Tensorflow学习文档【待更新】
本文部分参考
https://morvanzhou.github.io/
https://www.bilibili.com/video/av9156347/?from=search&seid=14443754263386295565
如何安装?
win10-x64下cpu版本
1.下载安装python3.6勾选ADD环境变量。(此安装包自带numpy与pip)
2.cmd输入pip install tensorflow等待安装完成
3.import tensorflow as tf没有报错则成功
4.安装一些工具包(通过cmd) pip install matplotlib
#===============================忽略烦人的警告===============================
#在使用tensorflow时可能会输出一些无用警告,以下可以屏蔽
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' #忽略烦人的警告
#===============================网络计算&可视化网络===============================
#tensorflow是先构成网络的连接方式、运算方式,再进行运算(run),要使用内置方法如tf.add
#tf有自己的可视化工具,用name命名方便可视化查看
import tensorflow as tf
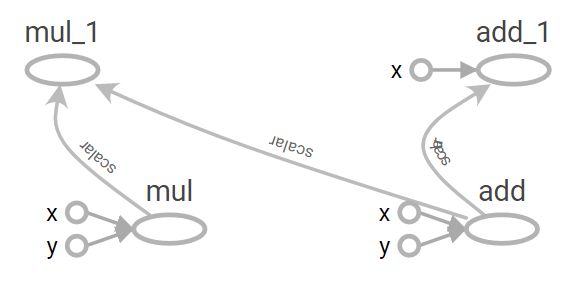
x=tf.constant(2,name='x')#常量
y=tf.constant(3,name='y')
op1=tf.add(x,y,name='add')
op2=tf.multiply(x,y,name='mul')
op3=tf.multiply(op1,op2,name='mul')
op4=tf.add(op1,x,name='add')
sess=tf.Session()#这一步是生成网络
writer=tf.summary.FileWriter('./graphs',sess.graph)#在./graphs路径中保存可视化文件(网络可视化)
op3,op4=sess.run([op3,op4])#可以通过run得到任何结点的输出
print('op3:',op3)
print('op4:',op4)
writer.close()
sess.close()
#####################################################################
# 然后调出终端,先cd到graphs上一个目录,注意!不要有中文目录
# cd C:\Users\xytpai\Desktop\ML
# 然后到终端输入
# tensorboard --logdir=graphs --port 6006 --host=127.0.0.1
# chrome浏览器打开
# http://localhost:6006/
#####################################################################
#===============================运行多个模型===============================
#运行期间不能交互,若是gpu则独占整个GPU资源
import tensorflow as tf
g=tf.Graph()#定义一个图g
with g.as_default():#把g设置为默认图(图也就是网络)
x=tf.add(3,5)#现在这个操作在图g之上的
with tf.Session(graph=g)as sess:#选定图g生成网络
print(sess.run(x))#x结点输出
#如果要获取当前图g=tf.get_default_graph()#===============================在运行图的时候插入一些图===============================
#当直接在python语言环境交互式输出命令时,也可以边插入图边查看效果,而不用Session
tf.InteractiveSession()
a=tf.constant(2,shape=[2,2])#定义a的向量形状
a.eval()#显示向量数据#===============================多维输入的节点===============================
import tensorflow as tf
a=tf.constant([2,2])#a为仅有一行的常数向量
b=tf.constant([[0,1],[2,3]])#b为2行2列的常数矩阵
x=tf.add(a,b)#a中那一行与b中各行相加,tf自带一些矩阵向量的计算方式
y=tf.multiply(a,b)#把b中每个向量与a乘
with tf.Session() as sess:#生成网络
x,y=sess.run([x,y])#run一下才能得到结果
print(x)
print(y)#===============================零矩阵或者一矩阵===============================
#注意!以下返回的a\b\c\d\e为tf的网格数据结构tensor,相当于构成网格的组件
#只有run了才能得到值
import tensorflow as tf
a=tf.zeros([2,3],tf.int32) #->[[0,0,0],[0,0,0]]
b=tf.zeros_like(a) #->与a类似形状的0矩阵
c=tf.ones([2,3],tf.int32)
d=tf.ones_like(c)
e=tf.fill([2,3],8) #->[[8,8,8],[8,8,8]]用自定义值填充的矩阵#===============================一维线性回归===============================
import numpy as np
import time
import matplotlib.pyplot as plt
import tensorflow as tf
x_data=np.random.rand(100).astype(np.float32)#创造一些data作为对应输入
y_data=x_data*0.1+0.3#自己随便搞一点对应输出
Weight=tf.Variable(tf.random_uniform([1],-1.0,1.0))#1维的结构,初始为-1~1的均匀分布随机值
biases=tf.Variable(tf.zeros([1]))#偏置直接给0,这里Variable为变量
y=Weight*x_data+biases#y即为预测值
loss=tf.reduce_mean(tf.square(y-y_data))#损失函数为平方,训练目的就是把loss变小
train=tf.train.GradientDescentOptimizer(0.5).minimize(loss)#梯度下降优化器,学习速率0.5
init=tf.global_variables_initializer()#初始化变量结构,只要有tf.Variable就一定要加入
sess=tf.Session()
sess.run(init)#必须先run这个!
for step in range(200):#训练200次
sess.run(train)#这里就是训练
if step%20==0:#每隔一定训练次数输出
print(step,sess.run(loss),sess.run(Weight),sess.run(biases))#用run来获取特定结点的值
#可以从结果中看到,loss越来越小,机器学得越来越好了
sess.close()#===============================计算矩阵乘法===============================
import tensorflow as tf
matrix1=tf.constant([[3,3]])#一行两列,常数矩阵
matrix2=tf.constant([[2],[2]])#一列两行,常数矩阵
product=tf.matmul(matrix1,matrix2)#矩阵乘法
sess=tf.Session()
result=sess.run(product)
print(result)
sess.close()#===============================变量用法与计数器应用===============================
import tensorflow as tf
state=tf.Variable(0)#state为变量,初始值为0
one=tf.constant(1)#常量1
new_value=tf.add(state,one)#相当于增加了一个双输入节点,输入为state+one其中state为变量
update=tf.assign(state,new_value)#赋值节点把new_value加载到state
init=tf.global_variables_initializer()#初始化<变量>结构Variable必须定义采用
with tf.Session() as sess:
sess.run(init)#这个init必须先run一下
for _ in range(10):
sess.run(update)#先run到update节点把new_value节点得到的值给state变量
print(sess.run(state))#再看下state的输出#===============================一维输入输出神经网络===============================
import numpy as np
import time
import matplotlib.pyplot as plt
import tensorflow as tf
#一个添加神经层的函数
def add_layer(inputs,in_size,out_size,activation_function=None):
Weights=tf.Variable(tf.random_normal([in_size,out_size]))#矩阵变量,先用正态分布初始化
biases=tf.Variable(tf.zeros([1,out_size])+0.1)#推荐不为0
Wx_plus_b=tf.add(tf.matmul(inputs,Weights),biases)
if activation_function is None:
outputs=Wx_plus_b#线性关系
else:
outputs=activation_function(Wx_plus_b)
return outputs
#先自己建造一个数据集(样本+标签), -1到1之间300个单位
x_data=np.linspace(-1,1,300)[:,np.newaxis]#300行
noise=np.random.normal(0,0.05,x_data.shape)#加点噪点,格式根x_data一样
y_data=np.square(x_data)-0.5+noise#一元二次函数加点噪声
#添加输入量
xs=tf.placeholder(tf.float32,[None,1])#None表示第一维无论多少个例子都ok
ys=tf.placeholder(tf.float32,[None,1])
#添加神经层,1隐含层+1输出层
l1=add_layer(xs,1,10,activation_function=tf.nn.relu)#隐含层,10个输出
prediction=add_layer(l1,10,1,activation_function=None)#输出层,输出1维度
#添加损失函数与训练方式
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),#平方损失函数,所有求和取平均
reduction_indices=[1]))#[1]为按列求和
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#初始化所有变量开始训练
init=tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
#可视化
fig=plt.figure()#创造一个框框
ax=fig.add_subplot(1,1,1)#1,1,1为编号
ax.scatter(x_data,y_data)#打入点
plt.ion()#显示出真实数据,不暂停
#plt.show()#显示出真实数据,然后暂停
for i in range(1000):#训练次数1000
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})#全部数据运算,这一步是学习
if i%50==0:
#可视化
try:
ax.lines.remove(lines[0])#抹除掉刚画的线
except Exception:
pass
prediction_value=sess.run(prediction,feed_dict={xs:x_data})#得到预测值
lines=ax.plot(x_data,prediction_value,'r-',lw=5)#画线并显示,红色,宽度为5
plt.pause(0.1)#暂停一下继续
print(sess.run(loss,feed_dict={xs:x_data,ys:y_data}))
sess.close()#===============================TensorBoard可视化训练调参===============================
#一个添加神经层的函数
def add_layer(inputs,in_size,out_size,n_layer,activation_function=None):
layer_name='layer%s'%n_layer#传入名字
with tf.name_scope(layer_name): #做个可视化大框架
#矩阵变量,先用正态分布初始化
with tf.name_scope('weights'): #可视化小部件
Weights=tf.Variable(tf.random_normal([in_size,out_size]),name='W')
tf.summary.histogram(layer_name+'/weights',Weights)#想要观看的变量
with tf.name_scope('biases'): #可视化小部件
biases=tf.Variable(tf.zeros([1,out_size])+0.1,name='b')#推荐不为0
tf.summary.histogram(layer_name+'/biases',biases)#想要观看的变量
with tf.name_scope('Wx_plus_b'): #可视化小部件
Wx_plus_b=tf.add(tf.matmul(inputs,Weights),biases)
if activation_function is None:
outputs=Wx_plus_b#线性关系
else:
outputs=activation_function(Wx_plus_b)
tf.summary.histogram(layer_name+'/outputs',outputs)#想要观看的变量
return outputs
#先自己建造一个数据集(样本+标签), -1到1之间300个单位
x_data=np.linspace(-1,1,300)[:,np.newaxis]#300行
noise=np.random.normal(0,0.05,x_data.shape)#加点噪点,格式根x_data一样
y_data=np.square(x_data)-0.5+noise#一元二次函数加点噪声
#添加输入量
with tf.name_scope('inputs'): #做个可视化大框架
xs=tf.placeholder(tf.float32,[None,1],name='x_input')#None表示第一维无论多少个例子都ok
ys=tf.placeholder(tf.float32,[None,1],name='y_input')
#添加神经层,1隐含层+1输出层
l1=add_layer(xs,1,10,n_layer=1,activation_function=tf.nn.relu)#隐含层,10个输出
prediction=add_layer(l1,10,1,n_layer=2,activation_function=None)#输出层,输出1维度
#添加损失函数与训练方式
with tf.name_scope('loss'): #做个可视化大框架
loss=tf.reduce_mean(tf.reduce_sum(tf.square(ys-prediction),#平方损失函数,所有求和取平均
reduction_indices=[1]))#[1]为按列求和
tf.summary.scalar('loss',loss)#想要观看的变量,注意loss是纯量在TensorBoard里的event里看
with tf.name_scope('train'): #做个可视化大框架
train_step=tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess=tf.Session()
merged=tf.summary.merge_all()#重要!合并所有的summary
writer=tf.summary.FileWriter('./graphs',sess.graph)#这个只是画图
sess.run(tf.global_variables_initializer())#有变量必须这步
for i in range(1000):#训练次数1000
sess.run(train_step,feed_dict={xs:x_data,ys:y_data})#全部数据运算,这一步是学习
if i%50==0:
#可视化
result=sess.run(merged,feed_dict={xs:x_data,ys:y_data})#run merged!!!
writer.add_summary(result,i)#写入summary
writer.close()
sess.close()
#####################################################################
# 然后调出终端,先cd到graphs上一个目录,注意!不要有中文目录
# cd C:\Users\xytpai\Desktop\ML
# 然后到终端输入
# tensorboard --logdir=graphs --port 6006 --host=127.0.0.1
# chrome浏览器打开
# http://localhost:6006/
#####################################################################
#===============================单层神经网络训练手写识别===============================
首先创建一个文件放在与主文件相同目录下命名为input_data.py内容如下
"""Functions for downloading and reading MNIST data."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
该程序会自动从互联网得到MINIST库并加载
#-------------------------------------主程序-------------------------------------
#若电脑上无数据包网上可以下下来
import tensorflow as tf
import input_data
mnist=input_data.read_data_sets('/data/mnist',one_hot=True)
#一个添加神经层的函数
def add_layer(inputs,in_size,out_size,activation_function=None):
#矩阵变量,先用正态分布初始化
Weights=tf.Variable(tf.random_normal([in_size,out_size]))
biases=tf.Variable(tf.zeros([1,out_size])+0.1)#推荐不为0
Wx_plus_b=tf.add(tf.matmul(inputs,Weights),biases)
if activation_function is None:
outputs=Wx_plus_b#线性关系
else:
outputs=activation_function(Wx_plus_b)
return outputs
def compute_accuracy(v_xs,v_ys):
global prediction#申明全局变量
y_pre=sess.run(prediction,feed_dict={xs:v_xs})
#判断是否等,argmax为最大概率的索引
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))
#tf.cast为转化格式
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys})
return result
#define placeholder for inputs to network
xs=tf.placeholder(tf.float32,[None,784])#784个像素点28*28
ys=tf.placeholder(tf.float32,[None,10])#None为这个维度输入待定
#add output layer
prediction=add_layer(xs,784,10,activation_function=tf.nn.softmax)
#loss
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1]))#分类一般用交叉熵
train_step=tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(100)#每次学习100个d
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys})
if i%50==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
sess.close()#===============================过拟合===============================
方法一:增加数据量
方法二:正则化 L1 cost = (Wx-real y)^2 + abs(W) 增加惩罚因子
L2 abs(W)转化为W^2
方法三:训练时随机忽略一些节点变成一个不完整的神经网络,使每一次的预测结果都不会特别依赖某些特定的节点(以下)
先定义keep_prob=tf.placeholder(tf.float32)
再在这里改sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys,keep_prob:0.6})#训练时百分之60不被drop掉
主功能加在如下
def add_layer(inputs,in_size,out_size,activation_function=None):
#矩阵变量,先用正态分布初始化
Weights=tf.Variable(tf.random_normal([in_size,out_size]))
biases=tf.Variable(tf.zeros([1,out_size])+0.1)#推荐不为0
Wx_plus_b=tf.add(tf.matmul(inputs,Weights),biases)
#加这里
Wx_plus_b=tf.nn.dropout(Wx_plus_b,keep_prob)
#======
...#===============================卷积神经网络训练手写识别===============================
import tensorflow as tf
import input_data
mnist=input_data.read_data_sets('/data/mnist',one_hot=True)
def compute_accuracy(v_xs,v_ys):
global prediction#申明全局变量
y_pre=sess.run(prediction,feed_dict={xs:v_xs,keep_prob:1})
#判断是否等,argmax为最大概率的索引
correct_prediction=tf.equal(tf.argmax(y_pre,1),tf.argmax(v_ys,1))
#tf.cast为转化格式
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
result=sess.run(accuracy,feed_dict={xs:v_xs,ys:v_ys,keep_prob:1})
return result
def weight_variable(shape):
initial=tf.random_normal(shape=shape,stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
def conv2d(x,W):
#strides等于采样步长,中间两个1表示xy方向步长都为1,第一个和最后一个恒为1
#SAME为抽取出来长宽与原图一样卷积时包含边界之外的像素,边界以外全0填充
#若padding为VALID则无边界之外的像素
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME')
def max_pool_2x2(x):
#池化层过滤器边长为2移动步长为2,采用全0填充(SAME)
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
xs=tf.placeholder(tf.float32,[None,784])#784个像素点28*28
ys=tf.placeholder(tf.float32,[None,10])#None为这个维度输入待定
keep_prob=tf.placeholder(tf.float32)
x_image=tf.reshape(xs,shape=[-1,28,28,1])#最后一个是色彩深度,-1与None一样
#卷积+池化层1
W_conv1=weight_variable([5,5,1,32])#patch 5*5输入深度为1,输出深度为32,即32个卷积核
b_conv1=bias_variable([32])
h_conv1=tf.nn.relu(tf.add(conv2d(x_image,W_conv1),b_conv1))#output:28*28*32
h_pool1=max_pool_2x2(h_conv1)#output:14*14*32
#卷积+池化层2
W_conv2=weight_variable([5,5,32,64])#前一次输出深度为32因此这次输入深度为32,输出深度64
b_conv2=bias_variable([64])
h_conv2=tf.nn.relu(tf.add(conv2d(h_pool1,W_conv2),b_conv2))#output:14*14*64
h_pool2=max_pool_2x2(h_conv2)#output:7*7*64
#全连接隐层
W_fc1=weight_variable([7*7*64,1024])
b_fc1=bias_variable([1024])
h_pool2_flat=tf.reshape(h_pool2,shape=[-1,7*7*64])
h_fc1=tf.nn.relu(tf.add(tf.matmul(h_pool2_flat,W_fc1),b_fc1))
f_fc1_drop=tf.nn.dropout(h_fc1,keep_prob)
#输出层
W_fc2=weight_variable([1024,10])
b_fc2=bias_variable([10])
prediction=tf.nn.softmax(tf.add(tf.matmul(f_fc1_drop,W_fc2),b_fc2))
#loss+train
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),
reduction_indices=[1]))#分类一般用交叉熵
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_xs,batch_ys=mnist.train.next_batch(100)#每次学习100个d
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys,keep_prob:0.8})
if i%50==0:
print(compute_accuracy(mnist.test.images,mnist.test.labels))
sess.close()#===============================保存和提取===============================
保存
W=tf.Variable([[1,2,3],[3,4,5]],dtype=tf.float32,name='weights')
b=tf.Variable([[1,2,3]],dtype=tf.float32,name='weights')
init=tf.global_variables_initializer()
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
save_path=saver.save(sess,"my_net/save_net.ckpt")
print(save_path)
提取
W=tf.Variable(tf.zeros([2,3],tf.float32),dtype=tf.float32,name="weights")
b=tf.Variable(tf.zeros([1,3],tf.float32),dtype=tf.float32,name="weights")
saver=tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,"my_net/save_net.ckpt")
print("weights:",sess.run(W))
print("biases:",sess.run(b))