强化学习基础学习系列之求解MDP问题的value-base方法
- 介绍
- 动态规划
- 策略迭代
- 值迭代
- 收敛性
- MC-TD 估计
- MC
- TD
- 更新均值
- MC与TD的比较
- TDlamda
- MC-TD 控制
- 函数近似
介绍
在强化学习基础学习系列之MDP里提到了几个重要的点,对于任意一个MDP:(1)都存在一个确定性的最优策略;(2)在这个确定性的最优策略上得到的状态价值函数和动作价值函数都是最优的;(3)通过最优的动作价值函数反过来也可以最优的策略。
强化学习的算法可以根据求解最优策略的方法分为value-base的方法和policy-base的方法,value-base的方法就是指通过求解最优动作值函数来求解最优策略。policy-base的方法会在下篇博文里说到。此外,根据有无用到模型也可以将强化学习算法分为model-base的方法和model-free的方法。这篇博文和下篇博文里讲到的方法除了动态规划外都属于model-free的方法。还有就是planning和model-base的区别,我个人的理解是planning是值已经有了环境模型,然后使用模型去获得最优策略/值函数,而model-base既包含planning,也包含没有模型时去学习模型然后再使用model-free或planning的方法来得到最优策略/值函数。
描述完一些概念,我们回归正转。value-base的方法通过求解最优价值函数来得到最优策略,那么如何求得最优价值函数呢?
之前我们说过最优价值函数的定义是:

现在通过将Gt展开我们会发现:

去掉期望的符号,我们可以把他们写成:

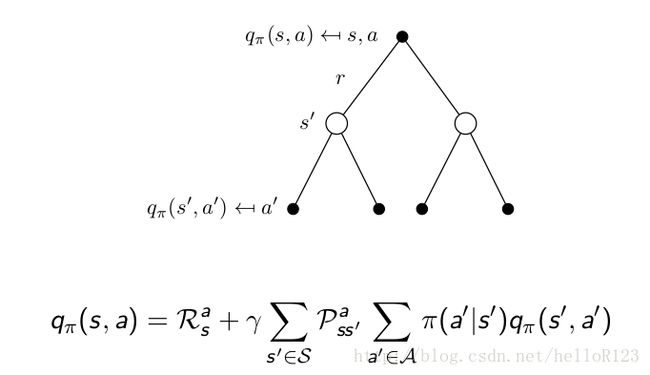
上图中像树一样的图叫备份图,公式叫做贝尔曼期望方程,弄清楚了代理和环境交互的过程就自然能够理解上面公式是如何写出来的。
同理,结合一开始说的那三个MDP的性质,我们也能够写出有关贝尔曼最优方程的等式:
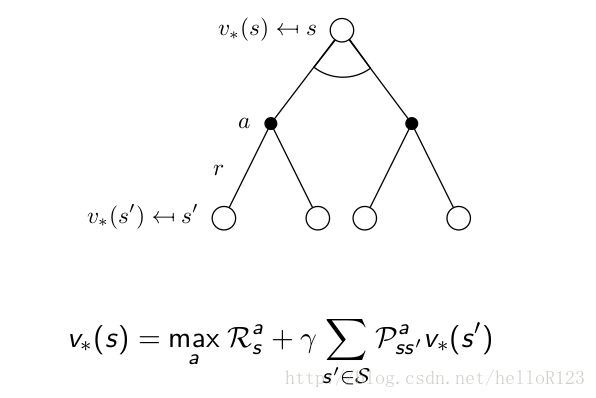
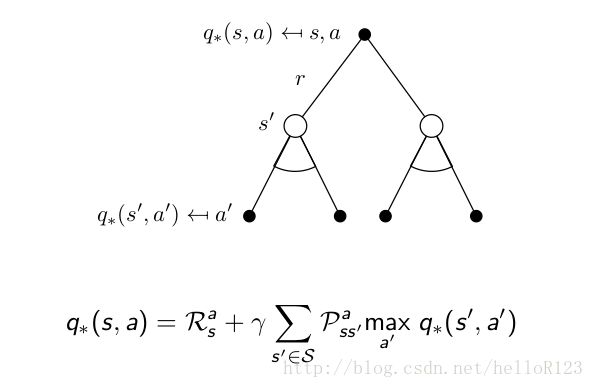
上面的等式关系叫做贝尔曼最优方程。从贝尔曼期望方程和贝尔曼最优方程我们可以看出在某一个状态的价值函数可以由其接下来的状态的价值函数得到。贝尔曼期望方程其实就是一个线性方程组,用求解线性方程组的方法(直接法,迭代法etc)都可以求出来,而贝尔曼最优方程其实是一个非线性方程组,用迭代法也能将其求出。当然它们一定会收敛,这个问题会在下面的动态规划章节提到。
此外要提到的一点,为了说明方法的思想,下面提到的方法(DP,MC,TD)都是针对状态是有限个/较少数量时说的,当状态是无限/非常多数量时就要考虑用到函数近似的方法了,最后一个小节会提到。
下面的方法介绍主要是为了说明想法,会比较简略,比较详细的内容可以看:https://zhuanlan.zhihu.com/c_101836530 。
动态规划
求解MDP的动态规划方法有两种,一是通过不断交替地进行价值函数估计和策略更新,最终得到最优的价值函数和最优的策略;另一种是直接去求解最优价值函数然后再求出最优策略。前者叫策略迭代,后者叫值迭代。
要注意的是,这里我们都假设已经知道了模型是如何的,也就是知道了P(s’,r|s,a)。
策略迭代
给定一个MDP和一个策略然后求其对应的值函数我们叫估计,而给定一个MDP然后求最优的策略我们叫做控制。
在强化学习基础学习系列之MDP提到了怎样去说明一个策略要比另一个策略好,也就是:

策略迭代的想法是先给定一个策略,然后求出它所对应的值函数,然后根据值函数去构造另一个比之前策略要好的策略,然后再求更新后的策略的值函数,然后再构造另一个更好的策略……如此反复直至收敛,我们用下图表示这个过程:
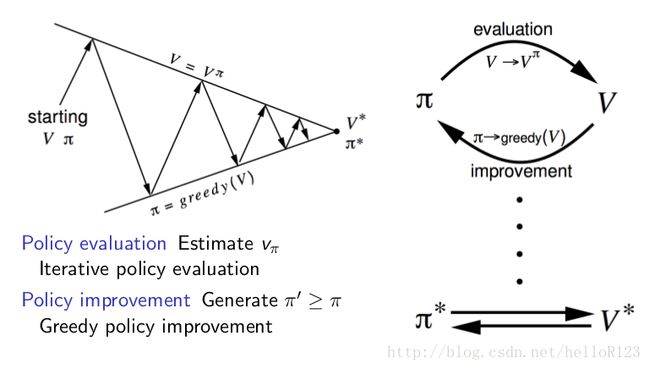
上图中的greedy操作就是构造更好的策略的过程,我们先不管它是怎么实现的,我们直观上理解下,如果我们能保证新构造的策略不比就策略差,那么策略迭代就能最终收敛到最优策略和最优值函数,因为新构造的策略一旦跟旧策略一样好时,贝尔曼最优方程就成立,这时也就意味着得到了最优值函数和最优策略。
现在来具体看两个里面的两个过程是怎样的,首先是值函数估计,这个很简单,根据上一节的讨论,,用求解线性方程组的方式求解贝尔曼期望方程便可;然后是如何得到更好的策略,这里的策略是:
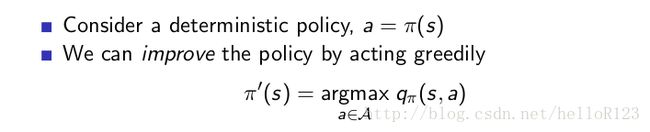
而通过下面的推理可以知道这样得到的策略是比原来的要好的:
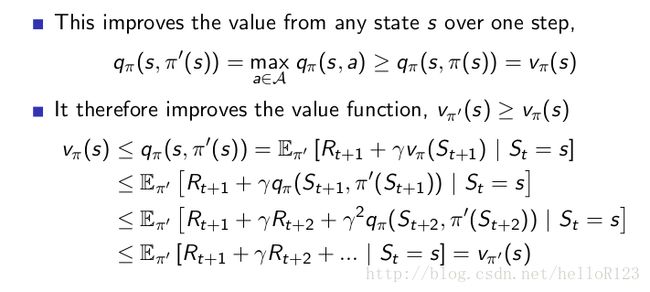
上图中只是对状态值函数的讨论,而动作价值函数其实也类似。
更重要的是,策略迭代的想法还有更泛化的形式,也就是广义策略迭代:

也就是在策略估计的过程中,我们不一定非得得到准确的值函数,大概有点像当前策略的值函数便可,而策略提升的过程也只需要保证能够得到一个更好的策略便可而不需要按原来的策略提升那样做(比如说只更新一个状态上的动作),理解了广义的策略迭代,后面蒙特卡罗方法和时间微分的一些算法也就好理解了。
值迭代
比起策略迭代,值迭代的方法则更直观:直接根据贝尔曼最优方程求解最优策略。用求解非线性方程组的迭代法便可求解贝尔曼最优方程。
另一种看待值迭代的方式是:它其实也是一种广义策略迭代的方法,在估计值函数时只对所有可能的状态更新一次,然后就进行更新策略。
收敛性
对于任意一个MDP,用迭代法去求解贝尔曼期望方程和求解贝尔曼最优方程都是可以收敛的,收敛性的证明来自下面的理论:



MC-TD 估计
动态规划里面要求知道了模型,也就是说它其实是planning/model-base的一种方法,但实际上很多应用我们都不知道P(s’,r|s,a),能不能即使没有model(也就是model-free),我们也可以学到最优策略呢?
蒙特卡罗方法(MC)和时间微分(TD)就是属于这一类方法,这一节先讨论如何用它们去估计,也就是知道了一个策略,如何求出该策略对应的值函数。
MC
MC的方法想法很简单,就是用样本均值去近似期望(想一下大数定理)。让代理去实际环境中执行策略获得一个episode{s1,a1,r2,s2,a2,r3…sT-1,aT-1,rT,sT}然后用这些样本去计算Gt来代替值函数也就是期望E[Gt]。值得注意的是MC的方法只适用于有结束状态的MDP问题,因为它必须要得到一个episode后才能计算出Gt。


TD
TD方法与MC方法一样,也是用样本的均值去代替期望,但不同的是,TD方法用的是Rt+r*V(st+1)去代替E[Rt+V(st+1)] (也就是E[Gt])。
更新均值
对于期望稳定的时候,我们用的是:
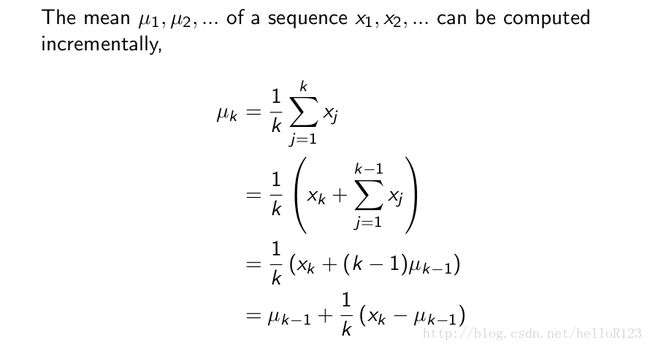
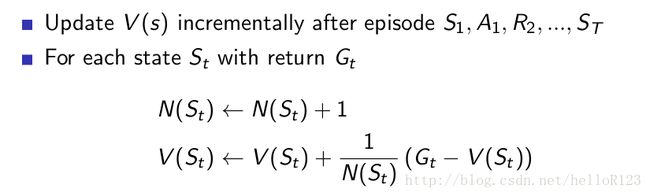
而期望不稳定时(在解决控制问题时会经常遇到),则用的是:

MC与TD的比较
MC的方法是无bias但高variance的,TD的方法是有bias但低variance的
MC方法适合于有结束状态的MDP,而TD方法则不管有无结束状态的MDP都适用
MC方法的收敛性更好,即使在用到函数近似时收敛性也能较好地维持,但收敛速度较慢;TD方法因为是有bias,所以收敛性没有那么好,在用到函数近似时会发散,但它的收敛速度要较快。
MC方法相当于是在做最小二乘法,而TD方法则是在做最大似然估计,所以MC方法对于马尔科夫条件不成立时也能适用,而TD方法则要求马尔科夫条件要成立。


TD(lamda)
既然可以用Rt+r*V(st+1)代替E[Gt],自然也可以用Rt+ r *Rt+1 +r^2 *V(st+2),Rt + r *Rt+1 + r^2 *Rt+2 + r^3 *V(st+3) ……去代替E[Gt],可以想象,到最后正好就是用Gt去代替E[Gt]。
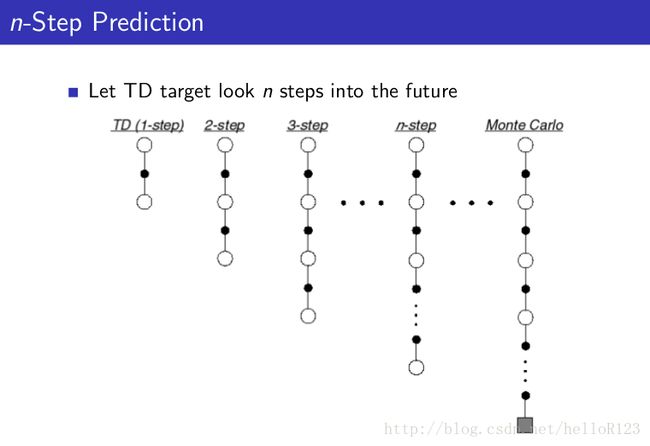

越趋于从TD(0)到MC,bias越来越小,variance越来越大,一种想法是,能不能把这些n-step return全部考虑起来找到一个bias不那么大同时variance也比较适中的方法,这就是TD (lamda)。


TD(0)就是1-step return的TD,而TD(1) 就是MC。
但在实际实现时,不可能按照其定义去实现,因为这样子做有很大的计算复杂度。TD(lamda)的定义我们把它叫TD(lamda)的前向视角,而实现TD(lamda)则是通过其后向视角来实现的:
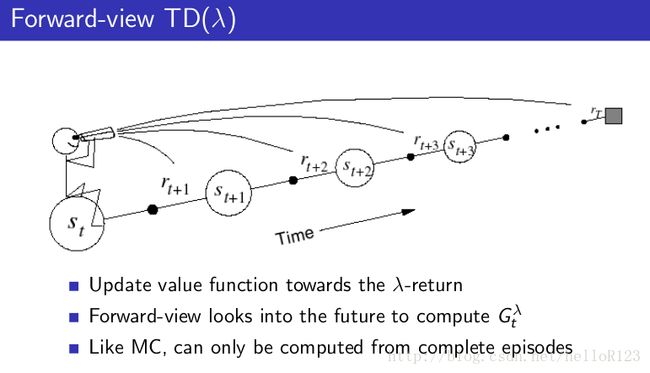

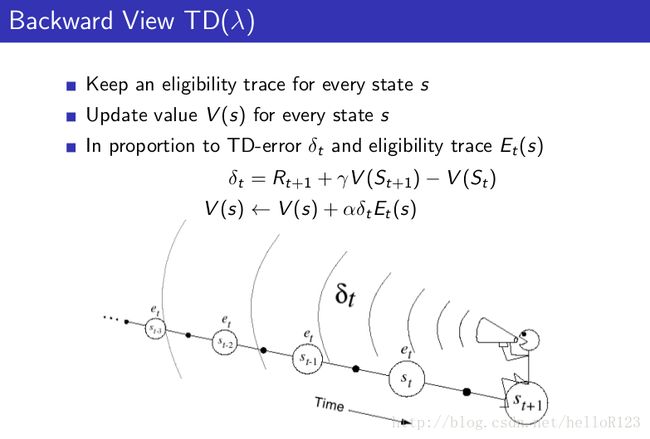
关于前向视角和后向视角的等价行,如下图:
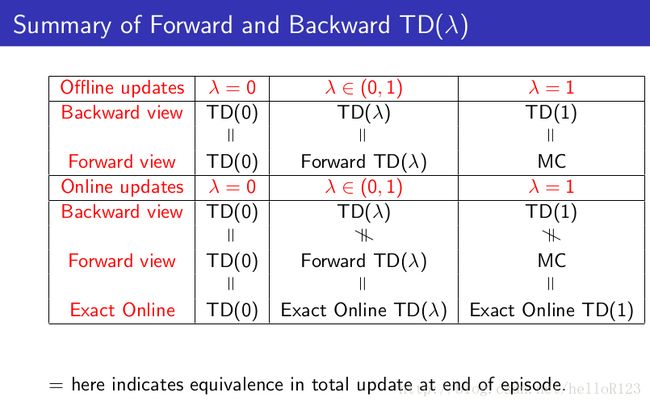
其中off-line update是说在一个episode完后再用累计的更新值去更新,而on-line update是说每经过一个time step就马上更新。
更多的讨论可以看:https://zhuanlan.zhihu.com/p/27773020 和https://zhuanlan.zhihu.com/p/28017357 。
TD(lamda)的优点是:
比较好地权衡bias和variance
考虑到了各种n-step return,更新速度会快很多
缺点是:
- 只适用于有终止状态的MDP ?
MC-TD 控制
MC和TD控制就是把MC和TD的估计过程套入到广义策略迭代或者值迭代的框架里。而控制中又设计到两个概念:on-policy和off-policy。on-policy是指在采样时用的就是我们学到的策略,而off-policy是指采样时用到的任意的策略(可以不是学到的策略)。off-policy的存在一来可以学习其他代理如何学习,二来也能利用以往用过的策略采样到的样本也就是说它更data efficient。此外,当设计到控制时,另一个问题是exploration和exploitation的问题,之前动态规划里因为知道模型,所以不用其他状态即使没有访问过也知道它的信息,而像MC和TD这样的通过采样的方法,只知道访问过的状态的信息,因而也就要考虑是继续去访问其他状态还是利用好现在的信息:

更多的关于探索与利用的讨论会在后面的博文里介绍。
在TD控制中比较常用的两个算法是Sarsa(on-policy)和Q learning(off-policy)(注意,因为我们现在不知道模型,所以是直接去求动作值函数而不是状态值函数)。
Sarsa和Sarsa(lamda):


Sarsa收敛的条件:

Q learning:

Sarsa是广义策略迭代的框架,而Q leanring是值迭代的框架(当然也可以理解成是广义策略迭代,但我个人觉得理解成值迭代能够更好地理解其收敛性和为什么是off-policy的方法)
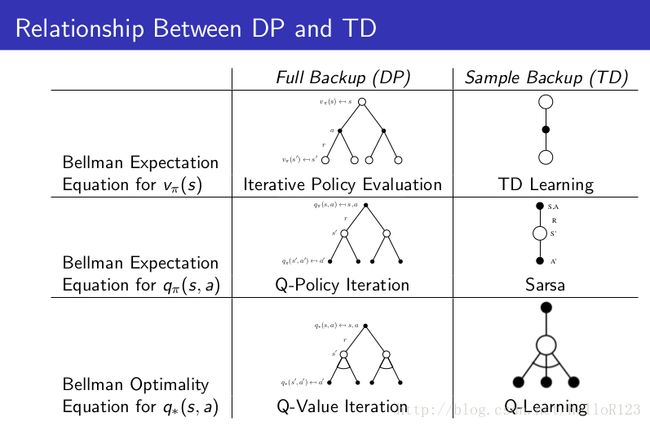
动态规划(DP)和TD的关系:

函数近似
上面提到的方法都是针对有限状态的时候来说的,而对于状态非常多或者无穷个时,就要用到函数近似的方法,其实就是监督学习里的回归的方法。
之前有限状态时把状态看作是一个索引,但无穷的时候则不能够这样做,因为考虑不了所有的状态,所以通过部分样本来拟合值函数,我们期望拟合出来的函数具有泛化的能力,在其他没有见过的状态中也能估计地准,此时的状态就不再仅仅是一个索引,而是用来得到值函数的依据信息,如下图:

我们先假设有一个先知能告诉我们样本中各种状态的值函数的准确值,那么我们就可以通过梯度下降的方法去学习应该参数:

但实际上并没有这样的先知告诉我们准确值,所以这时候在MC/TD控制中我们就用相应的估计值来近似代替准确值:

在MC控制中,虽然Gt不一定是真的准确值,但它是无偏的,因而收敛性会更好,而TD(0)控制中,Rt+V(st+1)是有偏的,在函数近似中它更容易发散,因为它不遵从任何的目标函数。
对于TD(lamda)也有相应的资格迹方法,只不过这时的资格迹针对的就是参数而不是一个个具体的状态的价值函数:

上面的图都是针对状态价值函数的,对于动作价值函数也基本一样。
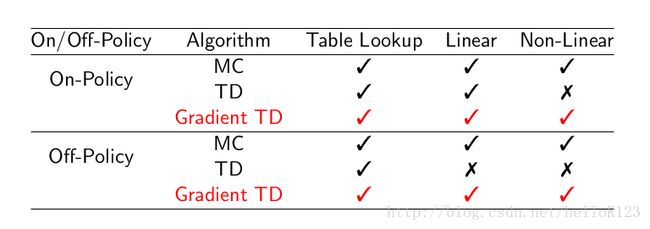
当函数近似的方法用于估计时,收敛性如下:
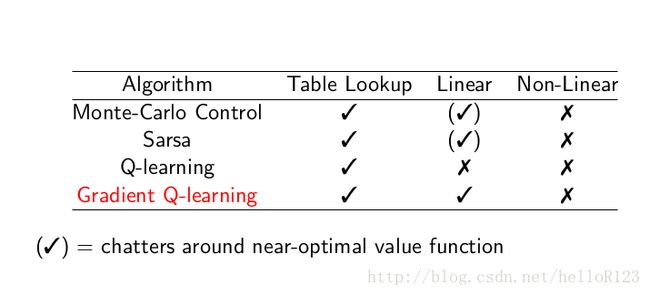
而用于控制时,收敛性如下:
此外,对于TD控制的方法来说,随机梯度下降的方法由于每更新一次都会让其优化的目标函数改变一次,而且原始的on-line learning更让样本成了非iid的,而监督学习都是假设样本是iid的,所以这样子训练会带来比较大的不稳定性。总的来说,TD控制的不稳定性来自于(1)随机梯度下降;(2)训练样本非iid;(3)没有固定的优化目标函数。
所以,在DQN中,用experience replay(其实也就是将随机梯度下降改为批梯度下降)来缓解(1)和(2)带来的不稳定性,用fix target Q network(在一段时间内固定优化的目标函数)来缓解(3)带来的不稳定性。