FastDFS原理
原文链接:https://www.cnblogs.com/chiangchou/p/fastdfs.html
1、简介
FastDFS 是一个开源的高性能分布式文件系统(DFS)。 它的主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡。主要解决了海量数据存储问题,特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
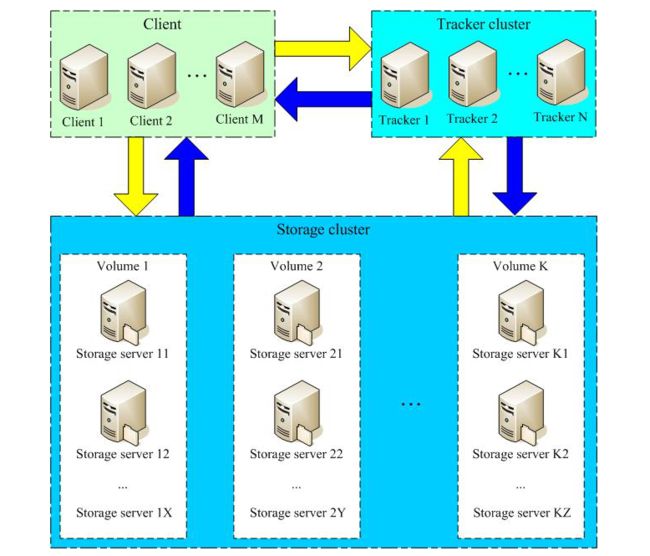
FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。
Storage Server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,数据互为备份。
Client:客户端,上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。
2、FastDFS的存储策略
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
3、FastDFS的上传过程
FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
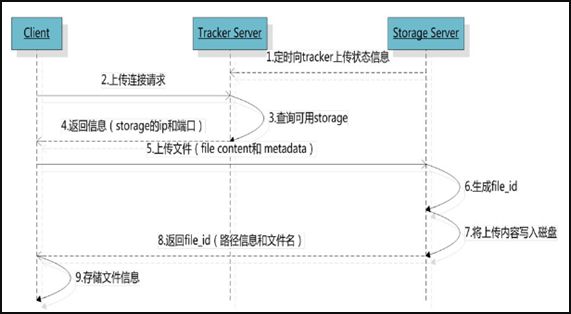
Storage Server会定期的向Tracker Server发送自己的存储信息。当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,所以客户端上传时可以选择任意一个Tracker。
当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。
4、FastDFS的文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
5、FastDFS的文件下载
客户端uploadfile成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
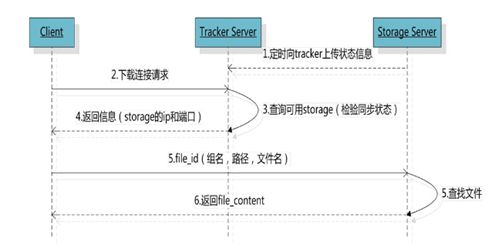
跟upload file一样,在downloadfile时客户端可以选择任意tracker server。tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。