Hive操作
为什么会出现Hive?
关系型数据库已产生多年,SQL成熟简化开发,降低人员成本、Java人员可编写UDF函数
一、 Hive导入、导出
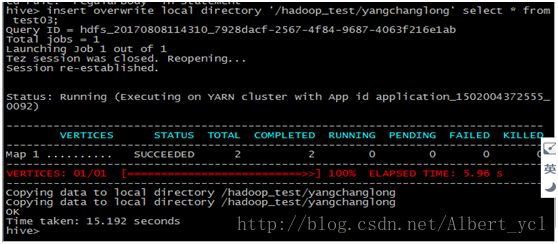
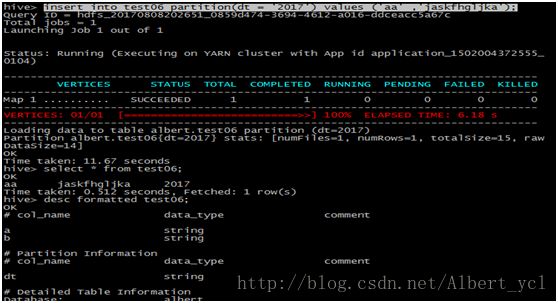
导入(在hive中敲)
《root》load data local inpath '/home/hdfs/a.txt' overwrite into tableouter_talbe1;
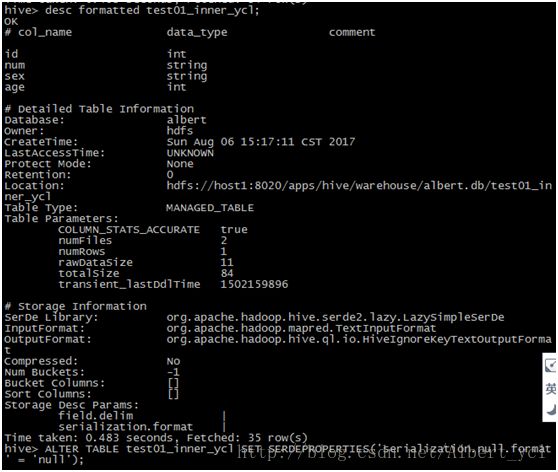
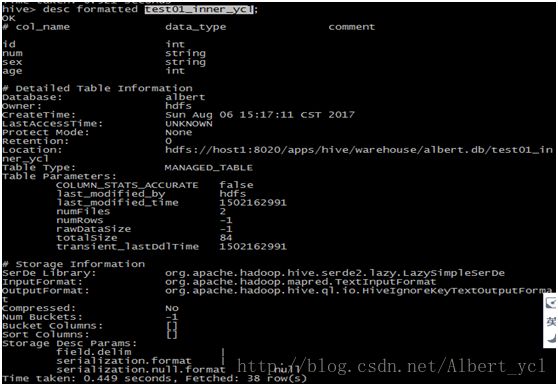
NULL值处理
hive中NULL默认是以'\N'表示的可以通过ALTER TABLE table_name SETSERDEPROPERTIES('serialization.null.format' = '');修改空值描述符
导出
导出到本地文件系统:
insert overwrite localdirectory '/home/wyp/wyp' select * from wyp;
导出到HDFS:
insert overwrite directory '/home/wyp/hdfs'select * from wyp;
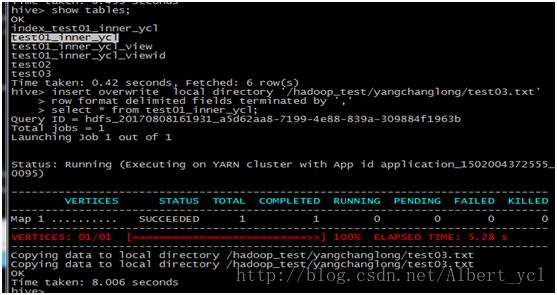
指定分隔符号:
insert overwrite local directory'/home/yangping.wu/local'
row format delimited
fields terminated by ','
select *from wyp;
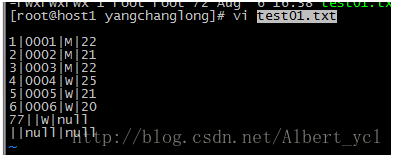
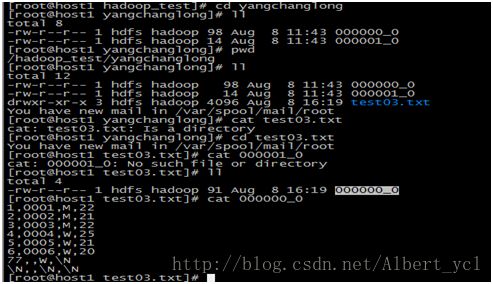
1,新建一个txt文件,并往里面添加内容
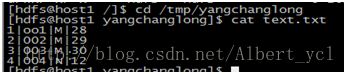
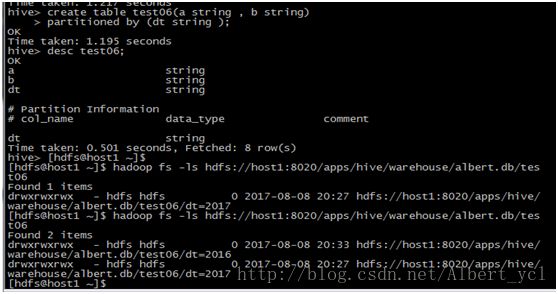
2,创建表
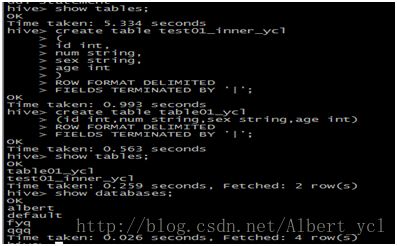
create table test01_inner_yangchanglong
(
id int,
num string,
sex string,
age int
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|';
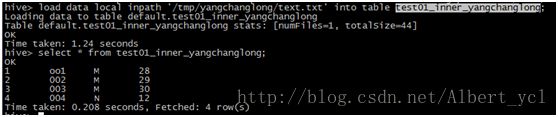
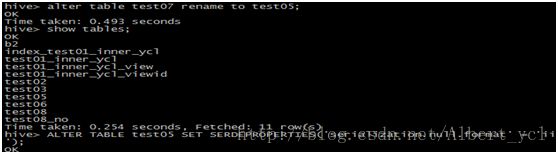
图一,数据导入
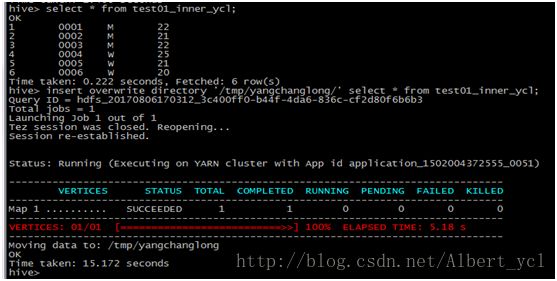
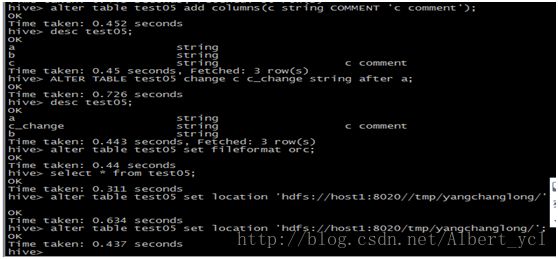
图二,数据导出
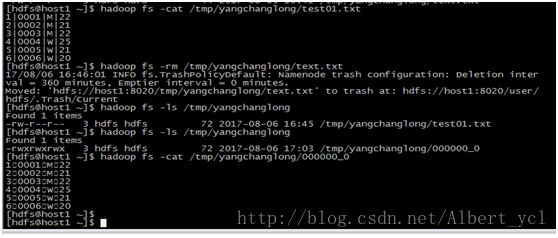
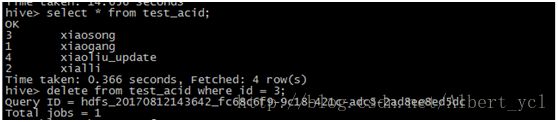
图三,数据查看\删除
3.数据导入补充

4.数据导出补充

HDFS:1,文件形式(服务器);2,DB(数据库);3,数据流(日志。。。)
Hive导入:1,其他表获得;2,从HDFS上获得;3,从服务器上导入
将数据导入hive(六种方式)
1.从本地导入
loaddata local inpath 'file_path' into table tbname;
用于一般的场景。
2.从hdfs上导入数据
loaddata inpath ‘hafd_file_path’ into table tbname;
使用与大数据的存储
3.load方式的覆盖
loaddata local inpath 'file_path' overwrite into table tbname;
用于零时表。
4.子查询方式
create table tb2 as select * from tb1;
5.insertinto
insertinto table tb2 select q1;
6.location
然后put就好。
将数据从hive里导出(四种方式)
1.insert方式
1)保存到本地
insertoverwrite local directory 'path' select q1;
insert overwrite local directory 'path' row format delimited fields terminated by '\t' select q1;
2)保存到HDFS上
insert overwrite directory 'hdfs_path' select* from dept;
注意点:hdfs_path必须存在
2.bin/hdfs -get
与put一样,属于HDFS的基本操作。
dfs -get.............
3.linux的重定向,其中-e 表示后面直接接带双引号的sql语句;而-f是接一个文件,文件的内容为一个sql语句
-e
-f
4.sqoop协作框架。
二、 创建索引、视图练习
1.创建索引:

hive> create index [index_studentid] on table student_3(studentid)
> as'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
> with deferredrebuild
> IN TABLEindex_table_student_3;
OK
Time taken: 12.219seconds
hive>
org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler :创建索引需要的实现类
index_studentid:索引名称
student_3:表名
index_table_student_3:创建索引后的表名
2.查看索引表:
hive>select*fromindex_table_student_3;
OK
Timetaken: 0.295 seconds
3.加载索引数据:
![]()
hive> alter index index_studentid on student_3 rebuild;
4.查询索引表中数据:
![]()
hive> select*from index_table_student_3;
5.删除索引:
![]()
DROP INDEX index_studentid on student_3;
6.查看索引
![]()
hive> SHOW INDEX on student_3;
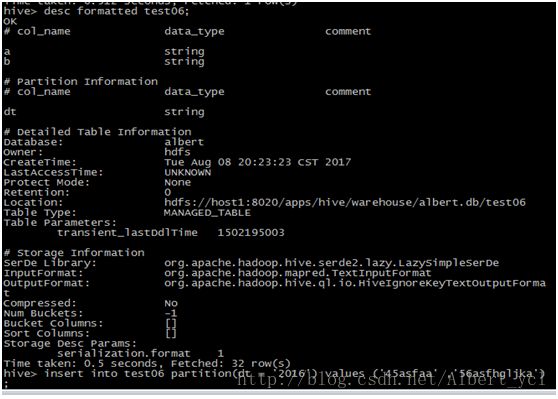
(分区和分桶中分区以HDFS中文件分隔来分区,如果继续按需求分的话,在最后那个文件中进行分桶)索引和分区不同,它根据表格中某个属性进行划分。
索引: 每次查询时候都要先用一个job扫描索引表,如果索引列的值非常稀疏,那么索引表本身也会非常大;
索引表不会自动rebuild,如果表有数据新增或删除,那么必须手动rebuild索引表数据;
视图:只有逻辑视图,没有物化视图;
视图只能查询,不能Load/Insert/Update/Delete数据;
视图在创建时候,只是保存了一份元数据,当查询视图的时候,才开始执行视图对应的那些子查询。
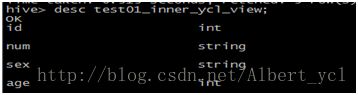
1.创建视图:
![]()
![]()
2.查看视图:
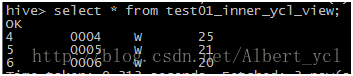
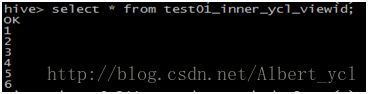

删除一个视图
使用下面的语法来删除视图:
DROP VIEW view_name
1. 新增数据
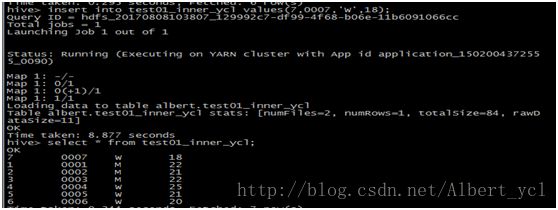
2. 新增表格并且插入或覆盖数据
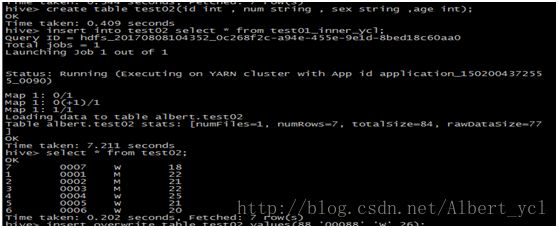
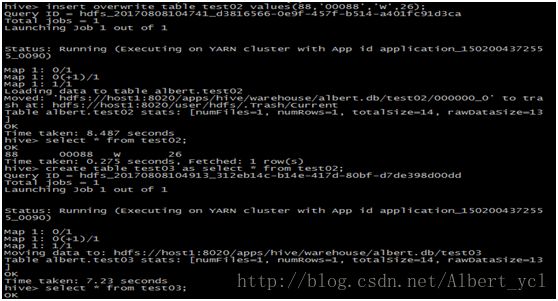
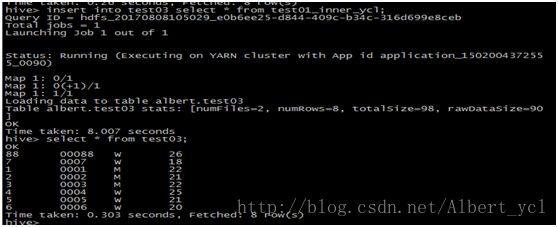
3. 查询和关联
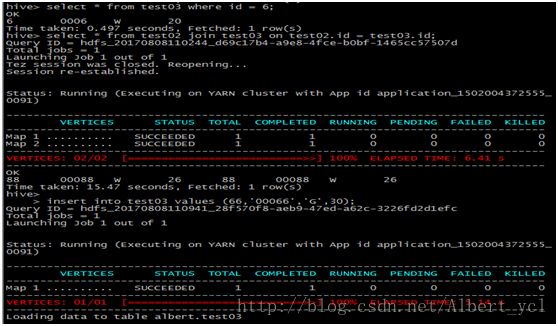
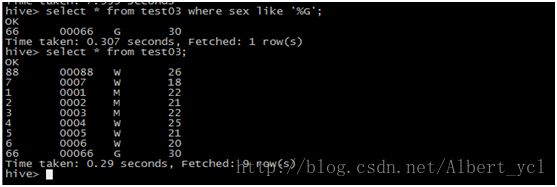
4. 分区
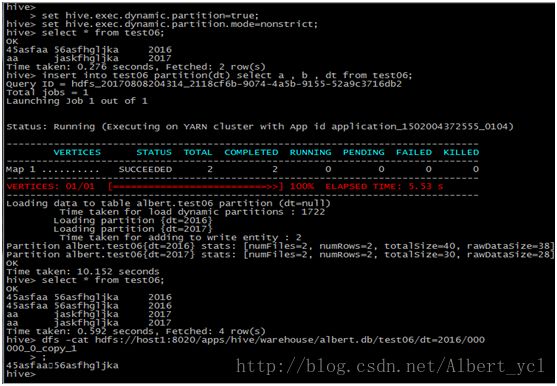

根据ID进行分桶,根据score进行排序
![]()

5. alert操作
![]()

三、 事务表练习
创建一个表

如图表,和插入的数据:

数据插入成功和更新数据:

数据更新成功和删除数据:

何为事务?就是一组单元化操作,这些操作要么都执行,要么都不执行,是一个不可分割的工作单位。
事务(transaction)所应该具有的四个要素:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。这四个基本要素通常称为ACID特性。
- 原子性(Atomicity)
- 一个事务是一个不可再分割的工作单位,事务中的所有操作要么都发生,要么都不发生。
- 一致性(Consistency)
- 事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。这是说数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。
- 隔离性(Isolation)
- 多个事务并发访问,事务之间是隔离的,一个事务不影响其它事务运行效果。这指的是在并发环境中,当不同的事务同时操作相同的数据时,每个事务都有各自完整的数据空间。事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改后的状态,事务不会查看到中间状态的数据。
- 事务之间的相应影响,分别为:脏读、不可重复读、幻读、丢失更新。
- 持久性(Durability)
- 意味着在事务完成以后,该事务锁对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
hive事务的限制条件
1.在现在的版本中,只支持ORC文件格式。
2.默认情况下,hive的事务性是关闭的,开启需要设置transactional=true。
3.表必须是Bucket表。
4.外部表不能成为ACID表,因为外部表的变化,不能被Compact控制。
5.不能从一个非ACID会话向ACID表中读写数据。这意味着Hive事务管理必须设置成org.apache.Hadoop.hive.ql.lockmgr.DbTxnManager
6.目前只支持快照级别的隔离,不支持脏读,重复读等。
7.存在的Zookeeper和内存锁管理机制与事务是不兼容的
Hive事务的开启步骤
set hive.support.concurrency=true;
set hive.enforce.bucketing=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
Hive支持CRUD原理:
Hive的ORC格式文件,有base files和deltafiles。
base files是基础文件,delta files是增删改操作生成的新文件。
当进行ACID操作的时候,base files 和 delta files会发生变化,
满足一定条件后,这两类文件会进行合并,产生新的base files。
文件的合并,由下面两个参数决定
hive.compactor.check.interval
检查表或者分区是否需要compact的时间间隔,秒为单位,默认300秒。
检查的方式是,向Namenode发送请求,查看相应的表或者分区是否发生事务操作。
hive.compactor.max.num.delta
compactor尝试在一个job中处理的最多的Delta文件个数
Compaction不支持并发的读写数据,在Compaction之后,系统会等所有对老文件的读完成之后,才删除老文件
hive事务表参数配置
sethive.support.concurrency=true;
sethive.enforce.bucketing=true;
sethive.exec.dynamic.partition.mode=nonstrict;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
以上配置在hive-site中配置;
sethive.compactor.initiator.on=true;
sethive.compactor.worker.threads=1;
以上配置在hiveserver2-site中配置;
事务管理
对hive表进行更新的时候,管理事务是很重要的一个部分。
metastore会跟踪正在进行的读和写事务。
为了提供一个持续性的视图来进行读操作,metastore会对每一个写操作创建一个事务ID。
事务ID,在一个metastore中是从1严格增长的。
在内部,事务是通过Hive Metastore管理的。
具体修改操作是通过ORC API执行到HDFS上面的,绕开了Metastore。
当一个读操作开始的时候,metastore会提供读的表,和当前已经提交的事务ids集合。这些集合由最大提交事务id和还在进行中的事务id。
当进行查询操作的时候,会启动MR任务,相同的集合会通过jobconf提供给MR任务,因此,读操作看到的是,命令开始那一刻,表的一个连续的snapshot视图。
写操作,metastore会提供正在被读的表和正在被写的表的列表,获取到一个可以读取的有效事务id集合,和写事务id。所有的写入数据,都会打上写事务id标签。
在上面两种情况,当命令完成的时候,它应该通知metastore。metastore一定要确认或者放弃被抛弃的事务,hive客户端一定要每十分钟通知metastore一次,说明命令还在运行,否则的话,这个事务会被放弃。metastore会维护着被读的表集合和相应的事务id,这样它可以在上次读操作完成后,调度合并完数据的删除。
在一个写事务被提交到metastore之前,所有的那个事务的HDFS文件必须在它们的最终位置。
同时,在一个写事务被放弃之前,所有的文件必须从HDFS上面删除了。
这能保证,给reader的任何有效的事务id都只有正确的HDFS文件与它关联。
Hive事务使用建议
- 传统数据库中有三种模型隐式事务、显示事务和自动事务。在目前Hive对事务仅支持自动事务,因此Hive无法通过显示事务的方式对一个操作序列进行事务控制。
- 传统数据库事务在遇到异常情况可自动进行回滚,目前Hive无法支持ROLLBACK。
- 传统数据库中支持事务并发,而Hive对事务无法做到完全并发控制,多个操作均需要获取WRITE的时候则这些操作为串行模式执行(在测试用例中"delete同一条数据的同时update该数据",操作是串行的且操作完成后数据未被删除且数据被修改)未保证数据一致性。
- Hive的事务功能尚属于实验室功能,并不建议用户直接上生产系统,因为目前它还有诸多的限制,如只支持ORC文件格式,建表必须分桶等,使用起来没有那么方便,另外该功能的稳定性还有待进一步验证。
- CDH默认开启了Hive的Concurrency功能,主要是对并发读写的的时候通过锁进行了控制。所以为了防止用户在使用Hive的时候,报错提示该表已经被lock,对于用户来说不友好,建议在业务侧控制一下写入和读取,比如写入同一个table或者partition的时候保证是单任务写入,其他写入需控制写完第一个任务了,后面才继续写,并且控制在写的时候不让用户进行查询。另外需要控制在查询的时候不要允许有写入操作。
- 如果对于数据一致性不在乎,可以完全关闭Hive的Concurrency功能关闭,即设置hive.support.concurrency为false,这样Hive的并发读写将没有任何限制。
附录:http://www.infoq.com/cn/articles/guide-of-hive-transaction-management