` VALUES (3, 2, 'yuwen', 77);
INSERT INTO `course` VALUES (4, 2, 'shuxue', 88);
INSERT INTO `course` VALUES (5, 3, 'yuwen', 98);
INSERT INTO `course` VALUES (6, 3, 'shuxue', 65);
求:所有数学课程成绩 大于 语文课程成绩的学生的学号
// 数据表当中的数据结构:
id course score
1 yuwen 43
1 shuxue 55
2 yuwen 77
2 shuxue 88
3 yuwen 98
3 shuxue 65
select id, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course;
难点: 没法让 55 和 43 做比较。 如果要做比较只能让 55 和 43 在同一行
id shuxue yuwen
1 55 43
2 88 77
3 98 65
1 0 43
1 55 0
select id from course where shuxue > yuwen;
把原来的数据表当中的数据结构做一次行列转换:
1、怎么转?
行列转换的方式有很多种
使用case 。。。。 when 。。。。。 的语法解决行列转换
select sid, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course;
select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from (select sid, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course) aa group by sid;
select bb.sid from (select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from (select sid, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course) aa group by sid) bb where shuxue > yuwen;