【算法杂谈】Dancing Link
Dancing Link是解决精确覆盖问题的最有效方法之一。
精确覆盖问题:给定一个由0和1组成的矩阵,是否能找到一个行的集合,使得集合中每一列都恰好包含一个1?
例如,下面这个矩阵
就包含了这样一个集合(第1,4,5行)。我们把列想象成全集的一些元素,而行看作全集的一些子集;或者我们可以把行想象成全集的一些元素,而把列看作全集的一些子集;那么这个问题就是要求寻找一批元素,它们与每个子集恰好有一个交点。
算法X:对于接下来的非确定性算法,由于我们没有想到更好的名字,我们将称之为X算法,它能够找到由特定的01矩阵A定义的精确覆盖问题的所有解。X算法是实现试验——错误这一显而易见的方法的一段简单的语句(确实,一般来说,我想不到别的合理的方法来完成这个工作)。
如果A是空的,问题解决;成功终止。
否则,选择一个列c(确定的)。
选择一个行r,满足 A[r, c]=1 (不确定的)。
把r包含进部分解。
对于所有满足 A[r,j]=1 的j,
从矩阵A中删除第j列;
对于所有满足 A[i,j]=1 的i,
从矩阵A中删除第i行。
在不断减少的矩阵A上递归地重复上述算法。舞蹈步骤:
一个实现X算法的好方法就是将矩阵A中的每个1用一个有5个域L[x]、R[x]、U[x]、D[x]、C[x]的数据对象(data object)x来表示。矩阵的每行都是一个经由域L和R(“左”和“右”)双向连接的环状链表;矩阵的每列是一个经由域U和D(“上”和“下”)双向连接的环状链表。每个列链表还包含一个特殊的数据对象,称作它的表头(list header)。
这些表头是一个称作列对象(column object)的大型对象的一部分。每个列对象y包含一个普通数据对象的5个域L[y]、R[y]、U[y]、D[y]和C[y],外加两个域S[y](大小)和N[y](名字);这里“大小”是一个列中1的个数,而“名字”则是用来标识输出答案的符号。每个数据对象的C域指向相应列头的列对象。
表头的L和R连接着所有需要被覆盖的列。这个环状链表也包含一个特殊的列对象称作“根”,h,它相当于所有活动表头的主人。而且它不需要U[h]、D[h]、C[h]、S[h]和N[h]这几个域。
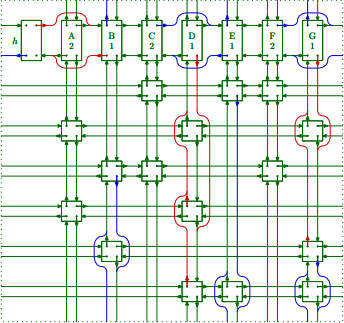
举个例子,(3)中的0-1矩阵将用这些数据对象来表示,就像图2展示的那样,我们给这些列命名为A、B、C、D、E、F和G(这个图表在上下左右处“环绕扭曲”。C的连线没有画出,因为他们会把图形弄乱;每个C域指向每列最顶端的元素)。

我们寻找所有精确覆盖的不确定性算法现在可以定型为下面这个明析、确定的形式,即一个递归过程search(k),它一开始被调用时k=0:
如果 R[h]=h ,打印当前的解(见下)并且返回。
否则选择一个列对象c(见下)。
覆盖列c(见下)。
对于每个r←D[c],D[D[c]],……,当 r!=c,
设置 Ok<-r;
对于每个j←R[r],R[R[r]],……,当 j!=r,
覆盖列j(见下);
search(k+1);
设置 r←Ok 且 c←C[r];
对于每个j←L[r],L[L[r]],……,当 j!=r,
取消列j的覆盖(见下)。
取消列c的覆盖(见下)并且返回。输出当前解的操作很简单:我们连续输出包含O0、O1、……、Ok-1的行,这里包含数据对象O的行可以通过输出N[C[O]]、N[C[R[O]]]、N[C[R[R[O]]]]……来输出。
为了选择一个列对象c,我们可以简单地设置c<-R[h];这是最左边没有覆盖的列。或者如果我们希望使分支因数达到最小,我们可以设置s<-无穷大,那么接下来:
对于每个j←R[h],R[R[h]],……,当 j!=h,
如果 S[j]那么c就是包含1的序数最小的列(如果不用这种方法减少分支的话,S域就没什么用了)。
覆盖列c的操作则更加有趣:把c从表头删除并且从其他列链表中去除c链表的所有行。
设置 L[R[c]]←L[c] 且 R[L[c]]←R[c]。
对于每个i←D[c],D[D[c]],……,当 i!=c,
对于每个j←R[i],R[R{i]],……,当 j!=i,
设置 U[D[j]]←U[j],D[U[j]]←D[j],
并且设置 S[C[j]]←S[C[j]]-1。操作(1),就是我在本文一开始提到的,在这里他被用来除去水平、竖直方向上的数据对象。
最后,我们到达了整个算法的尖端,即还原给定的列c的操作。这里就是链表舞蹈的过程:
对于每个i←U[c],U[U[c]],……,当 j!=i,
对于每个j←L[i],L[L[i]],……,当 j!=i,
设置 S[C[j]]←S[C[j]]+1,
并且设置 U[D[j]]←j,D[U[j]]←j。
设置 L[R[c]]←c 且 R[L[c]]←c。注意到还原操作正好与覆盖操作执行的顺序相反,我们利用操作(2)来取消操作(1)。(其实没必要严格限制“后执行的先取消”,由于j可以以任何顺序穿过第i行;但是从下往上取消对行的移除操作是非常重要的,因为我们是从上往下把这些行移除的。相似的,对于第r行从右往左取消列的移除操作也是十分重要的,因为我们是从左往右覆盖的。)

考虑一下,例如,对图2表示的数据(3)执行search(0)会发生什么。通过从其他列移除A的行来将其覆盖;那么现在整个结构就成了图3的样子。注意现在D列出现了不对称的链接:上面的元素首先被删除,所以它仍然指向初始的邻居,但是另一个被删除的元素指向了列头。
继续search(0),当r指向(A,D,G)这一行的A元素时,我们也覆盖D列和G列。图4展示了我们进入search(1)时的状态,这个数据结构代表削减后的矩阵

现在search(1)将覆盖B列,而且C列将没有“1”。因此search(2)将什么也找不到。接着search(1)会找不到解并返回,图4的状态会恢复。外部的过程,search(0),将把图4变回图3,而且它会让r前进到(A,D)行的A元素处。
很快就能找到解,并输出
A D
E F C
B G
如果在选择c的时候无视S域,会输出
A D
B G
C E F
以上内容来自Knuth的论文Dancing Links中文版。
算法模版如下:
struct DLX
{
int n,sz; //列数,节点总数
int S[MAXN]; //各列节点总数,我们每次删除S最小的未删除列,可以加快求解速度
int row[MAXNODE],col[MAXNODE]; //各节点行列编号
int L[MAXNODE],R[MAXNODE],U[MAXNODE],D[MAXNODE]; //十字链表
int ansd,ans[MAXR]; //解
void init(int n) //n是列数
{
this->n=n;
for (int i=0; i<=n; i++) U[i]=i, D[i]=i, L[i]=i-1, R[i]=i+1; //虚拟节点
R[n]=0,L[0]=n;
sz=n+1;
memset(S,0,sizeof(S));
}
void AddRow(int r, vector<int> columns)
{
int first=sz;
for (int i=0; iint c=columns[i];
L[sz]=sz-1; R[sz]=sz+1; D[sz]=c; U[sz]=U[c];
D[U[c]]=sz; U[c]=sz;
row[sz]=r; col[sz]=c;
S[c]++; sz++;
}
R[sz-1]=first; L[first]=sz-1;
}
//顺着链表A,遍历s外的其他元素
#define FOR(i,A,s) for (int i=A[s]; i!=s; i=A[i])
void Remove(int c)
{
L[R[c]]=L[c]; R[L[c]]=R[c];
FOR(i,D,c)
FOR(j,R,i) { U[D[j]]=U[j]; D[U[j]]=D[j]; S[col[j]]--; }
}
void Restore(int c)
{
FOR(i,U,c)
FOR(j,L,i) { S[col[j]]++; U[D[j]]=j; D[U[j]]=j; }
L[R[c]]=c; R[L[c]]=c;
}
//d为递归深度
bool DFS(int d)
{
if (!R[0]) { ansd=d; return true; } //找到解并记录解的长度
//找S最小的列c
int c=R[0]; //第一个未删除的列
FOR(i,R,0) if (S[i]//删除第c列
FOR(i,D,c) //用节点i所在行覆盖第c列
{
ans[d]=row[i];
FOR(j,R,i) Remove(col[j]); //删除节点i所在行能覆盖的所有其他列
if (DFS(d+1)) return true;
FOR(j,L,i) Restore(col[j]);//恢复节点i所在行能覆盖的所有其他列
}
Restore(c);//恢复第c列
}
bool Solve(vector<int>& v)
{
v.clear();
if (!DFS(0)) return false;
for (int i=0; ireturn true;
}
};