最长回文子串Manacher算法讲解
写在前面:这是一篇写的很好的博客,排版很好,转载用来学习,有些地方做了一点补充
原博客链接:最长回文子串(Manacher算法)
Manacher算法求最长回文子串
给定一个字符串,求它的最长回文子串,例如"1232231"的最长回文子串为"3223"。用Manacher算法可以在O(N)时间内得到结果。
— 目录 —
- Manacher算法求最长回文子串
- 1 题目描述
- 2 分析解法
- 普通解法
- 改进
- 3算法思路
- Manacher算法思路
- 4 具体过程
- Manacher算法过程
- 5 实例代码
1> 题目描述
给定一个长度小于100的字符串,求它的最长回文子串的长度
样例输入:
12212321样例输出
6
2> 分析解法
普通解法
通常情况下我们会想到的方法是:遍历字符串的各个字符,然后对每一个字符找到以它为中心的最长回文串,遍历结束后再将得到的最大串长输出即可。
不难得出,上述方法的时间复杂度为 O(N2)O(N2) ,而且对于"中心位置"这个概念还要分两种情况:
- 例如对字符串
S,此时遍历到的某个字符a:
a对应的回文子串长度为奇数,形如BaB;
a对应的回文子串长度为偶数,形如BaaB;
因此该算法是不太合理的,但是对于 "中心位置" 需要分奇偶情况的问题,我们可以有很好的办法来解决。
改进
为了解决奇偶问题,首先在每个字符的两边插入一个特殊符号 '#',同时为了方便在代码中处理数组越界问题,在插入后的字符串最左边增加起始符号 '$' 。
例如,字符串
"abcdefg"经过插入预处理后就变成了"$ # a # b # c # d # e # f # g #"。
这样做的好处是,将所有可能的回文子串不论是奇数长度还是偶数长度,都转化为了奇数长度统一处理。
继续分析,在遍历每个字符时,第 j 个字符对应的回文串与第 i (0 ≤ i < j) 个字符对应的回文串之间会不会存在某种关系? 从而降低时间复杂度?
如下图 2-1 所示, i 代表:从左到右遍历字符串时某时刻的字符位置, id 代表:此时最大回文子串的中心, mx 代表:当前得到的最大回文子串的右边界, j 代表:i 关于 id 的对称点,
图中的大括号分别代表以id 、i 、j 为中心的最长回文串。
图 2-1

假设 P[i] 代表以 i 为中心的最长回文串的长度,
那么根据图 2-1 当mx>i时,在mx范围内一定有P[i] <= P[j] 。此时初始化p[i]=min( p[j] , mx-i );
如果 i 的右边界大于 mx 呢? 很明显初始化p[i]=1(自己本身);
如图 2-2 所示,
此时由于 j 的左边部分延伸到 mx的对称点 左边去了, 所以仅能由虚线部分推测出 P[i] ≥ mx - i 。
至于 P[i] 的值具体是多少,就需要在虚线框的两侧进行两两比较,如果相同,那么 P[i] ++。
图 2-2

3>算法思路
Manacher算法思路
Manacher 算法的核心思想就是前面讲到的 插入特殊字符转化为奇数处理 和 P[i] >= MIN(P[j], mx - i),
正是由于Manacher算法采取这种思想后,减少了对于每个字符的左右比较次数,使时间复杂度降低到O(N)O(N),空间复杂度仍为O(N)O(N)不变。
4> 具体过程
Manacher算法过程
下面以S[i] = “1211”为例,演示Manacher算法的具体过程。
第一步、填充 S[] 为 “$#1#2#1#1#”; 另外再创建数组 P[] ,代表对应字符的最长回文串长度,初始均为0; 定义 id 为最大回文子串的中心; 定义 mx 为最大回文子串的右边界; i 为当前遍历到 S[] 数组的位置 (从 i = 1 开始)。为了方便理解,可以创建如图 4-1所示的表:
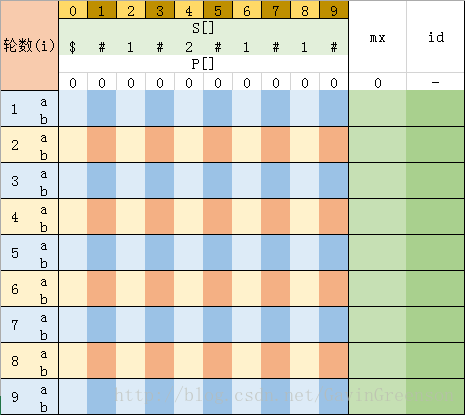
图 4-1
如图所示,每一轮包括a、b两个步骤,
a 步骤根据mx和i的关系确定P[i]的值 (上面图2-1,2-2已讲解)
b 步骤继续更新P[i]的值,然后根据当前新的最长回文串的位置更新mx和id的值// 继续更新P[i] while (S[i + P[i]] == S[i - P[i]]) { P[i]++; } // 如果最大回文子串的位置发生改变,则需要更新 id 和 mx if (P[i] + i > mx) { mx = P[i] + i; // 右边界 id = i; // 中心位置 }
第二步、i = 1 :
a -> 先让 P[0] = 1,因为 mx <= i, 所以 P[i] = 1;
b -> 根据如下代码继续更新 P[i]; 因为 P[i] + i > mx , 即当前最大回文串的位置发生了变化, 所以 mx = P[i] + i、id = i。第二步结束后,表格如图 4-2所示。
while (S[i + P[i]] == S[i - P[i]])
{
P[i]++;
}- 1
- 2
- 3
- 4
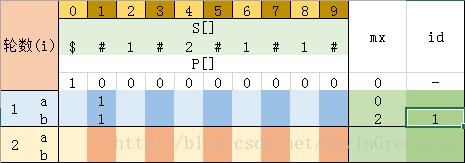
图 4-2
第三步、重复上述步骤,每一次变化结果如下各图所示:
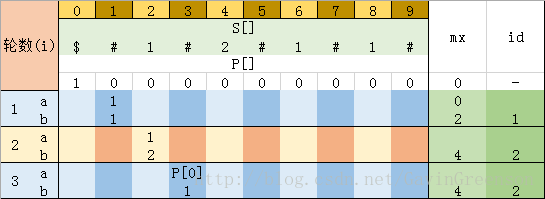
图 4-3 当i = 3时
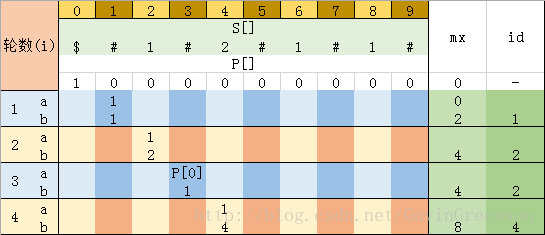
图 4-4 当i = 4时

图 4-5 当i = 5时

图 4-6 当i = 9时
如图4-6所示,P[i]最大值为 4, 所以S[i]的最长回文子串长度
为 4×2−1=74×2−1=7, 所以原字符串"1211"的最长回文子串长度为 (7−1)÷2=3(7−1)÷2=3。
5> 实例代码
以下是算法伪代码
// S[]为已经插入特殊字符后的数组
void Manacher(int S[])
{
int mx = 0; // 最大回文子串的右边界
int id; // 最大回文子串的中心
for (int i = 1; i < n; i++)
{
// mx > i 时,P[i] 先取 P[j](即P[2 * id - i]) 与 mx - i 中的较小值
if (mx > i)
{
P[i] = MIN{P[j], mx - i}
}
else // mx <= i时, 先让P[i] = 1
{
P[i] = 1;
}
// a步结束,开始b步
// 继续更新P[i]
while (S[i + P[i]] == S[i - P[i]])
{
P[i]++;
}
// 如果最大回文子串的位置发生改变,则需要更新 id 和 mx
if (P[i] + i > mx)
{
mx = P[i] + i; // 右边界
id = i; // 中心位置
}
}
return;
}