【代码学习记录】deep-person-reid(Python)(自留)
看deep=person-reid的代码记录:代码链接
虽然之前学过python,但是这一看发现还存在许多知识漏洞,加之一些库的实现也不知道(pytorch(PYTORCH中文官方文档),PIL等等),因此看的速度十分缓慢。特此记录看代码时不懂的地方,以及一些小总结。
加之第一次看工程型的文件集合,程序之间的函数调用关系比较复杂,有些也很隐蔽,因此一遍阅读还不够,还需多读几遍已发现更多的细节,并掌握这种文件集合的阅读方法和写法。
阅读&记录顺序如下:
一开始读的文件为"train_img_model_xent.py",遇到跳转时跳转到相关文件。
记录:
1.from _future_ import print_function
注释:
Python 2.7可以通过 import _future_ 来将2.7版本的print语句移除,让你可以Python3.x的print()功能函数的形式。
2.from future import absolute_import
注释:
在 3.0 以前的旧版本中启用绝对导入等特性所必须的 future 语句。
相对导入:在不指明 package 名的情况下导入自己这个 package 的模块,比如一个 package 下有 a.py 和 b.py 两个文件,在 a.py 里 from . import b 即是相对导入 b.py。
绝对导入:指明顶层 package 名。比如 import a,Python 会在 sys.path里寻找名为 a 的模块。
3.parser = argparse.ArgumentParser(description=‘Train image model with cross entropy loss’)
注释:创建一个解析器对象(外链-命令行选项与参数解析)
4.parser.add_argument(’-a’, ‘–arch’, type=str, default=‘resnet50’, choices=models.get_names())
注释:
add_argument的使用格式(外链-add_argument使用):
ArgumentParser.add_argument(name or flags…[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
Mark几个有必要记录的参数:
type: 使用这个参数,转换输入参数的具体类型,这个参数可以关联到某个自定义的处理函数,这种函数通常用来检查值的范围,以及合法性
choices: 这个参数用来检查输入参数的范围
action:store_true&store_false(Action详细解释): 保存相应的布尔值。这两个动作被用于实现布尔开关。
工作流程:默认的动作是保存参数值。在这种情况下,如果提供一个类型,那么在存储之前会先把该参数值转换成该类型。如果提供 dest 参数,参数值就保存为命令行参数解析时返回的命名空间对象中名为该 dest 参数值的一个属性。
5.__xx 双下划线开头
注释(各种下划线的区别):
双下划线开头,是为了不让子类重写该属性方法.通过类的实例化时自动转换,在类中的双下划线开头的属性方法前加上”_类名”实现.
6.args = parser.parse_args()
parse_args() 的返回值是一个命名空间,包含传递给命令的参数。该对象将参数保存其属性。
7.torch.manual_seed(args.seed)
注释:
为CPU设置种子用于生成随机数,以使得结果是确定的
为GPU设置随机种子:
torch.cuda.manual_seed(args.seed)#为当前GPU设置随机种子;如果使用多个GPU,应该使用torch.cuda.manual_seed_all()为所有的GPU设置种子。
8.os.environ[‘CUDA_VISIBLE_DEVICES’] = args.gpu_devices
注释:
使用哪些GPU。如:命令行中输入–gpu-devices 0,1,2,3.则使用4块GPU编号为0,1,2,3.
9.sys.stdout = Logger(osp.join(args.save_dir, ‘log_train.txt’))
注释:
这一整句的含义是:
组合输入的save_dir路径与’log_train.txt’,用这个组合路径初始化utils文件中的Logger类.然后重定向到这个文件路径.(拿什么传递的文件路径这个参数?)
接下来解释几个操作的含义:
osp.join:将多个路径组合,生成一个路径串.(此处将save_dir(命令行输入的)的路径和’log_train.txt组合’,即最终路径为"save_dir/log_train.txt")
Logger:在文件Utils里.输出命令行中的输出到外部文件中.
sys.stdout:从控制台重定向到文件!重定向后, print 调用的就是文件对象的 write 方法
10.os.path.dirname(filename)
注释:去掉脚本的文件名,返回目录。
11.cudnn.benchmark = True
注释:
补全后torch.backends.cudnn.benchmark= True.在程序刚开始加这条语句可以提升一点训练速度,没什么额外开销。这是一个特殊的flag.(何使需要添加)
12.*与**的区别
注释:
- 加了(*)的变量名会存放所有未命名的变量参数,不能存放dict
- 加了(**)的变量名会存放所有未命名的变量参数
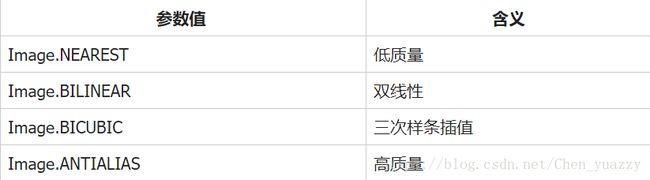
13.Image.BILINEAR
注释:
这是PIL(python image library)库中的一个Image类,作用是:
14.特殊调用函数_call_()
注释:这个特殊的函数写在类中,可以将类的实例当作函数调用.调用方法如下:
Fib已定义好,含有\__call__
>>> f = Fib()
>>> print f(10)
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34]
15.img_paths = glob.glob(osp.join(dir_path, ‘*.jpg’))
注释:
dir_path之前已经join了一次,现在继续join即我们日常的双击图片操作。
glob.glob()函数返回所有匹配的文件路径列表(文件路径,以字符串形式,构成的 list)。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。
在这里,将所有的.jpg图像文件的路径全部返回到img.path里。
16.pattern = re.compile(r’([-\d]+)_c(\d)’)#正则
pid, _ = map(int, pattern.search(img_path).groups())#复杂语句
注释:
·正则表达式compile()函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
这一句正则表达式的功能:
因为数据集文件命名规则如下:"0001_c1s1_001051_00.jpg","0001_c1s1_001051_00.jpg"做如下解释:行人身份_摄像头编号&拍摄到的序列的编号_帧数号_边框号。因此写正则匹配式([-\d]+)_c(\d),匹配并获取行人身份号和摄像头编号,得到的结果为:(行人ID号,摄像机编号)。
·map() 会根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
如下:
>>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
>>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10])
[3, 7, 11, 15, 19]
但在这里,map(int,******)是生成一个列表(因为前面(加粗)正则生成的是元组)
***将元组转换成list***
>>> map(int, (1,2,3))
[1, 2, 3]
***将字符串转换成list***
>>> map(int, '1234')
[1, 2, 3, 4]
***提取字典的key,并将结果存放在一个list中***
>>> map(int, {1:2,2:3,3:4})
[1, 2, 3]
·groups()函数返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。即
·左值pid,_如何解释?
17.Pytorch里的一些函数(Pytorch.torchvision.transforms中的函数)
1.T.RandomHorizontalFlip:以给定的概率水平地翻转给定的PIL图像。在这个代码中,概率值之前已经给定,在transform文件的init时,p=0.5默认值.->2D变换的时候可以修改参数概率p和插值interpolation
2.T.ToTensor:将PIL Image或者numpy.ndarray转换为一个tensor.将一个在 [0, 255]范围内的PIL Image或者numpy.ndarray (H x W x C) 转换成大小为(C x H x W),范围在[0.0, 1.0]内的torch.FloatTensor.
3.T.Normalize:用平均值和标准差归一化张量图像。计算公式为:
input[channel] = (input[channel] - mean[channel]) / std[channel]
4.T.Resize:将输入的PIL图像调整为给定的大小。
5. T.compose:同时将几个转变(transforms)加到同一张图像上。
18.resized_img.crop(a,b,c,d)
注释:
crop是图像裁剪,四个参数为 (left, upper, right, lower)
19.torch.utils.data.dataloader(…)
torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None)
注释:
组合了数据集和取样器,并在数据集上提供单进程或多进程迭代器。

使用时注意:训练时丢弃最后不完整batch,且设置随机打乱。query和gallery不丢弃,也不随机打乱。
注释2:
外链-Dataloader源码解读:
dataloade只调用_init_()函数,只进行初始化,当代码运行到要从torch.utils.data.DataLoader类生成的对象中取数据的时候,比如:
train_data=torch.utils.data.DataLoader(...)
for i, (input, target) in enumerate(train_data):
就会调用DataLoader类的__iter__方法,__iter__方法就一行代码:return DataLoaderIter(self),输入正是DataLoader类的属性。因此当调用__iter__方法的时候就牵扯到另外一个类:DataLoaderIter。
对于这个代码,取数据在train()中。
for batch_idx, (imgs, pids, _) in enumerate(trainloader):
#这个下划线是什么->cmid 相机ID ##在这里,trainloader是一个迭代器,for循环才可以取出。调用__iter__&&__next__函数
返回值是什么?
20._len_()函数,_getitem_()函数
注释:
这两个函数为类中的特殊函数,与_init_()类似。
_len_()函数为返回长度值,直接对实例对象使用len(a)即可得到长度
_getitem_()函数的实例对象(假设为P)就可以这样取值:P[key]。
21.lr_scheduler.StepLR(optimizer, step_size=args.stepsize, gamma=args.gamma)
注释:
这又是pytorch里的函数:
将每一个参数组的学习速率设置初始值为lr,一旦遍历数量达到一定里程碑(milestones),衰减gamma倍.
22.model = nn.DataParallel(model).cuda()
注释:
在模块之间实行数据并行.在正向传递中,模块在每个设备上复制,并且每个副本处理输入的一部分。在反向传递期间,将来自每个副本的梯度累加到原始模块中。批处理的大小应该大于使用的GPU的数量。
23.state_dict = model.module.state_dict()
.state_dict()返回包含模块完整状态的字典。包括参数和持久缓冲(例如运行平均值)。键是对应的参数和缓冲区名称。
24.shutil.copy(fpath, osp.join(osp.dirname(fpath), ‘best_model.pth.tar’))
注释:
功能:复制文件
格式:shutil.copy(‘来源文件’,‘目标地址’)
返回值:复制之后的路径
25.elapsed = str(datetime.timedelta(seconds=elapsed))
注释:
datetime.timedelta得出的是时间间隔.(这里为什么要用,不清楚)
26.torch.utils.AverageMeter()
注释:自定义的AverageMeter类管理一些变量的更新。在初始化的时候就调用的重置方法reset。当调用该类对象的update方法的时候就会进行变量更新,当要读取某个变量的时候,可以通过对象.属性的方式来读取,比如在train函数中的top1.val读取top1准确率。
27.for batch_idx, (imgs, pids, _) in enumerate(trainloader):
注释:enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。格式为enumerate(sequence, [start=0]),可以更改起始下标。如:
>>> seasons = [‘Spring’, ‘Summer’, ‘Fall’, ‘Winter’]
>>> list(enumerate(seasons))
[(0, ‘Spring’), (1, ‘Summer’), (2, ‘Fall’), (3, ‘Winter’)]
_是什么含义?
28.qf = torch.cat(qf, 0)
注释:
[res] torch.cat( [res,] x_1, x_2, [dimension] )
contact两个矩阵x_1&x_2,dimension决定在哪一维度上连接。
若为0,则第0维连接,行数增加
若为1,则第1维连接,列数增加
这里只有一个参数怎么回事??
29.q_pids = np.asarray(q_pids)
注释:numpy.asarray()将输入转化为array数组类型变量。且不copy原数据。而相似的numpy.array()则是copy了一份副本。
30.distmat = torch.pow(qf, 2).sum(dim=1, keepdim=True).expand(m, n) +
torch.pow(gf, 2).sum(dim=1, keepdim=True).expand(n, m).t()
注释:
这一句,是torch.pow得到一个tensor后,再作expand,相当于 qf^2后再在某一维度上求和得到一个tensor,再执行语句torch.tensor.expand。
对于sum的参数(???)
对于expand:
返回tensor的一个新视图,单个维度扩大为更大的尺寸。 tensor也可以扩大为更高维,新增加的维度将附在前面。 扩大tensor不需要分配新内存,只是仅仅新建一个tensor的视图,其中通过将stride设为0,一维将会扩展位更高维。任何一个一维的在不分配新内存情况下可扩展为任意的数值。
eg(啥?):
>>> x = torch.Tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
1 1
1 1
2 2 2 2
3 3 3 3
[torch.FloatTensor of size 3x4]
31.distmat.addmm_(1, -2, qf, gf.t())
注释:
首先:
torch.addmm(beta=1, mat, alpha=1, mat1, mat2, out=None) → Tensor
对矩阵mat1和mat2进行矩阵乘操作。矩阵mat加到最终结果。如果mat1是一个 n×m张量,mat2 是一个 m×p张量,那么out和mat的形状为n×p。 alpha和 beta分别是两个矩阵 mat1@mat2和mat的比例因子,即, out=(beta∗M)+(alpha∗mat1@mat2)
对类型为 FloatTensor 或 DoubleTensor 的输入,betaand alpha必须为实数,否则两个参数须为整数。
addmm_()是addmm()的in-place运算形式(?)
32.self.base = nn.Sequential(*list(resnet50.children())[:-2])
注释:构建一个基础网络容器,连续的模块。
主程序代码注释:
from __future__ import print_function, absolute_import
import os
import sys
import time
import datetime
import argparse
import os.path as osp
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler
import data_manager
from dataset_loader import ImageDataset
import transforms as T
import models
from losses import CrossEntropyLabelSmooth, DeepSupervision
from utils import AverageMeter, Logger, save_checkpoint
from eval_metrics import evaluate
from optimizers import init_optim
#---------------------------------------构建自定义解释器------------------------------------------------#
parser = argparse.ArgumentParser(description='Train image model with cross entropy loss')
# Datasets
parser.add_argument('--root', type=str, default='data', help="root path to data directory")
parser.add_argument('-d', '--dataset', type=str, default='market1501',
choices=data_manager.get_names())#跳转文件data_manager
parser.add_argument('-j', '--workers', default=4, type=int,
help="number of data loading workers (default: 4)")
parser.add_argument('--height', type=int, default=256,
help="height of an image (default: 256)")
parser.add_argument('--width', type=int, default=128,
help="width of an image (default: 128)")
parser.add_argument('--split-id', type=int, default=0, help="split index")
# CUHK03-specific setting
parser.add_argument('--cuhk03-labeled', action='store_true',
help="whether to use labeled images, if false, detected images are used (default: False)")
parser.add_argument('--cuhk03-classic-split', action='store_true',
help="whether to use classic split by Li et al. CVPR'14 (default: False)")
parser.add_argument('--use-metric-cuhk03', action='store_true',
help="whether to use cuhk03-metric (default: False)")
# Optimization options
parser.add_argument('--optim', type=str, default='adam', help="optimization algorithm (see optimizers.py)")
parser.add_argument('--max-epoch', default=60, type=int,
help="maximum epochs to run")
parser.add_argument('--start-epoch', default=0, type=int,
help="manual epoch number (useful on restarts)")
parser.add_argument('--train-batch', default=32, type=int,
help="train batch size")
parser.add_argument('--test-batch', default=32, type=int, help="test batch size")
parser.add_argument('--lr', '--learning-rate', default=0.0003, type=float,
help="initial learning rate")
parser.add_argument('--stepsize', default=20, type=int,
help="stepsize to decay learning rate (>0 means this is enabled)")
parser.add_argument('--gamma', default=0.1, type=float,
help="learning rate decay")
parser.add_argument('--weight-decay', default=5e-04, type=float,
help="weight decay (default: 5e-04)")
# Architecture
parser.add_argument('-a', '--arch', type=str, default='resnet50', choices=models.get_names())#跳转文件models.__init__()(为什么会自动调用__init__)
# Miscs
parser.add_argument('--print-freq', type=int, default=10, help="print frequency")
parser.add_argument('--seed', type=int, default=1, help="manual seed")
parser.add_argument('--resume', type=str, default='', metavar='PATH') #resume是干什么的?
parser.add_argument('--evaluate', action='store_true', help="evaluation only")
parser.add_argument('--eval-step', type=int, default=-1,
help="run evaluation for every N epochs (set to -1 to test after training)")
parser.add_argument('--start-eval', type=int, default=0, help="start to evaluate after specific epoch")
parser.add_argument('--save-dir', type=str, default='log')
parser.add_argument('--use-cpu', action='store_true', help="use cpu")
parser.add_argument('--gpu-devices', default='0', type=str, help='gpu device ids for CUDA_VISIBLE_DEVICES')
args = parser.parse_args()
#它们都只是起到了传递参数的作用,之后可以用args.***传递得到的参数。具体实现还是看代码!
#---------------------------------------构建自定义解释器------------------------------------------------#
def main():
#---------------------------------------设置cpu/gpu------------------------------------------------#
torch.manual_seed(args.seed)
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_devices
use_gpu = torch.cuda.is_available()
if args.use_cpu: use_gpu = False
if not args.evaluate:
sys.stdout = Logger(osp.join(args.save_dir, 'log_train.txt'))#跳转文件util文件
else:
sys.stdout = Logger(osp.join(args.save_dir, 'log_test.txt'))
print("==========\nArgs:{}\n==========".format(args))
#之后的print函数不会打印到控制台上,而是写在log文件里
if use_gpu:
print("Currently using GPU {}".format(args.gpu_devices))
cudnn.benchmark = True
torch.cuda.manual_seed_all(args.seed)
else:
print("Currently using CPU (GPU is highly recommended)")
#---------------------------------------设置cpu/gpu------------------------------------------------#
#---------------------------------------初始化数据集------------------------------------------------#
print("Initializing dataset {}".format(args.dataset))
dataset = data_manager.init_img_dataset(#跳转到文件data_manager
root=args.root, name=args.dataset, split_id=args.split_id,
cuhk03_labeled=args.cuhk03_labeled, cuhk03_classic_split=args.cuhk03_classic_split,##此处有疑问?查看cuhk数据集
)
#dataset.train为三元组(image_path,pid,camid) /dataset.query,dataset.gallary也是
#dataset.num_train_pids为行人id的个数 /dataset.num_query_pids,dataset.num_gallery_pids也是
#---------------------------------------初始化数据集------------------------------------------------#
#---------------------------------------设置图像转变策略------------------------------------------------#
transform_train = T.Compose([
T.Random2DTranslation(args.height, args.width),#这里没有调用call,仅仅是init #这里到底有没有调用call???!!!
T.RandomHorizontalFlip(),#以下函数来自pytorch,from torchvision.transforms import * #注意p=0.5
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),#这些数值是怎么来的?
])
#训练的时候做了2维变换,而测试的时候没有使用2维变换
transform_test = T.Compose([
T.Resize((args.height, args.width)),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
#---------------------------------------设置图像转变策略------------------------------------------------#
#---------------------------------------加载数据集------------------------------------------------#
pin_memory = True if use_gpu else False#何为pin-memory??????????????
#看完后再次理解Dataloader!!!里面是怎么做的?传递过来一个数据集,变换方法,然后呢???????????????
trainloader = DataLoader(
ImageDataset(dataset.train, transform=transform_train),#跳转到文件dataset_loader, ##dataset.train是什么??##已解决
#注意!Imagedataset里面有方法__getitem__()&__len__()
batch_size=args.train_batch, shuffle=True, num_workers=args.workers,
pin_memory=pin_memory, drop_last=True,
)#num_workers?pin_memory?drop_last?
#注:训练时丢弃最后不完整batch,且设置随机打乱。query和gallery不设置打乱,也不丢弃。
queryloader = DataLoader(
ImageDataset(dataset.query, transform=transform_test),#跳转到文件dataset_loader
batch_size=args.test_batch, shuffle=False, num_workers=args.workers,
pin_memory=pin_memory, drop_last=False,
)
galleryloader = DataLoader(
ImageDataset(dataset.gallery, transform=transform_test),#跳转到文件dataset_loader
batch_size=args.test_batch, shuffle=False, num_workers=args.workers,
pin_memory=pin_memory, drop_last=False,
)
#---------------------------------------加载数据集------------------------------------------------#
#---------------------------------------设置网络模型------------------------------------------------#
#(包括LOSS规则和优化器,学习速率lr改变)
print("Initializing model: {}".format(args.arch))
model = models.init_model(name=args.arch, num_classes=dataset.num_train_pids, loss={'xent'}, use_gpu=use_gpu) #loss作为分隔参数(其他情况如何分隔)
#返回是一个网络!model=初始化后的Resnet50
print("Model size: {:.5f}M".format(sum(p.numel() for p in model.parameters())/1000000.0))#parameters在哪?可能在torch.nn李
#p.numel在哪?可能在numpy
criterion = CrossEntropyLabelSmooth(num_classes=dataset.num_train_pids, use_gpu=use_gpu)
optimizer = init_optim(args.optim, model.parameters(), args.lr, args.weight_decay)
if args.stepsize > 0:
scheduler = lr_scheduler.StepLR(optimizer, step_size=args.stepsize, gamma=args.gamma)
#---------------------------------------设置网络模型------------------------------------------------#
#---------------------------------------程序中断检查点处理------------------------------------------------#
start_epoch = args.start_epoch#检查点时需要。
if args.resume:
print("Loading checkpoint from '{}'".format(args.resume))
checkpoint = torch.load(args.resume)#resume是个路径
model.load_state_dict(checkpoint['state_dict'])#load_state_dict是哪里的?
start_epoch = checkpoint['epoch']
#---------------------------------------程序中断检查点处理------------------------------------------------#
if use_gpu:
model = nn.DataParallel(model).cuda()
#---------------------------------------仅评估模型------------------------------------------------#
if args.evaluate:
#只进行评估
print("Evaluate only")
test(model, queryloader, galleryloader, use_gpu)
return#此段跳转还没看!!!!!!!!!!!!!!!!!!!
#---------------------------------------仅评估模型------------------------------------------------#
#---------------------------------------训练模型------------------------------------------------#
start_time = time.time()
train_time = 0
best_rank1 = -np.inf
best_epoch = 0
print("==> Start training")
for epoch in range(start_epoch, args.max_epoch):
start_train_time = time.time()
#++++++++++++++++++++++++++++训练+++++++++++++++++++++++++++#
#####开始调用train训练。第epoch次训练,每一次训练将所有数据训练一次######
train(epoch, model, criterion, optimizer, trainloader, use_gpu)#criterion损失函数
#++++++++++++++++++++++++++++训练+++++++++++++++++++++++++++#
train_time += round(time.time() - start_train_time)
if args.stepsize > 0: scheduler.step()#???文档里已经找不到lr_scheduler.StepLR.step
#++++++++++++++++++++++++++++训练中的测试并得到最优正确率+++++++++++++++++++++++++++#
if (epoch+1) > args.start_eval and args.eval_step > 0 and (epoch+1) % args.eval_step == 0 or (epoch+1) == args.max_epoch:#(epoch大于设置的评估开始值&评估步数>0&到达评估步数)or 到达最大epoch
print("==> Test")
rank1 = test(model, queryloader, galleryloader, use_gpu)
is_best = rank1 > best_rank1
if is_best:
best_rank1 = rank1
best_epoch = epoch + 1
#++++++++++++++++++++++++++++训练中的测试并得到最优正确率+++++++++++++++++++++++++++#
#++++++++++++++++++++++++++++保存参数和检查点+++++++++++++++++++++++++++#
if use_gpu:
state_dict = model.module.state_dict()##保存训练参数(mudule是所有网络的基类?)
else:
state_dict = model.state_dict()#与上面那个的区别?##保存训练参数
save_checkpoint({#这个函数作者自己写的!
'state_dict': state_dict,
'rank1': rank1,
'epoch': epoch,
}, is_best, osp.join(args.save_dir, 'checkpoint_ep' + str(epoch+1) + '.pth.tar'))
#++++++++++++++++++++++++++++保存参数和检查点+++++++++++++++++++++++++++#
print("==> Best Rank-1 {:.1%}, achieved at epoch {}".format(best_rank1, best_epoch))
elapsed = round(time.time() - start_time)#为甚一定要下面两句?
elapsed = str(datetime.timedelta(seconds=elapsed))
train_time = str(datetime.timedelta(seconds=train_time))
print("Finished. Total elapsed time (h:m:s): {}. Training time (h:m:s): {}.".format(elapsed, train_time))
#---------------------------------------训练模型------------------------------------------------#
def train(epoch, model, criterion, optimizer, trainloader, use_gpu):
losses = AverageMeter()
batch_time = AverageMeter()
data_time = AverageMeter()
model.train()#这个是什么train???
end = time.time()
for batch_idx, (imgs, pids, _) in enumerate(trainloader):#这个下划线是什么->cmid 相机ID ##在这里,trainloader是一个迭代器,for循环才可以取出。调用__iter__&&__next__函数
if use_gpu:
imgs, pids = imgs.cuda(), pids.cuda()#pid是什么意思 #行人ID
# measure data loading time
data_time.update(time.time() - end)#update函数来自哪->averagemeter()里有reset,update等,调用
outputs = model(imgs)
if isinstance(outputs, tuple):#为何要if--else??如果输出是元组,第一个;如果不是元组,第二个;俩个计算的区别??
loss = DeepSupervision(criterion, outputs, pids)
else:
loss = criterion(outputs, pids)#此时调用forward..为何? #这里先做一个softmax
#####################################网络工作主要部分#####################################
#O(∩_∩)Ofrom torch import *
optimizer.zero_grad()#pytorch函数,参数置零
loss.backward()#误差反向传播
optimizer.step()#误差反向传播后自动更新参数
#########################################################################################
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
#loss.update是什么函数???下一句发生了啥??
losses.update(loss.item(), pids.size(0))#注意.item,,.size(0)什么用?
if (batch_idx+1) % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'.format(
epoch+1, batch_idx+1, len(trainloader), batch_time=batch_time,
data_time=data_time, loss=losses))
def test(model, queryloader, galleryloader, use_gpu, ranks=[1, 5, 10, 20]):
batch_time = AverageMeter()
model.eval()#eval在哪儿?
#下面with里面,为何要把所有的特征提取出来,再组合成一个n*m的的新矩阵?(也许是向量??)
with torch.no_grad():#不做梯度计算
qf, q_pids, q_camids = [], [], []
for batch_idx, (imgs, pids, camids) in enumerate(queryloader):
if use_gpu: imgs = imgs.cuda()
end = time.time()
features = model(imgs)#如何抽取的特征?
batch_time.update(time.time() - end)
features = features.data.cpu()#这一句又是啥....
qf.append(features)
q_pids.extend(pids)
q_camids.extend(camids)
qf = torch.cat(qf, 0)#0是怎么链接->纵向拼接
q_pids = np.asarray(q_pids)
q_camids = np.asarray(q_camids)
print("Extracted features for query set, obtained {}-by-{} matrix".format(qf.size(0), qf.size(1)))#size(0)返回行数
gf, g_pids, g_camids = [], [], []
end = time.time()
for batch_idx, (imgs, pids, camids) in enumerate(galleryloader):
if use_gpu: imgs = imgs.cuda()
end = time.time()
features = model(imgs)
batch_time.update(time.time() - end)
features = features.data.cpu()
gf.append(features)
g_pids.extend(pids)
g_camids.extend(camids)
gf = torch.cat(gf, 0)
g_pids = np.asarray(g_pids)
g_camids = np.asarray(g_camids)
print("Extracted features for gallery set, obtained {}-by-{} matrix".format(gf.size(0), gf.size(1)))
print("==> BatchTime(s)/BatchSize(img): {:.3f}/{}".format(batch_time.avg, args.test_batch))
m, n = qf.size(0), gf.size(0)
#距离矩阵的求解why?
distmat = torch.pow(qf, 2).sum(dim=1, keepdim=True).expand(m, n) + \
torch.pow(gf, 2).sum(dim=1, keepdim=True).expand(n, m).t()
distmat.addmm_(1, -2, qf, gf.t())#
distmat = distmat.numpy()#torch转numpy
print("Computing CMC and mAP")
cmc, mAP = evaluate(distmat, q_pids, g_pids, q_camids, g_camids, use_metric_cuhk03=args.use_metric_cuhk03)#跳转未看!
print("Results ----------")
print("mAP: {:.1%}".format(mAP))
print("CMC curve")
for r in ranks:
print("Rank-{:<3}: {:.1%}".format(r, cmc[r-1]))
print("------------------")
return cmc[0]
if __name__ == '__main__':
main()