Sqoop配置使用
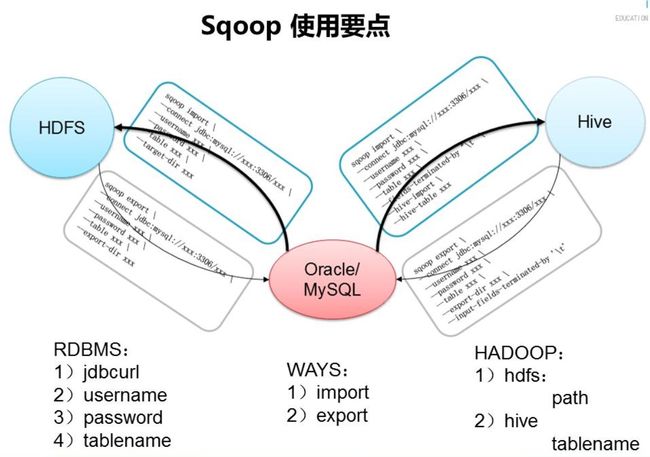
SQOOP:底层是Mapreduce,利用Mapreduce加快数据传输速度,批处理方式进行数据传输,并且只有Map Task任务。
Sqoop Client:命令行
Sqoop安装
- 安装
- 解压:tar -zxf sqoop-1.4.5-cdh5.3.6.tar.gz -C /opt/cdh-5.3.6/
sqoop-env-template.sh –》sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6 export HADOOP_MAPRED_HOME=/opt/cdh-5.3.6/hadoop-2.5.0-cdh5.3.6 export HIVE_HOME=/opt/cdh-5.3.6/hive-0.13.1-cdh5.3.6 export ZOOCFGDIR=/opt/cdh-5.3.6/zookeeper-3.4.5-cdh5.3.6/conf拷贝mysql驱动包到/opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/lib下:
cp /opt/software/mysql-connector-java-5.1.27-bin.jar /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/lib
Sqoop语句
显示所有数据库
bin/sqoop \
list-databases \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306 \
--username root \
--password 123456 查询metastore中所有表
bin/sqoop \
list-tables \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/metastore \
--username root \
--password 123456 导入
把mysql某张表中数据导入到Sqoop
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user– 注意:不走导入目录,会走默认配置,在HDFS上当前用户的主目录生成 /user/beifeng/my_user
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--num-mappers 1 \
--target-dir /user/beifeng/sqoop/inputbin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--num-mappers 1 \
--target-dir /user/beifeng/sqoop/input \
--delete-target-dir \
--direct– 注意,如果使用 –direct 选项的话,需要在所有的YARN的机器上,安装mysqldemp命令
– 实际场景:如何实现增量导入
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--num-mappers 1 \
--target-dir /user/beifeng/sqoop/input2 \
--fields-terminated-by "\t" \
--check-column id \
--incremental append \
--last-value 4– 功能:将my_user表中的数据,id从5开始导入到HDFS中:last-value 4
– 还有一种方式可以实现,并且比较简单:直接使用SQL语句
–query
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--num-mappers 1 \
--target-dir /user/beifeng/sqoop/input4 \
--fields-terminated-by "\t" \
--query 'select * from my_user where id >= 5 and $CONDITIONS'– =====================================================
导出
– EXPORT:
– 就是将HDFS上的数据导出到RDBMS中
– 其实HIVE表中的数据导出到RDBMS中,本质就是HDFS导出
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user2 \
--num-mappers 1 \
--export-dir /user/beifeng/sqoop/input3/part-m-00000 \
--input-fields-terminated-by "\t"– =====================================================
对于启动HiveServer2来说
服务端:
企业标准启动:$ bin/hiveserver2 >hiveserver.log 2>&1 &
有两个输出
1代表标准输出
2代表错误输出
2>&1
将错误输出信息重定向到标准输出
& :把进程放到后台运行
客户端:
bin/beeline -u jdbc:hive2://hadoop-senior01.ibeifeng.com:10000 -n beifeng -p beifeng– =====================================================
– HIVE DATABASE AND TABLE
DROP TABLE IF EXISTS default.h_user ;
CREATE TABLE default.h_user(
id int,
account string,
password string
)
row format delimited fields terminated by '\t' ;bin/sqoop import \
--connect jdbc:mysql://hadoop-senior01.ibeifeng.com:3306/test \
--username root \
--password 123456 \
--table my_user \
--num-mappers 1 \
--fields-terminated-by "\t" \
--hive-database default \
--hive-import \
--hive-table h_user \
--delete-target-dir– 注意:HIVE导入来说,分为两步走:
– 第一步、首先将RDBMS中表的数据导入到HDFS目录下
– 第二步、使用LOAD DATA将HDFS文件加载到HIVE表中
将Sqoop命令放到一个文件中去
bin/sqoop –options-file /opt/cdh-5.3.6/sqoop-1.4.5-cdh5.3.6/import-hdfs-my-user.sh
import-hdfs-my-user.sh中保存的是执行语句,可以与shell脚本联合执行