论文解析 - SLAM++: Simultaneous Localisation and Mapping at the Level of Objects
SLAM++: Simultaneous Localisation and Mapping at the Level of Objects
0. 论文概况
引用:331, CVPR2013
Renato F. Salas-Moreno , 来自英国帝国理工学院Andrew J. Davison实验室
带着问题看论文:
如果要我自己来实现这个方案,它既然是基于深度图像来做的,并且在第一帧中提取了地面,那么首先我需要检测到每一个单独的点块,去与数据库中的3D模型一一做ICP,这个过程中获得最后效果最好的种类,并且得到其姿态。
那么如何获得单独的点块?是真的把地面抠掉然后将分离的部分作为一块吗?单帧有可能得到三维物体姿态吗?
假设得到了,那么可以根据现有的相机姿态建立到地图中去,那么现有相机姿态是从何而来?即相对于上一帧的相机姿态变换如何估计得到?既然并非稠密点云地图,那么就没办法用ICP对点云匹配。而且需要保证视野中至少有地图中的一个物体,那么地图为空的时候拿什么去算呢。
这两个问题解决了,就真正理解了这个过程,接下来仔细研究一下,以及背后的数学表达。
1. Introduction
该论文提出的SLAM特点为具备先验知识,先验知识可以重复性地呈现,使得实时3D重建和简单的关于物体位置的图优化地图成为可能。
随着新的测量到达,这个图将不断被优化,同时获得最新、稠密且准确的下一个相机测量的位置的估计。这些估计将被用于鲁棒的相机跟踪和为下一步物体识别做的主动区域搜索。
特点还包括:相比稠密点云地图,对地图存储量做了巨大压缩。而且容易产生大规模回环,重定位和特殊领域先验下使用的巨大潜力。
2. 手持传感器的实时SLAM
介绍了一些related-works
3.方法
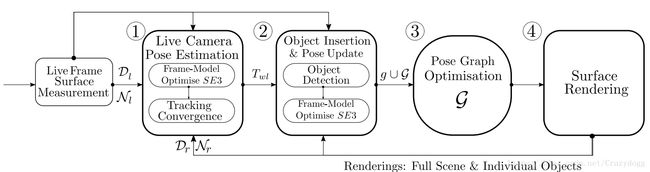
图2. SLAM++架构介绍.
3.1 Creating an Object Database
首先将重复出现的物体通过交互式扫描,使用KinectFusion来建立3D模型。
3.2 SLAM Map Representation
世界呈现用的图模型,每一个节点存放的要么是物体j的姿态(包括相对固定世界参考系的旋转和平移),或者是相机在时间i时的姿态。每一个物体节点给定了一个物体种类,每个物体在相机中的姿态,即测量![]() 作为一个约束因子存储于图中,连接相机姿态和物体姿态。其他因子则可以选择性地添加进图:包括相机之间的运动估计,以及特定种类物体必须在地面上等。
作为一个约束因子存储于图中,连接相机姿态和物体姿态。其他因子则可以选择性地添加进图:包括相机之间的运动估计,以及特定种类物体必须在地面上等。
(地图里面物体的数据结构里用李群来存放物体相对于世界坐标系的位置姿态或者相对于相机某个时间戳时的姿态的相对姿态。)
图优化的详情将在3.5中叙述。
3.3 Real-Time Object Recognition
采用论文[6]中的方法来识别3D物体的6DoF姿态,通过网格表示在深度图像中。
根据论文方法,使用Generalised Hough Transform,投票表决物体的位置。
[ 此处可以重点理解一下如何表示的. ]
该方法中物体被检测到后将同时通过参数空间中票数的积累来被定位。投票基于点对特征关联;物体表面的带朝向点对的相关联位置和向量的四维度描述子。带向量估计的点集基于来自深度相机的双边估计图像而随机采样。这些采样被组成对,产生各种可能来生成PPFs,作为包含相似PPF的6DoF模型配置的票选。
[ 接下来详细介绍了如何物体检测, 这里看得有点晕,回头细看. ]
其实这里所谓的PPFs就是一种描述子,简单来说是将一个点集中的有向点,两两联合行程一个描述子,配备相应的搜素算法。

在GPU中快速生成每个物体网格的全局描述子,通过离散相似的PPFs值,并且储存到适合搜索的数据结构中。
[ 该过程如果要仔细了解可以看论文[6], 而论文的目标为系统论述, 所以如何检测到三维物体的类别和姿态的反而不是重点。可以做一个了解。 ]
该部分仔细参考论文[6] Model Globally, Match Locally: Efficient and Robust 3D Object Recognition
有点小难度,在头脑清醒的时候再仔细研究研究,总之是某种三维匹配方法,可以返回匹配结果。
下面仔细看看这两套列出来的算法:


3.3.1 Active Object Search
论文[6]在遮挡下效果不好,而SLAM++则在该方面有优势。

图3. 该方案可以将图中已经有的部分在观察中去掉。采样将仅仅专注于未被建模的部分。
物体检测结果通常是聚集的多峰,以及量化的定位结果。它们应该被传递到下一个部分介绍的ICP中进行优化。
3.4 Camera Tracking and Accurate Object Pose Estimation using ICP
Camera-Model Tracking: 在KinectFusion的框架下计算当前场景的几何视野,包括深度图像和向量图像,并且将该部分内容渲染到之前估计的帧姿态中,Twr![]() 表现的是李群的6DoF的刚体变换
表现的是李群的6DoF的刚体变换![]() 。
。
迭代最小化整个深度图像的点-平面尺度,基于所有在实时深度图像中的有效像素u:

公式中,
[ 读到这里有些理不清楚头绪了 ]
此处各类公式比较多,而且每个单独的量介绍也不详细,打算将后面看清楚再回来细钻研。
8/25
梳理清楚公式中的数学表达式含义:
首先是下标的含义, l 表示live camera depth image. R 表示
![]() 表示vertex at pixel u. 每一个像素对应了一个顶点吗,如何理解这个映射关系?这个是上一次的顶点(相机姿态)。
表示vertex at pixel u. 每一个像素对应了一个顶点吗,如何理解这个映射关系?这个是上一次的顶点(相机姿态)。
![]() 这个是估计值,通过
这个是估计值,通过![]() 左乘一个
左乘一个![]() ,即r表示增量式的一个相机姿态的更新,于是从上一次得到了这一次的一个姿态,由于是算出来的,带一个估计帽。表示的从t计算t+1的过程。
,即r表示增量式的一个相机姿态的更新,于是从上一次得到了这一次的一个姿态,由于是算出来的,带一个估计帽。表示的从t计算t+1的过程。
![]() 公式告诉如何获得当前帧顶点,即在深度图中像素点的值
公式告诉如何获得当前帧顶点,即在深度图中像素点的值![]()
但是这个神秘的![]() 又是什么含义,取导数?对t求导,还是对深度图里的xy求导得到梯度啊?
又是什么含义,取导数?对t求导,还是对深度图里的xy求导得到梯度啊?
回想起来u只是一个像素坐标(x, y), 它的导数应该指的这个位置的平移吧。那么与一个数值相乘,又代表什么含义?
而且将其从相机视野通过相机内参转化到空间中去,得到![]() ,即当前顶点v(相机姿态)下看到的深度图像u对应像素的相机坐标系下的坐标。
,即当前顶点v(相机姿态)下看到的深度图像u对应像素的相机坐标系下的坐标。
那么同理,![]() 代表的是u’在相机姿态r下的相机坐标系下坐标。
代表的是u’在相机姿态r下的相机坐标系下坐标。
- u’的含义:
 根据上一刻相机姿态和运动关系估计得到的现在相机姿态下像素位置,投影的坐标位置。( 所以运动估计恰当的话,u’和u应该相近)
根据上一刻相机姿态和运动关系估计得到的现在相机姿态下像素位置,投影的坐标位置。( 所以运动估计恰当的话,u’和u应该相近) - 姿态r的含义:
Huber penalty function:
Huber loss是为了增强平方误差损失函数(squared loss function)对噪声(或叫离群点,outliers)的鲁棒性提出的。


即当|x|足够大的时候,用直线来替代二次函数的猛增长。
目前来看总结就是通过相机姿态优化三维重投影深度值。
Tracking Convergence: 这个过程似乎是将预测的3d模型(数据库中),和实时深度图像中做匹配,看重复的体素比例是否超过了某个阈值。
Tracking for model initialization: 考虑到实际中看到的物体经常模糊不清,于是给定单个视角来判断物体类别非常有难度。于是针对检测到的物体姿态使用camera-model的ICP估计,收敛条件与上一个所述相同。我们发现成功检测到的物体,旋转在+-30度内(这可真是大啊),平移在50cm内。这个过程帮助更仔细地设定阈值![]() 并且早一点剔除错误的匹配。
并且早一点剔除错误的匹配。
Camera-Object Pose Constraints: 该过程将所有检测到的模型纳入考虑,一起来优化相机姿态,用的方法仍然是通过ICP。
3.5 图优化
用图优化来估计历史深度相机姿态和静态物体姿态。![]() 表示物体j在帧i中的6DoF测量结果。而
表示物体j在帧i中的6DoF测量结果。而 用Hessian(二次导数?)表示了逆协方差测量( inverse measurement covariance ) 其中J是最后一次物体ICP迭代的雅可比矩阵。
用Hessian(二次导数?)表示了逆协方差测量( inverse measurement covariance ) 其中J是最后一次物体ICP迭代的雅可比矩阵。![]() 则是相机位姿i+1和i之间的ICP约束,
则是相机位姿i+1和i之间的ICP约束,![]() 表示相应的协逆方差。两个Z都是测量,也是约束。所有的变量和测量都有6自由度,而且用SE(3)形式表述。如图5所示。
表示相应的协逆方差。两个Z都是测量,也是约束。所有的变量和测量都有6自由度,而且用SE(3)形式表述。如图5所示。

图5. 表示相机、物体姿态的节点,以及节点之间关系:在某个相机姿态下观测到的物体,相机之间运动的约束。底部的P表示物体的先验。
我们需要最小化该公式,基于所有测量约束:

其中![]() 表示的是Mahalanobis距离( 马氏距离) [这里仔细注意下,很常用的距离计算表达],log(*)表示的是SE(3)的log映射。使用Levenberg-Marquardt方法求解最小二乘。使用稀疏的Cholesky求解来解决潜在的向量方程的稀疏性。
表示的是Mahalanobis距离( 马氏距离) [这里仔细注意下,很常用的距离计算表达],log(*)表示的是SE(3)的log映射。使用Levenberg-Marquardt方法求解最小二乘。使用稀疏的Cholesky求解来解决潜在的向量方程的稀疏性。
[ 无论如何整体计算部分需要再仔细斟酌 ]
3.5.1 包含结构先验
加入一个结构平面先验:物体都在一个标准平面上。
地面在初始观测Z1,o1![]() 下就检测出来,其姿态在优化过程中一直保持固定。
下就检测出来,其姿态在优化过程中一直保持固定。
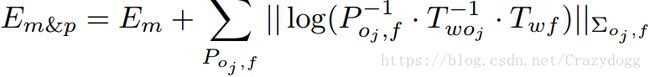
用能量来描述,使用一组单元约束,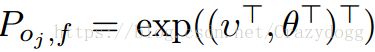 ,其中v,θ∈R3
,其中v,θ∈R3![]()
设定y轴的平移为0,以及旋转绕x和z轴为0即可。即让v2=0, θ1=0, θ3=0![]()
使用下列反转先验协方差:

给定正权重wtrans![]() 和wrot
和wrot![]() ,由于物体可以在平面内任何位置,且和y轴无关,相应权重被设置为0.
,由于物体可以在平面内任何位置,且和y轴无关,相应权重被设置为0.
3.6 其他先验
比如太过于远离地面的可以去掉,在ICP过程中可以根据环境(如厨房、办公室)来影响一些物体的能量。
3.7 重定位
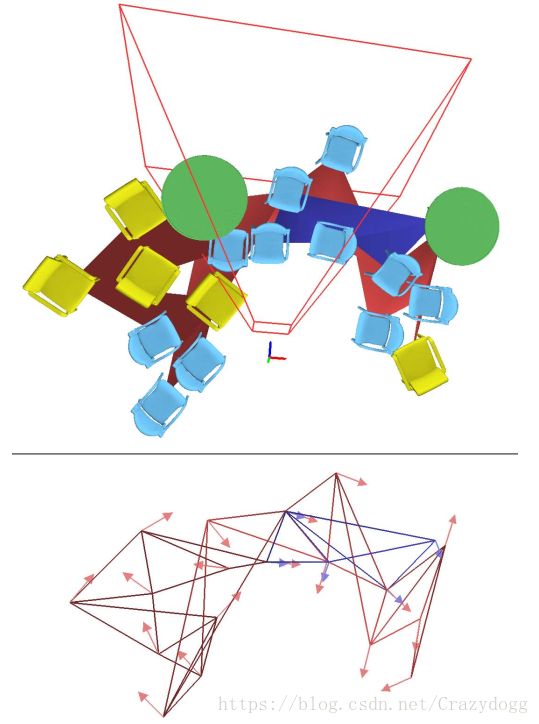
图6. 重定位过程.
当跟踪丢失的时候,一个本地图(蓝色)被创建并且与长期图(红色)进行匹配。(顶部图) 当跟踪重建时候,一些重定位之后包含物体和相机场景的帧。(底部图) 提取出来用于匹配的方向点。 连通关系描述了检测序列,并不被识别过程使用。
重定位的建立使用在长期图中得到投票最多的匹配顶点,而非局部地图中当前观测的顶点。
其中物体识别过程在3.3中描述.
4. 结果
提交的视频比论文更好地证明了算法的结果。
4.1 Loop Closure
小的回环由标准的ICP跟踪机制来封闭。而大型回环则由在主的长期图中被匹配的成分来进行,和3.7节的重定位描述一样。
4.2 Large Scale Mapping
在10min,34个物体的里表现不错。

房间大小:15x10x3m
4.3 Moved Object Detection

图8. 当建图的物体大部分和好的测量(绿色)不一致的时候,被标记为无效(红色),来自于它的观测将被舍去。
4.4 Augmented Reality with Objects

图9. 非常酷炫的虚拟人物坐在实际的椅子上。
4.5 系统数据

图7.
使用游戏本在10x6x3m的房间内测试。比较了SLAM++与KinectFusion.
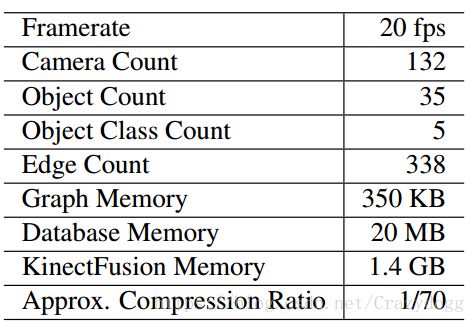
稠密三维建模需要1.4G的存储空间,而这个方法只需要20M,压缩率达到惊人的70.
5 Conclusions and Future Work
目前应用的是公众建筑的内部,包含大量重复而明显的元素。接下来的发展希望能够利用物体低维度形状的差异,或者长期来看,分割和定义它们自己的物体种类。
有一个方向:放弃数据库,自己建立数据库?
[ 2018/8/23 21:00 看完一遍。对于核心算法没有仔细深入了解,接下来再细细梳理。]
之后可以看看有没有SLAM++的进一步研究成果,然后可以考虑将其真正实现一遍。那就很好玩了。(说实现还是太早!一定要专注方向。)
目前细节部分总感觉云里雾里,这是基础未到的原因,还是应该仔细钻研非线性基础,即线性代数部分的修炼。
此外倒是不妨碍继续调研SLAM++的最新情况。