文本分类之深度学习应用总结
总览
本教程分为五个部分,分别是:
- 词嵌入(Word Embeddings) + 卷积神经网络(CNN,Convolutional Neural Network) = 文本分类
- 使用一个单层 CNN 架构
- 调整 CNN 超参数
- 考虑字符级的 CNN
- 考虑用更深层的 CNN 进行分类
1.词嵌入 + CNN = 文本分类
文本分类的操作方法包括:使用词嵌入来表示单词,使用卷积神经网络(CNN)来学习如何辨别分类问题中的文本。
在 Yoav Goldberg 的关于自然语言处理的深度学习的入门书中,他评论道,神经网络通常比传统的线性分类器具有更好的性能,特别是将其与预训练过的词嵌入结合使用时。
网络的非线性,及其易集成预先训练的词嵌入的能力,使得它通常具有更高的分类准确性。
- 引用自 2015 年发表的 A Primer on Neural Network Models for Natural Language Processing(自然语言处理的神经网络模型入门指导)。
他还评论道,卷积神经网络对于文本分类有效的,这是因为它们能够在不改变输入序列的位置的情况下提取出显著的特征(例如词 [译者注:Token,在自然语言处理中,它表示对句子分词后得到的单个词] 或词序列)。
具有卷积层和池化(Pooling)层的网络对于分类任务非常有用,我们希望在分类任务中找到关于类成员的强力局部线索,但这些线索可以在输入数据中的不同位置出现。[...] 我们想知道,哪些字词序列是关于该话题的很好的指标,但并不一定会关心它们在文本中出现的位置。卷积层和池化层使得模型可以学习到找到这种局部指标的能力,同时忽略它们所在的位置。
- 引用自 2015 年发表的 A Primer on Neural Network Models for Natural Language Processing(自然语言处理的神经网络模型入门指导)。
因此,该架构由三个关键部分组成:
- 词嵌入(Word Embedding):词的分布式表示,其中具有相似含义的不同词(基于其用法)具有相似的表示。
- 卷积模型(Convolutional Model):一种特征提取模型,这种模型可学习从使用词嵌入表示的文本中提取显着特征。
- 全连接模型(Fully Connected Model):从需要预测的输出的角度来解释提取到的特征。
Yoav Goldberg 在他的书中强调了 CNN 作为一个特征提取模型的作用:
CNN 本质上是一个特征提取架构。它本身并不构成一个独立且有用的网络,而它会被整合到一个更大的网络中,并接受训练与之协同工作,以产生最终结果。CNN 层的责任是提取对于当前整体预测任务有用的有意义的子结构。
- 引用自 2017 年出版的 Neural Network Methods for Natural Language Processing(自然语言处理中的神经网络方法),第 152 页。
以上三个要素的结合,可能是最受广泛引用的组合实例之一,我们在下一节中会对其进行描述。
2.使用一个单层 CNN 架构
您可以通过使用一个单层 CNN 来获得对于文档分类的良好结果,或者在过滤器(Filter)中使用不同大小的卷积核(Kernel),从而能在不同的规模上对词表示进行分组。
Yoon Kim 在研究对卷积神经网络使用预训练(Pre-trained)词向量进行分类任务时,发现用预训练的静态词向量的确能得到很好的结果。他建议对于庞大的文本语料库,可以预先训练出词嵌入(例如在 Google 新闻中的 1000 亿个词上训练得到的 word2vec 向量), 如此可以获得在自然语言处理中良好且通用的特征。
尽管对超参数进行了微调,但具有单个卷积层的简单 CNN 表现依旧非常好。我们所得的结果成为了一个有力的证明:即无监督的词向量预训练是 NLP 深度学习的一个重要组成部分。
- 引用自 2014 年发表的 Convolutional Neural Networks for Sentence Classification(用于语句分类的卷积神经网络)。
他还发现,对特定任务进一步地调整词向量,可以在性能方面提供一些额外的改进。
Kim 介绍了将 CNN 用于自然语言处理的一般方法。我们将句子映射到嵌入向量,并以矩阵的形式输入到模型中。再适当地使用不同大小的卷积核(例如一次 2 或 3 个词)对所有输入的词执行卷积操作。最后使用最大池化层处理得到的特征映射,将提取到的特征进行浓缩或汇总。
该架构基于 Ronan Collobert 等人使用的方法。这个方法是他们在 2011 年发表的论文 “Natural Language Processing (almost) from Scratch(从零开始自然语言处理)” 中提出的。他们开发了一个单一的端到端神经网络模型,这一模型具有卷积层和池化层,并可以用于解决一系列基本的自然语言处理问题。
Kim 提供了一个示意图,以帮助您直观地看到使用不同大小的卷积核(以红色和黄色区分)时的过滤器采样过程。
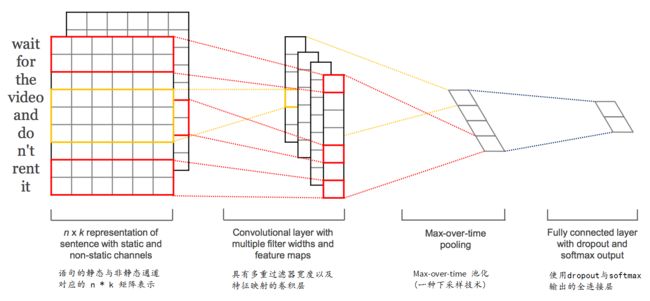 自然语言处理的 CNN 过滤器和池化架构的一个例子
自然语言处理的 CNN 过滤器和池化架构的一个例子
上图摘自 2014 年发表的 “Convolutional Neural Networks for Sentence Classification(用于语句分类的卷积神经网络)”。
有用的是,他公布了自己的模型参数与配置,这些参数是通过网格搜索找到的,并用于进行 7 个文本分类任务,现总结如下:
- 传递函数 :线性整流
- 卷积核大小:2, 4, 5
- 过滤器数量:100
- 丢弃率(Dropout rate):0.5
- 正则化权重(L2):3
- 批大小:50
- 更新规则:Adadelta
对于你自己的实验来说,这些配置可以用于激发你的灵感,使你找到一个合适的起点。
3.调整 CNN 超参数
在调整你用于文本分类问题的卷积神经网络时,有一些超参数比其他超参数更重要。
Ye Zhang 和 Byron Wallace 对使用单层卷积神经网络进行文本分类所需要的超参数进行了灵敏度分析。他们声称这些模型对其配置很敏感,这便是他们进行此研究的动机。
不幸的是,基于 CNN 的模型(甚至一个简单模型)有一个缺点,就是它们要求从业者指定要使用的确切的模型架构,并设置模型所需要的超参数。对于外行人来说,做出这样的决定就如同魔法一般,因为模型中有许多的自由参数。
- 引用自 2015 年发表的 A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification(卷积神经网络用于语句分类时的敏感性分析[以及从业者指南])。
他们的目标是提供可用于在新的文本分类任务上进行配置 CNN 的通用配置。
他们提供了关于模型架构以及模型配置的决策点的很好的描述,下面将其转载过来。
 用于语句分类的卷积神经网络架构
用于语句分类的卷积神经网络架构
图片源自 2015 年发表的 “A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification”。
这项研究提出了许多有用的发现,这些发现可以作为配置浅层 CNN 模型进行文本分类的出发点。
相关的发现综述如下:
- 对于不同的问题来说,对预训练的 word2vec 和 GloVe 嵌入的选择是不同的,并且它们都比使用一位有效编码(One-hot encoded)的词向量表现更好。
- 卷积核的大小很重要,我们应该针对不同问题对其进行相应调整。
- 特征映射的数量也很重要,也应该进行相应调整。
- 1-max 池化通常比其他类型的池化技术表现得要好。
- Dropout 对模型的性能影响不大。
他们接着提供了更具体的一些探索,如下:
- 使用 word2vec 或 GloVe 词嵌入作为出发点,并在拟合模型时对它们进行调整。
- 在不同的卷积核大小上进行网格搜索,从而找到关于该问题的最佳配置,其范围在 1-10 之间。
- 在 100-600 的区间中搜索过滤器的数量,并对作为搜索的一部分的 dropout 在 0.0-0.5 区间内进行了探索。
- 探索了几种激活函数:tanh,ReLU(Rectified Linear Units,线性整流单元) 以及线性激活函数。
关键需要注意的是,该研究结果是基于二元文本分类问题的经验结果,并且这个分类问题是以单句作为输入的。
要了解更多的细节,我建议阅读完整的论文:
- A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification,2015.
4.考虑字符级的 CNN
我们可以使用能够学习单词,句子,段落等相关的分层结构的卷积神经网络,在字符级别(Character level)上对文本文档进行建模。
Xiang Zhang 等人使用一个基于字符的文本表示作为卷积神经网络的输入。这种方法可以保证,如果 CNN 能够学习抽象出显着的细节,那么所有需要清理文本和准备文本劳动密集型(Labor-intensive)工作就可以被克服。
......深层次的卷积网络不需要关于词汇的知识,除此之外,在以前的研究结论中我们知道,卷积网络也不需要关于语言的句法或语义结构的知识。在工程上,这种简化方式对于可以用于不同语言的单个系统是至关重要的,因为无论是否能分割成为单词,字符都是一个必要的组成结构。仅对字符进行处理还具一些优点,它可以自然地学习诸如拼写错误和表情符号之类的不规则字符组合。
- 引用自 2015 年发表的 Character-level Convolutional Networks for Text Classification(用于文本分类的字符级卷积网络)。
该模型根据固定大小的字母表读取一位有效编码字符。编码字符以 1024 个字符为一块或一个序列,以进行读取。为作出预测,我们在网络的输出端连接了 3 个全连接层以及 6 个卷积层(以及池化层)的堆叠。
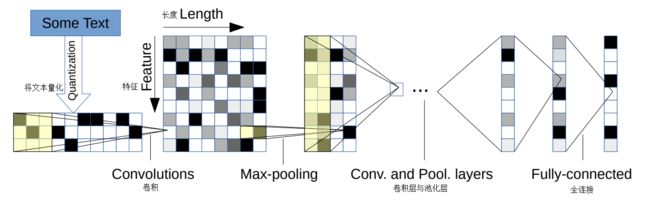 用于文本分类的基于字符的卷积神经网络
用于文本分类的基于字符的卷积神经网络
摘自 2015 年,“Character-level Convolutional Networks for Text Classification”。
该模型取得了一些成功,它在提供了更大的文本语料库的问题上表现得更好。
...分析表明,字符级的卷积网络是一个有效的方法。[...] 我们的模型如何很好地进行比较,这取决于许多因素,比如数据集的大小,文本是否是组织化的,以及对字母表的选择。
- 引用自 2015 年发表的 Character-level Convolutional Networks for Text Classification(用于文本分类的字符级卷积网络)。
在下一节中,我们将看到一篇后续的论文,该论文中使用了上述方法的一个扩展版本并得到了一个更高水准的结果。
5.考虑用更深的 CNN 进行分类
尽管标准及可重用架构尚未适用于分类任务,但我们可以使用非常深的卷积神经网络来实现更高的性能。
Alexis Conneau 等人对用于自然语言处理的相对较浅层的网络,以及用于计算机视觉应用的更深层网络的成功进行了评论。例如,Kim(如上图所述)将模型限制在单一的卷积层上。
本文所述的其他用于自然语言的架构大多仅限于 5 层和 6 层。这与计算机视觉中使用的成功的架构形成鲜明对比,它们具有 19 层,甚至能达到 152 层。
他们提出并证明了,用非常深度的卷积神经网络模型(称为 VDCNN)进行分层特征学习是有好处的。
... 我们建议,使用多达 29 层的多卷积层的深层架构来实现这个目标。我们这一架构的设计灵感源自计算机视觉领域的最新进展 [...] 我们所提出的深层卷积网络表现出比其以往的卷积网络方法有显著提升的结果。
他们所提出的方法的关键,是嵌入单个字符,而非一个词嵌入。
我们提出了一个用于文本处理的新架构(VDCNN),它直接在字符级运作,并且只使用小的卷积和池化操作。
- 引用自 2016 年发表的 Very Deep Convolutional Networks for Text Classification(用于文本分类的极深卷积网络)。
通过对一组 8 个大型文本分类任务的结果进行比较,更深层的网络比起大多较浅的网络显示出了更好的性能。具体而言,在撰写论文时,除了两个测试数据集外,其他所有数据集都获得了最先进的结果。
一般来说,他们通过探索更深层次的架构方法而得到了一些重要发现:
- 非常深的架构在小型和大型数据集上都能有不错的结果。
- 更深层网络的分类错误降低了。
- Max-pooling 可以比其他更复杂的池化类型获得更好的结果。
- 一般情况下,精度会随着深度增加而降低。在架构中使用的快捷连接非常重要。
... 这是第一次在 NLP 中展示卷积神经网络的“深度优势”。
- 引用自 2016 年发表的 Very Deep Convolutional Networks for Text Classification(用于文本分类的极深卷积网络)。
进一步阅读
如果你想更深入地研究,本节提供了更多的相关资料:
- 2015 年,A Primer on Neural Network Models for Natural Language Processing(自然语言处理的神经网络模型入门教程)
- 2014 年,Convolutional Neural Networks for Sentence Classification(用于语句分类的卷积神经网络)
- 2011 年,Natural Language Processing (almost) from Scratch(从零开始自然语言处理)
- 2016 年,Very Deep Convolutional Networks for Text Classification(用于文本分类的极深卷积网络)
- 2015 年,Character-level Convolutional Networks for Text Classification(用于文本分类的字符级卷积网络)
- 2015 年,A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification(卷积神经网络用于语句分类时的敏感性分析[以及从业者指南])
总结
在这篇文章中,您了解到了关于开发文本分类的深度学习模型的一些最佳实践。
具体来说,你学到了:
- 一个关键的方法,是使用词嵌入和卷积神经网络来进行文本分类。
- 单层模型在中等大小的问题上表现是出色的,以及关于如何对其进行配置的一些思路。
- 直接对文本进行操作的更深层的模型可能会是自然语言处理未来的发展方向。