机器学习算法实现解析——word2vec源码解析
在阅读本文之前,建议首先阅读“简单易学的机器学习算法——word2vec的算法原理”(目前还没发布),掌握如下的几个概念:
- 什么是统计语言模型
- 神经概率语言模型的网络结构
- CBOW模型和Skip-gram模型的网络结构
- Hierarchical Softmax和Negative Sampling的训练方法
- Hierarchical Softmax与Huffman树的关系
有了如上的一些概念,接下来就可以去读word2vec的源码。在源码的解析过程中,对于基础知识部分只会做简单的介绍,而不会做太多的推导,原理部分会给出相应的参考地址。
在wrod2vec工具中,有如下的几个比较重要的概念:
- CBOW
- Skip-Gram
- Hierarchical Softmax
- Negative Sampling
其中CBOW和Skip-Gram是word2vec工具中使用到的两种不同的语言模型,而Hierarchical Softmax和Negative Sampling是对以上的两种模型的具体的优化方法。
在word2vec工具中,主要的工作包括:
- 预处理。即变量的声明,全局变量的定义等;
- 构建词库。即包含文本的处理,以及是否需要有指定词库等;
- 初始化网络结构。即包含CBOW模型和Skip-Gram模型的参数初始化,Huffman编码的生成等;
- 多线程模型训练。即利用Hierarchical Softmax或者Negative Sampling方法对网络中的参数进行求解;
- 最终结果的处理。即是否保存和以何种形式保存。
对于以上的过程,可以由下图表示:
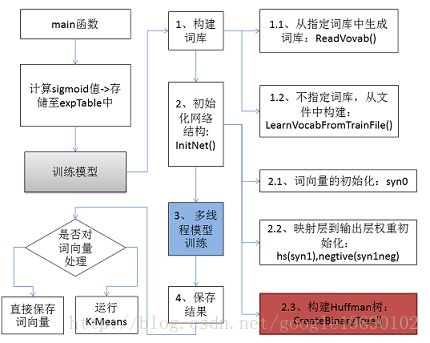
在接下来的内容中,将针对以上的五个部分,详细分析下在源代码中的实现技巧,以及简单介绍我在读代码的过程中对部分代码的一些思考。
1、预处理
在预处理部分,对word2vec需要使用的参数进行初始化,在word2vec中是利用传入的方式对参数进行初始化的。
在预处理部分,实现了sigmoid函数值的近似计算。在利用神经网络模型对样本进行预测的过程中,需要对其进行预测,此时,需要使用到sigmoid函数,sigmoid函数的具体形式为:
如果每一次都请求计算sigmoid值,对性能将会有一定的影响,当sigmoid的值对精度的要求并不是非常严格时,可以采用近似计算。在word2vec中,将区间 [−6,6] (设置的参数MAX_EXP为6)等距离划分成EXP_TABLE_SIZE等份,并将每个区间中的sigmoid值计算好存入到数组expTable中,需要使用时,直接从数组中查找。计算sigmoid值的代码如下所示:
expTable = (real *)malloc((EXP_TABLE_SIZE + 1) * sizeof(real));// 申请EXP_TABLE_SIZE+1个空间
// 计算sigmoid值
for (i = 0; i < EXP_TABLE_SIZE; i++) {
expTable[i] = exp((i / (real)EXP_TABLE_SIZE * 2 - 1) * MAX_EXP); // Precompute the exp() table
expTable[i] = expTable[i] / (expTable[i] + 1); // Precompute f(x) = x / (x + 1)
}注意:在上述代码中,作者使用的是小于EXP_TABLE_SIZE,实际的区间是 [−6,6) 。
2、构建词库
在word2vec源码中,提供了两种构建词库的方法,分别为:
- 指定词库:ReadVocab()方法
- 从词的文本构建词库:LearnVocabFromTrainFile()方法
2.1、构建词库的过程
在这里,我们以从词的文本构建词库为例。构建词库的过程如下所示:
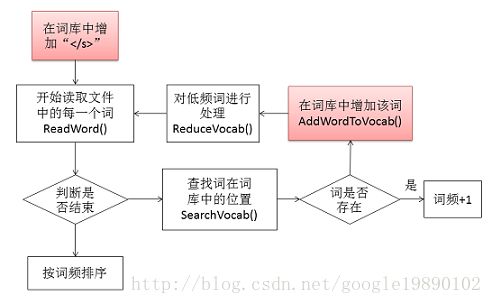
在这部分中,最主要的工作是对文本进行处理,包括低频词的处理,hash表的处理等等。首先,会在词库中增加一个“< /s>”的词,同时,在读取文本的过程中,将换行符“\n”也表示成该该词,如:
if (ch == '\n') {
strcpy(word, (char *)"");// 换行符用表示
return;在循环的过程中,不断去读取文件中的每一个词,并在词库中进行查找,若存在该词,则该词的词频+1,否则,在词库中增加该词。在词库中,是通过哈希表的形式存储的。最终,会过滤掉一些低频词。
在得到最终的词库之前,还需根据词库中的词频对词库中的词进行排序。
2.2、对词的哈希处理
在存储词的过程中,同时保留这两个数组:
- 存储词的vocab
- 存储词的hash的vocab_hash
其中,在vocab中,存储的是词对应的结构体:
// 词的结构体
struct vocab_word {
long long cn; // 出现的次数
int *point; // 从根结点到叶子节点的路径
char *word, *code, codelen;// 分别对应着词,Huffman编码,编码长度
};在vocab_hash中存储的是词在词库中的Index。
在对词的处理过程中,主要包括:
- 计算词的hash值:
// 取词的hash值
int GetWordHash(char *word) {
unsigned long long a, hash = 0;
for (a = 0; a < strlen(word); a++) hash = hash * 257 + word[a];
hash = hash % vocab_hash_size;
return hash;
}- 检索词是否存在。如不存在则返回-1,否则,返回该词在词库中的索引:
while (1) {
if (vocab_hash[hash] == -1) return -1;// 不存在该词
if (!strcmp(word, vocab[vocab_hash[hash]].word)) return vocab_hash[hash];// 返回索引值
hash = (hash + 1) % vocab_hash_size;// 处理冲突
}
return -1;// 不存在该词在这个过程中,使用到了线性探测的开放定址法处理冲突,开放定址法就是一旦发生冲突,就去寻找下一个空的散列地址。
- 不存在,则插入新词。
在这个过程中,除了需要将词增加到词库中,好需要计算该词的hash值,并将vocab_hash数组中的值标记为索引。
2.3、对低频词的处理
在循环读取每一个词的过程中,当出现“vocab_size > vocab_hash_size * 0.7”时,需要对低频词进行处理。其中,vocab_size表示的是目前词库中词的个数,vocab_hash_size表示的是初始设定的hash表的大小。
在处理低频词的过程中,通过参数“min_reduce”来控制,若词出现的次数小于等于该值时,则从词库中删除该词。
在删除了低频词后,需要重新对词库中的词进行hash值的计算。
2.4、根据词频对词库中的词排序
基于以上的过程,程序已经将词从文件中提取出来,并存入到指定的词库中(vocab数组),接下来,需要根据每一个词的词频对词库中的词按照词频从大到小排序,其基本过程在函数SortVocab中,排序过程为:
qsort(&vocab[1], vocab_size - 1, sizeof(struct vocab_word), VocabCompare);保持字符“< \s>”在最开始的位置。排序后,根据“min_count”对低频词进行处理,与上述一样,再对剩下的词重新计算hash值。
至此,整个对词的处理过程就已经结束了。加下来,将是对网络结构的处理和词向量的训练。
3、初始化网络结构
有了以上的对词的处理,就已经处理好了所有的训练样本,此时,便可以开始网络结构的初始化和接下来的网络训练。网络的初始化的过程在InitNet()函数中完成。
3.1、初始化网络参数
在初始化的过程中,主要的参数包括词向量的初始化和映射层到输出层的权重的初始化,如下图所示:
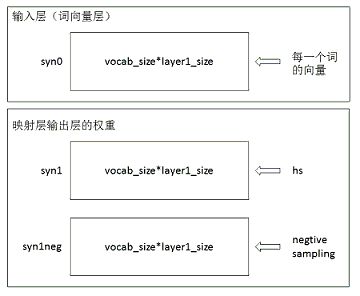
在初始化的过程中,映射层到输出层的权重都初始化为 0 ,而对于每一个词向量的初始化,作者的初始化方法如下代码所示:
for (a = 0; a < vocab_size; a++) for (b = 0; b < layer1_size; b++) {
next_random = next_random * (unsigned long long)25214903917 + 11;
// 1、与:相当于将数控制在一定范围内
// 2、0xFFFF:65536
// 3、/65536:[0,1]之间
syn0[a * layer1_size + b] = (((next_random & 0xFFFF) / (real)65536) - 0.5) / layer1_size;// 初始化词向量
}首先,生成一个很大的next_random的数,通过与“0xFFFF”进行与运算截断,再除以65536得到 [0,1] 之间的数,最终,得到的初始化的向量的范围为: [−0.5m,0.5m] ,其中, m 为词向量的长度。
3.2、Huffman树的构建
在层次Softmax中需要使用到Huffman树以及Huffman编码,因此,在网络结构的初始化过程中,也需要初始化Huffman树。在生成Huffman树的过程中,首先定义了 3 个长度为vocab_size*2+1的数组:
long long *count = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
long long *binary = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));
long long *parent_node = (long long *)calloc(vocab_size * 2 + 1, sizeof(long long));其中,count数组中前vocab_size存储的是每一个词的对应的词频,后面初始化的是很大的数,已知词库中的词是按照降序排列的,因此,构建Huffman树的过程如下所示(对于Huffman树的原理,可以参见博文“数据结构和算法——Huffman树和Huffman编码”):
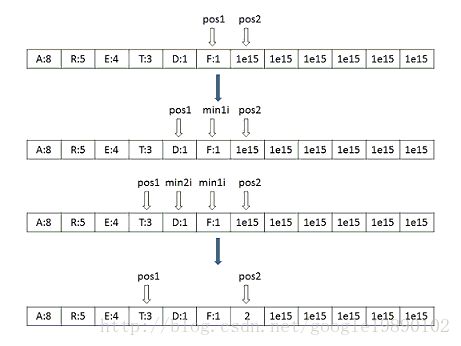
首先,设置两个指针pos1和pos2,分别指向最后一个词和最后一个词的后一位,从两个指针所指的数中选择出最小的值,记为min1i,如pos1所指的值最小,此时,将pos1左移,再比较pos1和pos2所指的数,选择出最小的值,记为min2i,将他们的和存储到pos2所指的位置。并将此时pos2所指的位置设置为min1i和min2i的父节点,同时,记min2i所指的位置的编码为1,如下代码所示:
// 设置父节点
parent_node[min1i] = vocab_size + a;
parent_node[min2i] = vocab_size + a;
binary[min2i] = 1;// 设置一个子树的编码为1构建好Huffman树后,此时,需要根据构建好的Huffman树生成对应节点的Huffman编码。假设,上述的数据生成的最终的Huffman树为:
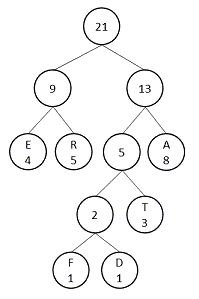
此时,count数组,binary数组和parent_node数组分别为:
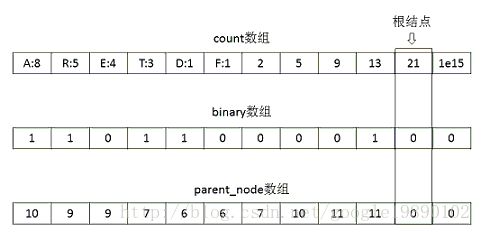
在生成Huffman编码的过程中,针对每一个词(词都在叶子节点上),从叶子节点开始,将编码存入到code数组中,如对于上图中的“R”节点来说,其code数组为{1,0},再对其反转便是Huffman编码:
vocab[a].codelen = i;// 词的编码长度
vocab[a].point[0] = vocab_size - 2;
for (b = 0; b < i; b++) {
vocab[a].code[i - b - 1] = code[b];// 编码的反转
vocab[a].point[i - b] = point[b] - vocab_size;// 记录的是从根结点到叶子节点的路径
}注意:这里的Huffman树的构建和Huffman编码的生成过程写得比较精简。
3.3、负样本选中表的初始化
如果是采用负采样的方法,此时还需要初始化每个词被选中的概率。在所有的词构成的词典中,每一个词出现的频率有高有低,我们希望,对于那些高频的词,被选中成为负样本的概率要大点,同时,对于那些出现频率比较低的词,我们希望其被选中成为负样本的频率低点。这个原理于“轮盘赌”的策略一致(详细可以参见“优化算法——遗传算法”)。在程序中,实现这部分功能的代码为:
// 生成负采样的概率表
void InitUnigramTable() {
int a, i;
double train_words_pow = 0;
double d1, power = 0.75;
table = (int *)malloc(table_size * sizeof(int));// int --> int
for (a = 0; a < vocab_size; a++) train_words_pow += pow(vocab[a].cn, power);
// 类似轮盘赌生成每个词的概率
i = 0;
d1 = pow(vocab[i].cn, power) / train_words_pow;
for (a = 0; a < table_size; a++) {
table[a] = i;
if (a / (double)table_size > d1) {
i++;
d1 += pow(vocab[i].cn, power) / train_words_pow;
}
if (i >= vocab_size) i = vocab_size - 1;
}
}在实现的过程中,没有直接使用每一个词的频率,而是使用了词的 0.75 次方。
4、多线程模型训练
以上的各个部分是为训练词向量做准备,即准备训练数据,构建训练模型。在上述的初始化完成后,接下来就是根据不同的方法对模型进行训练,在实现的过程中,作者使用了多线程的方法对其进行训练。
4.1、多线程的处理
为了能够对文本进行加速训练,在实现的过程中,作者使用了多线程的方法,并对每一个线程上分配指定大小的文件:
// 利用多线程对训练文件划分,每个线程训练一部分的数据
fseek(fi, file_size / (long long)num_threads * (long long)id, SEEK_SET);注意:这边的多线程分割方式并不能保证每一个线程分到的文件是互斥的。对于其中的原因,可以参见“Linux C 编程——多线程”。
这个过程可以通过下图简单的描述:

在实现多线程的过程中,作者并没有加锁的操作,而是对模型参数和词向量的修改可以任意执行,这一点类似于基于随机梯度的方法,训练的过程与训练样本的训练是没有关系的,这样可以大大加快对词向量的训练。抛开多线程的部分,在每一个线程内执行的是对模型和词向量的训练。
作者在实现的过程中,主要实现了两个模型,即CBOW模型和Skip-gram模型,在每个模型中,又分别使用到了两种不同的训练方法,即层次Softmax和Negative Sampling方法。
对于CBOW模型和Skip-gram模型的理解,首先必须知道统计语言模型(Statistic Language Model)。
在统计语言模型中的核心内容是:计算一组词语能够成为一个句子的概率。
为了能够求解其中的参数,一大批参数求解的方法被提出,在其中,就有word2vec中要使用的神经概率语言模型。具体的神经概率语言模型可以参见“”。
4.2、CBOW模型
CBOW模型和Skip-gram模型是神经概率语言模型的两种变形形式,其中,在CBOW模型中包含三层,即输入层,映射层和输出层。对于CBOW模型,如下图所示:
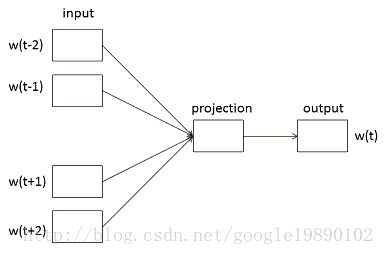
在CBOW模型中,通过词 wt 的前后词 wt−2 , wt−1 , wt+1 和 wt+2 来预测当前词 wt 。此处的窗口的大小window为2。
4.3.1、从输入层到映射层
首先找到每个词对应的词向量,并将这些词的词向量相加,程序代码如下所示:
// in -> hidden
// 输入层到映射层
cw = 0;
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;// sentence_position表示的是当前的位置
// 判断c是否越界
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];// 找到c对应的索引
if (last_word == -1) continue;
for (c = 0; c < layer1_size; c++) neu1[c] += syn0[c + last_word * layer1_size];// 累加
cw++;
}当累加完窗口内的所有的词向量的之后,存储在映射层neu1中,并取平均,程序代码如下所示:
for (c = 0; c < layer1_size; c++) neu1[c] /= cw;// 计算均值当取得了映射层的结果后,此时就需要使用Hierarchical Softmax或者Negative Sampling对模型进行训练。
4.3.2、Hierarchical Softmax
Hierarchical Softmax是word2vec中用于提高性能的一项关键的技术。由Hierarchical Softmax的原理可知,对于词w,其对数似然函数为:
其中, j 表示的词w对应的Huffman编码中的每一个编码的下标, dwj 表示的是第 j 个Huffman编码,且 dwj∈{0,1} ,这是一个求和的过程,因此,对于Huffman编码中的每一个编码,上述的对数似然函数为:
在此,变量为 Xw 和 θwj ,此时,分别对 Xw 和 θwj 求偏导数:
因此,对于 θwj 的更新公式为:
在word2vec源码中,为了能够加快计算,作者在开始的时候存储了一份Sigmoid的值,因此,对于 σ(XTwθwj) 需要从expTable中查询到对应的值。
for (d = 0; d < vocab[word].codelen; d++) {// word为当前词
// 计算输出层的输出
f = 0;
l2 = vocab[word].point[d] * layer1_size;// 找到第d个词对应的权重
// Propagate hidden -> output
for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];// 映射层到输出层
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];// Sigmoid结果
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];// 修改映射后的结果
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];// 修改映射层到输出层之间的权重
}对于窗口内的词的向量的更新,则是利用窗口内的所有词的梯度之和 ∑∂L(w,j)∂Xw 来更新,如程序代码所示:
// hidden -> in
// 以上是从映射层到输出层的修改,现在返回修改每一个词向量
for (a = b; a < window * 2 + 1 - b; a++) if (a != window) {
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
// 利用窗口内的所有词向量的梯度之和来更新
for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
}4.3.3、Negative Sampling
与Hierarchical Softmax一致,Negative Sampling也是一种加速计算的方法,在Negative Sampling方法中使用的是随机的负采样,在CBOW模型中,已知词 w 的上下文,需要预测词 w ,对于给定的上下文,词 w 即为正样本,其他的样本为负样本,此时我们需要根据词频从剩下的词中挑选出最合适的负样本,实现的代码如下所示:
// 标记target和label
if (d == 0) {// 正样本
target = word;
label = 1;
} else {// 选择出负样本
next_random = next_random * (unsigned long long)25214903917 + 11;
target = table[(next_random >> 16) % table_size];// 从table表中选择出负样本
// 重新选择
if (target == 0) target = next_random % (vocab_size - 1) + 1;
if (target == word) continue;
label = 0;
}当选择出了正负样本,此时的损失函数为:
其对数似然函数为:
即为:
取:
在此,变量为 Xw 和 θu ,此时,分别对 Xw 和 θwj 求偏导数:
因此,更新的代码为:
if (f > MAX_EXP) g = (label - 1) * alpha;
else if (f < -MAX_EXP) g = (label - 0) * alpha;
else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c];对词向量的更新与Hierarchical Softmax中一致。
4.3、Skip-gram模型
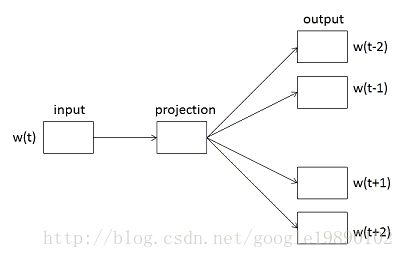
而Skip-gram模型与CBOW正好相反,在Skip-gram模型中,则是通过当前词 wt 来预测其前后词 wt−2 , wt−1 , wt+1 和 wt+2 ,Skip-gram模型如下图所示:
4.3.1、Hierarchical Softmax
由上述的分析,我们发现,在Skip-gram模型中,其计算方法与CBOW模型很相似,不同的是,在Skip-gram模型中,需要使用当前词分别预测窗口中的词,因此,这是一个循环的过程:
for (a = b; a < window * 2 + 1 - b; a++) if (a != window)对于向量的更新过程与CBOW模型中的Hierarchical Softmax一致:
c = sentence_position - window + a;
if (c < 0) continue;
if (c >= sentence_length) continue;
last_word = sen[c];
if (last_word == -1) continue;
l1 = last_word * layer1_size;
for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
// HIERARCHICAL SOFTMAX
if (hs) for (d = 0; d < vocab[word].codelen; d++) {
f = 0;
l2 = vocab[word].point[d] * layer1_size;
// Propagate hidden -> output
// 映射层即为输入层
for (c = 0; c < layer1_size; c++) f += syn0[c + l1] * syn1[c + l2];
if (f <= -MAX_EXP) continue;
else if (f >= MAX_EXP) continue;
else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
// 'g' is the gradient multiplied by the learning rate
g = (1 - vocab[word].code[d] - f) * alpha;
// Propagate errors output -> hidden
for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
// Learn weights hidden -> output
for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * syn0[c + l1];
}// Learn weights input -> hidden
for (c = 0; c < layer1_size; c++) syn0[c + l1] += neu1e[c];4.3.2、Negative Sampling
与上述一致,在Skip-gram中与CBOW中的唯一不同是在Skip-gram中是循环的过程。代码的实现类似与上面的Hierarchical Softmax。
注释版的word2vec源码已经上传到Github中:Github:word2vec.c
参考文献
- word2vec 中的数学原理详解(一)目录和前言
- word2vec 中的数学原理详解(二)预备知识
- word2vec 中的数学原理详解(三)背景知识
- word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型
- word2vec 中的数学原理详解(五)基于 Negative Sampling 的模型
- word2vec 中的数学原理详解(六)若干源码细节
- 深度学习与自然语言处理(1)_斯坦福cs224d Lecture 1
- Google Word2vec 学习手札
- Deep Learning in NLP (一)词向量和语言模型
- Neural Probabilistic Language Model, word2vec来龙去脉
- word2vec原理概述
- 自己动手写word2vec (一):主要概念和流程
- The amazing power of word vectors
- word2vec前世今生