关于storm的一些知识点
详述storm系统架构

Nimbus:是整个集群的控管核心,负责topology的提交、运行状态监控、任务重新分配等工作。
zookeeper就是一个管理者,监控者,Storm的所有的状态信息都是保存在Zookeeper里面,nimbus通过在zookeeper上面写状态信息来分配任务,supervisor,task通过从zookeeper中读状态来领取任务,同时supervisor, task也会定义发送心跳信息到zookeeper,使得nimbus可以监控整个storm集群的状态,从而可以重启一些挂掉的task。ZooKeeper使得整个storm集群十分的健壮,任何一台工作机器挂掉都没有关系,只要重启然后从zookeeper上面重新获取状态信息就可以了。
Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。通过配置文件设置当前supervisor上启动多少个worker,默认4个。
Worker:运行具体处理组件逻辑的进程(在Supervisor)。Worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
总体描述:nimbus下命令(分配任务),zk监督执行(心跳监控,worker、supurvisor的心跳都归它管),supervisor领旨(下载代码),招募人马(创建worker和线程等),worker、executor就给我干活!task就是具体要干的活。
Storm集群中有两类节点:主控节点(Master Node)和工作节点(Worker Node)。其中,主控节点只有一个,而工作节点可以有多个。
主控节点运行一个称为Nimbus的守护进程类似于Hadoop的JobTracker。Nimbus负责在集群中分发代码,对节点分配任务,并监视主机故障。
每个工作节点运行一个称为Supervisor的守护进程。Supervisor监听其主机上已经分配的主机的作业,启动和停止Nimbus已经分配的工作进程。
流分组,是拓扑定义中的一部分,为每个Bolt指定应该接收哪个流作为输入。流分组定义了流/元组如何在Bolt的任务之间进行分发。Storm内置了8种流分组方式。
Worker是Spout/Bolt中运行具体处理逻辑的进程。一个worker就是一个进程,进程里面包含一个或多个线程。
一个线程就是一个executor,一个线程会处理一个或多个任务。
一个任务就是一个task。
详述storm的计算模型
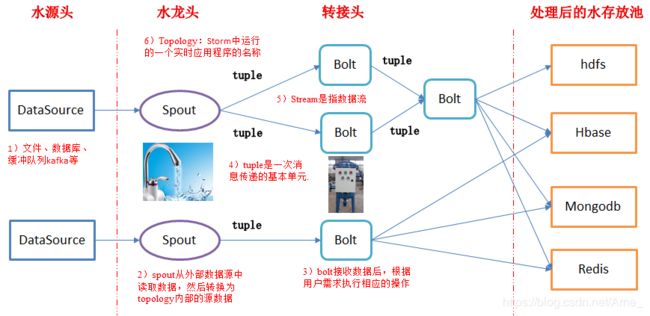
Topology:Storm中运行的一个实时应用程序的名称,因为各个组件间的消息流动而形成逻辑上的拓扑结构。(拓扑-DAG有向无环图的实现)
把实时应用程序的运行逻辑打成jar包后提交到Storm的拓扑(Topology)。Storm的拓扑类似于MapReduce的作业(Job)。其主要的区别是,MapReduce的作业最终会完成,而一个拓扑永远都在运行直到它被杀死。一个拓扑是一个图的Spout和Bolt的连接流分组。
Spout:在一个topology中获取源数据流的组件,Spout是拓扑的流的来源,是一个拓扑中产生源数据流的组件。通常情况下,Spout会从外部数据源中读取数据,然后转换为拓扑内部的源数据。
Spout可以是可靠的,也可以是不可靠的。如果Storm处理元组失败,可靠的Spout能够重新发射,而不可靠的Spout就尽快忘记发出的元组。
Spout可以发出超过一个流。
Spout的主要方法是nextTuple()。NextTuple()会发出一个新的Tuple到拓扑,如果没有新的元组发出,则简单返回。
Spout的其他方法是ack()和fail()。当Storm检测到一个元组从Spout发出时,ack()和fail()会被调用,要么成功完成通过拓扑,要么未能完成。Ack()和fail()仅被可靠的Spout调用。
IRichSpout是Spout必须实现的接口。
通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。
Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。
在拓扑中所有处理都在Bolt中完成,Bolt是流的处理节点,从一个拓扑接收数据,然后执行进行处理的组件。Bolt可以完成过滤、业务处理、连接运算、连接与访问数据库等任何操作。
Bolt是一个被动的角色,接口中有一个execute()方法,在接收到消息后会调用此方法,用户可以在其中执行自己希望的操作。
Bolt可以完成简单的流的转换,而完成复杂的流的转换通常需要多个步骤,因此需要多个Bolt。
Bolt可以发出超过一个的流。
Tuple:是消息传递的基本单元,是一个命名的值列表,元组中的字段可以是任何类型的对象。Storm使用元组作为其数据模型,元组支持所有的基本类型、字符串和字节数组作为字段值,只要实现类型的序列化接口就可以使用该类型的对象。元组本来应该是一个key-value的Map,但是由于各个组件间传递的元组的字段名称已经事先定义好,所以只要按序把元组填入各个value即可,所以元组是一个value的List。
Stream:是一个无界的元组系列。源源不断传递的元组就组成了流,在分布式环境中并行地进行创建和处理。
详述什么是storm的流分组
stream grouping用来定义一个stream应该如何分配给Bolts上面的多个Executors(多线程、多并发)。Storm里面有8种类型的stream grouping
1)Shuffle Grouping: 随机分组,轮询,平均分配。随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
2)Fields Grouping**:按字段分组**,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
3)All Grouping**:广播发送**,对于每一个tuple,所有的bolts都会收到。
4)Global Grouping**:全局分组**,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
5)Non Grouping**:不分组**,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果。在多线程情况下不平均分配。
6)Direct Grouping**:直接分组**,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id (OutputCollector.emit方法也会返回task的id)。
7)Local or Shuffle Grouping**:**如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发送给这些tasks。否则,和普通的Shuffle Grouping行为一致。
8**)customer Grouping**:自定义,相当于MapReduce自己自己去实现一个partition。
手写wordcount
搭建storm分布式步骤
--------------------------------------------------------------------
storm完全分布式搭建
1、配置zookeeper
2、将storm解压到/opt
3、配置:
#配置zookeeper的地址
storm.zookeeper.servers:
- "storm01"
- "storm02"
- "storm03"
# nimbus的位置
nimbus.host: "storm01"
ui.port: 9090
# 指定每个supervisor上worker的通信端口
# 有几个端口就有几个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4、分发storm包
6、启动zookeeper集群
7、启动storm的进程
storm01:
nimbus
bin/storm nimbus >> logs/nimbus.out 2>&1 &
supervisor
bin/storm supervisor >> logs/supervisor.out 2>&1 &
ui
bin/storm ui >> logs/ui.out 2>&1 &
storm02:
supervisor
bin/storm supervisor >> logs/supervisor.out 2>&1 &
storm03:
supervisor
bin/storm supervisor >> logs/supervisor.out 2>&1 &
-----------------------------------------------------------------------s
storm单节点搭建
1、jdk1.7安装并配置
2、解压storm包,不需要任何配置
3、在storm根目录下创建logs文件夹
4、启动
bin/storm helpbin/storm help查看帮助
bin/storm help nimbus查看nimbus的使用方式
a)先启动zookeeper
bin/storm dev-zookeeper >> logs/zk.out 2>&1 &
b)启动nimbus,将标准输出重定向到当前目录的logs中的nimbus.out
错误输出也重定向到该文件,最后的&表示后台运行
bin/storm nimbus >> logs/nimbus.out 2>&1 &
c) 启动supervisor
bin/storm supervisor >> logs/supervisor.out 2>&1 &
d) 启动storm ui
bin/storm ui >> logs/ui.out 2>&1 &
ss nal
提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
[root@storm02 storm02]# ./bin/storm jar ~/wc.jar wordcount.Test1 wc
storm如何保障消息的完全处理?
storm的消息完全处理是从spout开始的,在spout发出tuple的时候,带上一个id,将ID作为参数传递给SputOutputCollector的emit()方法:
collector.emit(new Values(“value1”,“value2”), msgId);
Storm 中有一组"acker"任务,负责跟踪DAG(有向无环图)中的每个消息。
acker任务里面保存了spout id到一对值的映射。第一个值就是spout的任务id,通过这个id,acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64位的数字,是所有消息的随机id的异或的计算结果,它表示了消息任务的的ss状态,结果为0表示完全处理了,否则就是处理失败或者超时,会调用fail()方法或者30S后重发。
storm中drpc做什么用的?架构?
Storm里面引入DRPC主要是利用 Storm的实时计算能力来并行化计算任务,以实现实时计算,实时获得结果。
Storm DRPC就是客户端发送请求,发送给Strom Topology,经过Storm处理后将客户端所请求的结果返回给客户端。
DRPC包括服务端和客户端两部分
1)服务端
服务端由四部分组成:包括一个DRPC Server, 一个 DPRC Spout,一个Topology和一个ReturnResult。
a.启动Storm中的DRPC Server;
首先,修改Storm/conf/storm.yaml中的drpc server地址;需要注意的是:必须修改所有Nimbus和supervisor上的配置文件,设置drpc server地址。否则在运行过程中可能无法返回结果。
然后,通过 storm drpc命令启动drpc server。
b.创建一个DRPC 的Topology,提交到storm中运行。
普通的Topology不同,可以通过两种方式创建:
创建方法一:直接使用 Storm 提供的LinearDRPCTopologyBuilder。 (不过该方法在0.82版本中显示为已过期,不建议使用)
创建方法二:
直接使用 Storm 提供的TopologyBuilder。 需要自己手动加上开始的DRPCSpout和结束的ReturnResults。
其实Storm 提供的LinearDRPCTopologyBuilder也是通过这种封装而来的。
TopologyBuilder builder = new TopologyBuilder();
//开始的Spout
DRPCSpout drpcSpout = new DRPCSpout("exclamation");
builder.setSpout("drpc-input", drpcSpout,5);
//真正处理的Bolt
builder.setBolt("cpp", new CppBolt(), 5).noneGrouping("drpc-input");
//结束的ReturnResults
builder.setBolt("return", new ReturnResults(),5).noneGrouping("cpp");
Config conf = new Config();
conf.setDebug(false);
conf.setMaxTaskParallelism(3);
try{ StormSubmitter.submitTopology("exclamation",conf,builder.createTopology());
}catch (Exception e){
e.printStackTrace();
}
详述kafka的架构

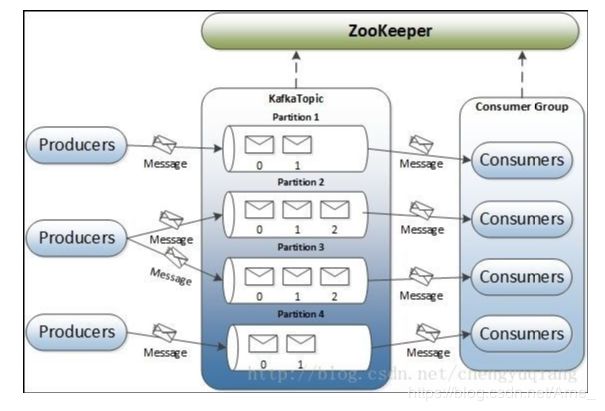
在kafka结构中有多个Producer、多个Broker,多个Consumer,每个Producer可以对应多个Topic,每个Consumer只能对应一个ConsumerGroup。
整个Kafka架构对应一个zookeeper集群,通过ZK管理集群配置,选举Leader,以及在consumer group发生变化时进行rebalance。
Producer:生产者,向broker发送消息
Consumer:消费者,从Broker读取消息
ConsumerGroup:每个Consumer属于一个特定的Consumer Group,一条消息可以发送到多个不同的Consumer Group,但是一个Consumer Group中只能有一个Consumer能够消费该消息
Broker:一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
Topic主题**:Kafka**根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
Partition分区:一个topic可以分为多个partition,每个partition内部是有序的
详述kafka消息队列的安装步骤
1.前提要有zookeeper 集群
2.上传解压安装包
3.修改config/server.properties
修改集群中唯一标识id: broker.id=0,其余两个节点分别是1,2
配置zookeeper:
zookeeper.connect=192.168.200.29:2181,192.168.200.30:2181,192.168.200.31:2181
完成,保存
启动集群,三个节点
[root@storm01 bin]# ./kafka-server-start.sh …/config/server.properties
看到这一行基本没什么问题
[2019-06-25 14:58:53,056] INFO [Socket Server on Broker 0], Started 1 acceptor threads (kafka.network.SocketServer)
然后就是测试
创建topic
[root@storm01 bin]# ./kafka-topics.sh --zookeeper storm01:2181,storm02:2181,storm03:2181 --create --replication-factor 2 --partitions 3 --topic test
Created topic "test".
查看topic列表
[root@storm01 bin]# ./kafka-topics.sh --zookeeper storm01:2181,storm02:2181,storm03:2181 --list
test
查看topic描述
[root@storm01 bin]# ./kafka-topics.sh --zookeeper storm01:2181,storm02:2181,storm03:2181 --describe --topic test
Topic:test PartitionCount:3 ReplicationFactor:2 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: test Partition: 1 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0
创建生产者
[root@storm01 bin]# ./kafka-console-producer.sh --broker-list storm01:9092,storm02:9092,storm03:9092 --topic test
11
22
创建消费者
[root@storm01 bin]# ./kafka-console-consumer.sh --zookeeper storm01:2181,storm02:2181,storm03:2181 --from-beginning --topic test
11
22