centous7下spark的安装配置及提交模式
一、安装spark依赖的scala
1、下载和解压缩Scala
下载链接:http://www.scala-lang.org/
[hadoop@h3 software]$ tar -zxvf scala-2.12.6.tgz -C /opt/modules/
2、配置环境变量
[hadoop@h3 scala-2.12.6]$ sudo vim /etc/profile
添加:
export SCALA_HOME=/opt/modules/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
[hadoop@h3 scala-2.12.6]$ source /etc/profile
3、验证Scala
scala -version
![]()
二、安装spark
1、下载解压缩
下载链接地址:http://spark.apache.org/downloads.html
[hadoop@h3 software]$ tar -xzf spark-2.1.0-bin-hadoop2.7.tgz -C /opt/modules/
2、spark相关环境配置
配置环境变量:
[hadoop@h3 modules]$ sudo vim /etc/profile
添加:
export SPARK_HOME=/opt/modules/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
[hadoop@h3 modules]$ source /etc/profile
配置spark-env.sh文件
[hadoop@h3 spark-2.3.1-bin-hadoop2.7]$ cd conf/
[hadoop@h3 conf]$ ls
docker.properties.template log4j.properties.template slaves.template
fairscheduler.xml.template metrics.properties.template spark-defaults.conf.template
[hadoop@h3 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@h3 conf]$ sudo vim spark-env.sh

配置slaves文件
[hadoop@h3 conf]$ cp slaves.template slaves
[hadoop@h3 conf]$ sudo vim slaves
h1
h2
h3
分发scala和spark到其他节点:
[hadoop@h3 modules]$ scp -r spark-2.1.0-bin-hadoop2.7/ [email protected]:/opt/modules/
[hadoop@h3 modules]$ scp -r spark-2.1.0-bin-hadoop2.7/ [email protected]:/opt/modules/
[hadoop@h3 modules]$ scp -r scala-2.12.6/ [email protected]:/opt/modules/
[hadoop@h3 modules]$ scp -r scala-2.12.6/ [email protected]:/opt/modules/
3、启动spark集群
启动spark
因为spark是依赖于hadoop提供的分布式文件系统的,所以在启动spark之前,先确保hadoop在正常运行。

注意:上面的命令中有./这个不能少,./的意思是执行当前目录下的start-all.sh脚本。
测试spark集群:访问spark集群提供的url
在浏览器里访问Master机器,我的Spark集群里Master机器是h3,IP地址是192.168.113.113,访问8080端口,URL是:http://192.168.113.113:8080/

不同模式运行spark自带的计算圆周率的Demo
local模式也就是本地模式,即在本地机器上单机执行程序。此模式无需启动集群,主要有一台机器上安装了JDKScala、 Spark即可。
-
单机local模式提交任务
[hadoop@h3 jars]$ pwd
/opt/modules/spark-2.1.0-bin-hadoop2.7/examples/jars
[hadoop@h3 jars]$ spark-submit --class org.apache.spark.examples.SparkPi --master local spark-examples_2.11-2.3.1.jar


-
独立的spark集群提交任务
Standalone模式,使用独立的Spark集群模式提交任务,需要先启动Spark集群,但无需启动Hadoop集群。
[hadoop@h3 spark-2.1.0-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.113.113:7077 examples/jars/spark-examples_2.11-2.3.1.jar
-
使用spark集群+hadoop集群模式提交任务
On-Yarn模式,主要包括yarn-Client和yarn-Cluster两种模式。在这种模式下提交任务,需要先启动Hadoop集群,然后在启动Spark集群。
用yarn-Client模式执行计算程序
[hadoop@h3 spark-2.1.0-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.3.1.jar
报如下错误:

上面显示 Yarn application has already ended
猜测可能是由于Java 8与Hapdoop 2.7.0的Yarn存在某些不兼容,造成内存的溢出,导致程序异常终止。
解决:修改 yarn-site.xml文件并重启集群
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
再次提交任务:
[hadoop@h3 spark-2.1.0-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.3.1.jar
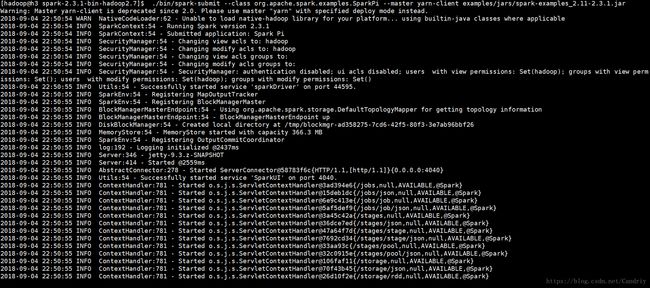


如上显示提交成功。
用yarn-cluster模式执行计算程序:
[hadoop@h3 spark-2.1.0-bin-hadoop2.7]$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client examples/jars/spark-examples_2.11-2.3.1.jar

上面均只显示部分结果。
注意,使用yarn-cluster模式计算,结果没有输出在控制台,结果写在了Hadoop集群的日志中,
结果输出中有地址: tracking URL: http://h2:8088/proxy/application_1536072606449_0002/
直接用浏览器可查看计算结果。

点击logs链接:
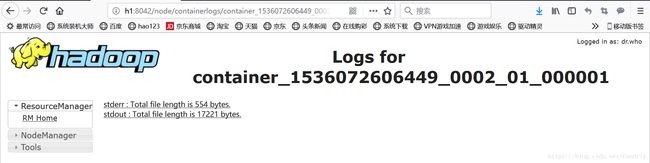
计算结果存放日志:stdout : Total file length is 17221 bytes.
点击打开

yarn-cluster模式的计算结果输出内容。