caffe练习
安装anaconda2
开始是用的anaconda3 + python3结果需要改的地方太多,并且一直出现各种坑….
所以换了anaconda2安装起来还算顺利
下载anaconda
https://www.anaconda.com/download/#linux
根据自己电脑的版本下载
打开终端,执行命令
cd Downloads
bash Anaconda2-2.5.0-Linux-x86_64.sh 按提示进行操作,允许将{anaconda2}/lib 和 bin 安装位置写入路径,如果没有自己写入,
sudo vi ~/.bashrc#在文本的最后append
#这里是我的anaconda安装路径,要根据自己的修改
export PATH=/home/cristal/anaconda2/bin:$PATH
export LD_LIBRARY_PATH=/home/cristal/anaconda2/lib:$LD_LIBRARY_PATH保存退出后一定要执行
source ~/.bashrc修改成功.
配置Makefile.config 文件如下,中间省略了没有修改的地方
...
# CPU-only switch (uncomment to build without GPU support).
CPU_ONLY := 1 #将前面的#去掉
...
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/local/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
# ANACONDA_HOME := $(HOME)/anaconda
#ANACONDA_HOME := $(HOME)/anaconda3
#PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
# $(ANACONDA_HOME)/include/python3.6m \
# $(ANACONDA_HOME)/lib/python3.6/site-packages/numpy/core/include
# Uncomment to use Python 3 (default is Python 2)
# PYTHON_LIBRARIES := boost_python3 python3.5m
# PYTHON_INCLUDE := /usr/include/python3.5m \
# /usr/lib/python3.5/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib #默认python2.7
#PYTHON_LIB := $(ANACONDA_HOME)/lib
...
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/lib/x86_64-linux-gnu/hdf5/serial/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib /usr/lib/x86_64-linux-gnu/hdf5/serial #[注]这两个都是加hdf5,不然会出错
...测试:
成功安装anaconda
运行 jupyter notebook
目前可以使用了.
net_surgery
通过修改模型参数可以让网络满足你的个人需求,下面就来学习一下
该例子是通过编辑caffe的模型参数来满足特定的需求
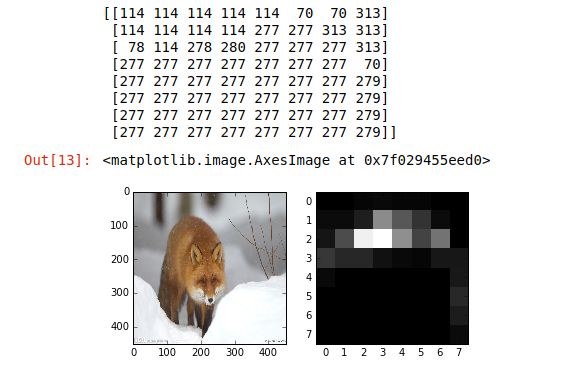
该例子的输出不是对整个图分类概率,而是输出图的每块区域属于哪一类
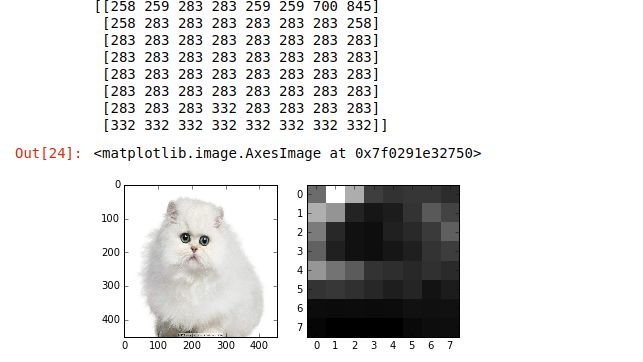
在该例中用451*451的图像作为输入,输出是一个 8 * 8的分类图,图中的数字表示所代表的区域属于那个类别
第一步:写入python包,更改路径
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# Make sure that caffe is on the python path:
caffe_root = '../' # 这里是caffe的根目录,根据个人的修改
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
# configure plotting
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'第二步:设置过滤
为了展示如何载入,操作,保存参数。这里在一个简单的网络中设计我们自己的滤波器,这个网络只有一个卷积层,两个blobs,data是输入数据,conv为卷积输出,参数conv是卷积滤波器的权重和偏移。
# 这里用cpu
caffe.set_mode_cpu()
net = caffe.Net('net_surgery/conv.prototxt', caffe.TEST) #模型文件
print("blobs {}\nparams {}".format(net.blobs.keys(), net.params.keys()))
# 下载图片,设置输入
im = np.array(caffe.io.load_image('images/cat_gray.jpg', color=False)).squeeze() #图片
plt.title("original image")
plt.imshow(im)
plt.axis('off')
im_input = im[np.newaxis, np.newaxis, :, :] #设置输入
net.blobs['data'].reshape(*im_input.shape)
net.blobs['data'].data[...] = im_input输出:
blobs ['data', 'conv']
params ['conv']
可以看一下 模型文件 net_surgery/conv.prototxt
# Simple single-layer network to showcase editing model parameters.
name: "convolution"
#输入层
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 1 dim: 1 dim: 100 dim: 100 } }
}
#卷积层
layer {
name: "conv"
type: "Convolution"
bottom: "data"
top: "conv"
convolution_param {
num_output: 3 #输出
kernel_size: 5
stride: 1
#高斯噪声初始化,偏置初始化为0
weight_filler {
type: "gaussian"
std: 0.01
}
#b初始化
bias_filler {
type: "constant"
value: 0
}
}
}第三步:显示滤波结果
可以得到类似边缘滤波的效果
# helper show filter outputs
def show_filters(net):
net.forward()
plt.figure()
filt_min, filt_max = net.blobs['conv'].data.min(), net.blobs['conv'].data.max()
for i in range(3):
plt.subplot(1,4,i+2)
plt.title("filter #{} output".format(i))
plt.imshow(net.blobs['conv'].data[0, i], vmin=filt_min, vmax=filt_max)
plt.tight_layout()
plt.axis('off')
# filter the image with initial
show_filters(net) 
第四步:提高滤波器的偏置并输出
# pick first filter output
conv0 = net.blobs['conv'].data[0, 0]
print("pre-surgery output mean {:.2f}".format(conv0.mean()))
# 这里设置为1可以试试其他的值
net.params['conv'][1].data[0] = 1.
net.forward()
print("post-surgery output mean {:.2f}".format(conv0.mean()))输出:
pre-surgery output mean -0.02
post-surgery output mean 0.98第五步:更改滤波器
可以使用任意的核如高斯模糊滤波,Sobel边缘算子等等。在下面的改动中,第0个滤波器为高斯模糊滤波,第1个滤波器和第二个滤波器为水平和数值方向的Sobel滤波算子。
ksize = net.params['conv'][0].data.shape[2:]
# make Gaussian blur
sigma = 1.
y, x = np.mgrid[-ksize[0]//2 + 1:ksize[0]//2 + 1, -ksize[1]//2 + 1:ksize[1]//2 + 1]
g = np.exp(-((x**2 + y**2)/(2.0*sigma**2)))
gaussian = (g / g.sum()).astype(np.float32)
net.params['conv'][0].data[0] = gaussian
# make Sobel operator for edge detection
net.params['conv'][0].data[1:] = 0.
sobel = np.array((-1, -2, -1, 0, 0, 0, 1, 2, 1), dtype=np.float32).reshape((3,3))
net.params['conv'][0].data[1, 0, 1:-1, 1:-1] = sobel # horizontal
net.params['conv'][0].data[2, 0, 1:-1, 1:-1] = sobel.T # vertical
show_filters(net)
可以看出,第0张图片是模糊的,第1张图片选出了水平方向的边缘,第2张图片选出了垂直方向的边缘
第六步:在全连接网络中构造分类器
!diff net_surgery/bvlc_caffenet_full_conv.prototxt ../models/bvlc_reference_caffenet/deploy.prototxt输出
1,2c1
< # Fully convolutional network version of CaffeNet.
< name: "CaffeNetConv"
---
> name: "CaffeNet"
5c4
< dim: 1
---
> dim: 10
7,8c6,7
< dim: 451
< dim: 451
---
> dim: 227
> dim: 227
154,155c153,154 #做过改变的行
< name: "fc6-conv" #将fc6改为fc6-conv
< type: "Convolution" #内积层变为卷基层
---
> name: "fc6"
> type: "InnerProduct"
157,158c156,157
< top: "fc6-conv"
< convolution_param { #变为卷积层后需要设置参数
---
> top: "fc6"
> inner_product_param {
160d158
< kernel_size: 6 #pool5的输出是36,全连接卷积层为6*6
166,167c164,165
< bottom: "fc6-conv"
< top: "fc6-conv"
---
> bottom: "fc6"
> top: "fc6"
172,173c170,171
< bottom: "fc6-conv"
< top: "fc6-conv"
---
> bottom: "fc6"
> top: "fc6"
179,183c177,181
< name: "fc7-conv"
< type: "Convolution"
< bottom: "fc6-conv"
< top: "fc7-conv"
< convolution_param {
---
> name: "fc7"
> type: "InnerProduct"
> bottom: "fc6"
> top: "fc7"
> inner_product_param {
185d182
< kernel_size: 1
191,192c188,189
< bottom: "fc7-conv"
< top: "fc7-conv"
---
> bottom: "fc7"
> top: "fc7"
197,198c194,195
< bottom: "fc7-conv"
< top: "fc7-conv"
---
> bottom: "fc7"
> top: "fc7"
204,208c201,205
< name: "fc8-conv"
< type: "Convolution"
< bottom: "fc7-conv"
< top: "fc8-conv"
< convolution_param {
---
> name: "fc8"
> type: "InnerProduct"
> bottom: "fc7"
> top: "fc8"
> inner_product_param {
210d206
< kernel_size: 1
216c212
< bottom: "fc8-conv"
---
> bottom: "fc8" 第七步
#载入传统的网络模型获取全连接层的参数
net = caffe.Net('models/bvlc_reference_caffenet/deploy.prototxt',
'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params = ['fc6', 'fc7', 'fc8']
fc_params = {pr: (net.params[pr][0].data, net.params[pr][1].data) for pr in params}
for fc in params:
print '{} weights are {} dimensional and biases are {} dimensional'.format(fc, fc_params[fc][0].shape, fc_params[fc][1].shape) 输出
fc6 weights are (4096, 9216) dimensional and biases are (4096,) dimensional
fc7 weights are (4096, 4096) dimensional and biases are (4096,) dimensional
fc8 weights are (1000, 4096) dimensional and biases are (1000,) dimensional第八步
# Load the fully convolutional network to transplant the parameters.
net_full_conv = caffe.Net('net_surgery/bvlc_caffenet_full_conv.prototxt',
'../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel',
caffe.TEST)
params_full_conv = ['fc6-conv', 'fc7-conv', 'fc8-conv']
# conv_params = {name: (weights, biases)}
conv_params = {pr: (net_full_conv.params[pr][0].data, net_full_conv.params[pr][1].data) for pr in params_full_conv}
for conv in params_full_conv:
print '{} weights are {} dimensional and biases are {} dimensional'.format(conv, conv_params[conv][0].shape, conv_params[conv][1].shape)载入更改后的全卷积网络配置和原先模型
输出:
fc6-conv weights are (4096, 256, 6, 6) dimensional and biases are (4096,) dimensional
fc7-conv weights are (4096, 4096, 1, 1) dimensional and biases are (4096,) dimensional
fc8-conv weights are (1000, 4096, 1, 1) dimensional and biases are (1000,) dimensional 卷积层的权重格式是output × input × height × width,为了将内积权重映射为卷积滤波器,我们需要将内积向量填充进channel × height × width的滤波器矩阵,但实际上内存是行优先阵列,因此二者是一致的。除了权重,偏移也是一样的。
第九步:开始移植
for pr, pr_conv in zip(params, params_full_conv):
conv_params[pr_conv][0].flat = fc_params[pr][0].flat # flat unrolls the arrays
conv_params[pr_conv][1][...] = fc_params[pr][1]第十步:保存新的模型权重
net_full_conv.save('net_surgery/bvlc_caffenet_full_conv.caffemodel')最后,从examples里猫的图片中做分类图。利用概率的热分布图可视化分类的置信度。这里对一个451*451的输入给出一个8*8的分类图,
第十一步
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# load input and configure preprocessing
im = caffe.io.load_image('images/cat.jpg')
transformer = caffe.io.Transformer({'data': net_full_conv.blobs['data'].data.shape})
transformer.set_mean('data', np.load('../python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1))
transformer.set_transpose('data', (2,0,1))
transformer.set_channel_swap('data', (2,1,0))
transformer.set_raw_scale('data', 255.0)
# make classification map by forward and print prediction indices at each location
out = net_full_conv.forward_all(data=np.asarray([transformer.preprocess('data', im)]))
print out['prob'][0].argmax(axis=0)
# show net input and confidence map (probability of the top prediction at each location)
plt.subplot(1, 2, 1)
plt.imshow(transformer.deprocess('data', net_full_conv.blobs['data'].data[0]))
plt.subplot(1, 2, 2)
plt.imshow(out['prob'][0,281])输出:
[[282 282 281 281 281 281 277 282]
[281 283 283 281 281 281 281 282]
[283 283 283 283 283 283 287 282]
[283 283 283 281 283 283 283 259]
[283 283 283 283 283 283 283 259]
[283 283 283 283 283 283 259 259]
[283 283 283 283 259 259 259 277]
[335 335 283 259 263 263 263 277]] 分类结果包含各种猫:
282是虎猫,281是斑猫,283是波斯猫,还有狐狸及其他哺乳动物。
用这种方式,全连接网络可以用于提取图像的密集特征,这比分类图本身更加有用。
注意,这种模型不完全适用与滑动窗口检测,因为它是为了整张图片的分类而训练的,然而,滑动窗口训练和微调可以通过在真值和loss的基础上定义一个滑动窗口,这样一个loss图就会由每一个位置组成,由此可以像往常一样解决。
测试
fine-tuning
fine-tuning模型的三种状态
- 只预测,不训练
- 训练,但只训练最后分类曾
- 完全训练,分类层+之前卷积层都训练
微调CaffeNet用于Flickr style数据集上的风格识别
我们之前了解过一些微调,当然做的例子不是很成功,数据集出现了一些问题,不过这次我们是用官方的例子,和数据集~~
基于已经训练好的模型,通过修改一些网络结构或者超参数等等,来满足我们的特定需求,这个例子最后达到的效果是对图像风格进行预测,而不是直接给定目标.
训练
我们先来整体看一下这个例子
我们所用的数据集和ImageNet数据集很像,因此可以通过调整ImageNet来满足我们数据集的需求,以做到图像分类.
现在预测的是20个类所以要将输出1000->20,在模型的最后一层
减少了solver prototxt中的总体学习率base_lr,但是增加新引进层的blobs_lr,主要原因是新数据让新加的层学习很快,模型中剩下的层改变很慢,在solver中设置stepsize为更低的值,希望学习率下降快一些.
第一步:导包
caffe_root = '../' # 这里是caffe的根目录,因为该ipynb在examples,根据自己的进行修改
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
#caffe.set_device(0)
#caffe.set_mode_gpu()
caffe.set_mode_cpu() #如果是cpu这里修改为cpu否则会出现错误
import numpy as np
from pylab import *
%matplotlib inline
import tempfile 该函数为图像的显示
def deprocess_net_image(image):
image = image.copy() # don't modify destructively
image = image[::-1] # BGR -> RGB
image = image.transpose(1, 2, 0) # CHW -> HWC
image += [123, 117, 104] # (approximately) undo mean subtraction
# clamp values in [0, 255]
image[image < 0], image[image > 255] = 0, 255
# round and cast from float32 to uint8
image = np.round(image)
image = np.require(image, dtype=np.uint8)
return image 第二步:设置和数据下载
下载需要的数据:
get_ilsvrc_aux.sh下载ImageNet数据集的均值,标签信息download_model_binary.py下载预训练的参数模型finetune_flickr_style/assemble_data.py下载训练和测试数据
# Download just a small subset of the data for this exercise.
# (2000 of 80K images, 5 of 20 labels.)
# To download the entire dataset, set `full_dataset = True`.
full_dataset = False
if full_dataset:
NUM_STYLE_IMAGES = NUM_STYLE_LABELS = -1
else:
NUM_STYLE_IMAGES = 2000
NUM_STYLE_LABELS = 5
# This downloads the ilsvrc auxiliary data (mean file, etc),
# and a subset of 2000 images for the style recognition task.
import os
os.chdir(caffe_root) # run scripts from caffe root
!data/ilsvrc12/get_ilsvrc_aux.sh
!scripts/download_model_binary.py models/bvlc_reference_caffenet
!python examples/finetune_flickr_style/assemble_data.py \
--workers=-1 --seed=1701 \
--images=$NUM_STYLE_IMAGES --label=$NUM_STYLE_LABELS
# back to examples
os.chdir('examples') 定义权值
import os
weights = caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
assert os.path.exists(weights) 从ilsvrc12/synset_words.txt中加载1000个ImageNet数据的标签,从finetune_flickr_style/style_names.txt里取5个标签
# Load ImageNet labels to imagenet_labels
imagenet_label_file = caffe_root + 'data/ilsvrc12/synset_words.txt'
imagenet_labels = list(np.loadtxt(imagenet_label_file, str, delimiter='\t'))
assert len(imagenet_labels) == 1000
print 'Loaded ImageNet labels:\n', '\n'.join(imagenet_labels[:10] + ['...'])
# Load style labels to style_labels
style_label_file = caffe_root + 'examples/finetune_flickr_style/style_names.txt'
style_labels = list(np.loadtxt(style_label_file, str, delimiter='\n'))
if NUM_STYLE_LABELS > 0:
style_labels = style_labels[:NUM_STYLE_LABELS]
print '\nLoaded style labels:\n', ', '.join(style_labels) 输出:
Loaded ImageNet labels:
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
n01484850 great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
n01491361 tiger shark, Galeocerdo cuvieri
n01494475 hammerhead, hammerhead shark
n01496331 electric ray, crampfish, numbfish, torpedo
n01498041 stingray
n01514668 cock
n01514859 hen
n01518878 ostrich, Struthio camelus
...
Loaded style labels:
Detailed, Pastel, Melancholy, Noir, HDR第三步:定义和运行网络
训练时的文件
deploy.prototxt:框架文件,用在预测+训练场景,caffenet函数生成 solver.prototxt:参数文件,用在训练场景,solver函数生成 train_val.prototxt:数据集文件,用在训练场景 x.caffemodel:模型权值参数文件 以上的一些函数,会在后续应用中由下面的函数生成caffenet函数
caffenet函数主要作用就是返回、制造caffeNet框架训练时候所需的框架文件:deploy.prototxt 输入:数据、标签、层名、学习率设置 输出:deploy文件caffenet(data, label=None, train=True, num_classes=1000,classifier_name='fc8', learn_all=False) # data代表训练数据 # label代表新数据标签,跟num_classes类似,跟给出数据的标签数量一致,譬如新数据的标签有5类,那么就是5 # train,是否开始训练,默认为true # num_classes代表fine-tuning来得模型的标签数,如果fine-tuning是ImageNet是千分类,那么num_classes=1000 # classifier_name,最后的全连接层名字,如果是fine-tuning需要重新训练的话,则需要修改最后的全连接层 # learn_all,这个变量用于将学习率设置为0,在caffenet中,如果learn_all=False,则使用frozen_param设置网络层的学习率,即学习率为0
style net函数
输入:学习率设置、子集设置、训练设置 输出:deploy文件train=TRUE,如果在不设置subset情况下则是代表使用训练集数据。同时框架文件deploy的训练是打开的,数据输入的时候,mirror功能也是打开着的。 train=FALSE,代表使用验证集,框架文件deploy不训练,只预测。 其中还有一个ImageData层,作为数据输入层,在整个文档中,是唯一数据输入入口,source是数据的来源。会在其他博客详细说明ImageData(caffe︱ImageData层、DummyData层作为原始数据导入的应用)。 该函数需要在data/flickr_style/**.txt有训练集+测试集的txt文件 需要有数据集的mean文件,此时应用的是caffeNet的mean文件 重置了最后的全连接层fc8_flickr
caffe.Net
输入:deploy框架文件、模型weight权值 输出:caffe引擎文件,用于后续caffe.Net(imagenet_net_filename, weights, caffe.TEST) # caffe.Net(deploy文件,模型权值,caffe.TEST)imagenet_net_filename是deploy文件,是整个框架的文件,也是caffenet/style_net得到的文件;
专门用于整个网络的生成预测函数disp_preds
输入:引擎文件(函数三)、新预测图片image,标签labels,K代表预测top多少、name便于输出 输出:返回print,top的准确率+分类标签,后期要改成returndef disp_preds(net, image, labels, k=5, name='ImageNet'): input_blob = net.blobs['data'] net.blobs['data'].data[0, ...] = image probs = net.forward(start='conv1')['probs'][0] top_k = (-probs).argsort()[:k] print 'top %d predicted %s labels =' % (k, name) print '\n'.join('\t(%d) %5.2f%% %s' % (i+1, 100*probs[p], labels[p]) for i, p in enumerate(top_k))预测函数disp_preds,通过函数三得到的引擎,进行net.forward前馈,通过net.forward(start=’conv1’)[‘probs’][0]获得所有标签的概率,然后通过排序输出top5
其中,labels如果是在验证集上就没有,那么可以不填的。
那么在之上作者封装了用于风格识别的函数:def disp_imagenet_preds(net, image): disp_preds(net, image, imagenet_labels, name='ImageNet') def disp_style_preds(net, image): disp_preds(net, image, style_labels, name='style')solver函数
输入:框架文件,(一般是caffenet/style_net之后)、学习率base_lr 输出:参数文件solverdef solver(train_net_path, test_net_path=None, base_lr=0.001) # train_net_path训练框架文件,一般是caffenet函数之后的deploy文件内容 # test_net_path # base_lr,学习率run_solvers训练函数
输入:迭代次数(niter)、参数文件solvers(函数五)、迭代间隔(disp_interval) 输出:loss/acc/weights值eval_style_net
输入:模型权值(run_solver之后)、迭代间隔10 输出:caffe.Net引擎、总体精确度
该网络中的完整代码
from caffe import layers as L
from caffe import params as P
weight_param = dict(lr_mult=1, decay_mult=1)
bias_param = dict(lr_mult=2, decay_mult=0)
learned_param = [weight_param, bias_param]
frozen_param = [dict(lr_mult=0)] * 2 #这个变量用于将学习率设置为0,在caffenet中,如果learn_all=False,则使用frozen_param设置网络层的学习率,即学习率为0
#该函数为定义激励函数
#参数:
# bottom:每层的输入
# ks:卷积核
# nout:输出神经元的个数
# stride:间隔
# pad:加边
# group:组,caffenet卷积部分有分到两个gpu上训练
# param:学习率参数
# weight_filter:权值滤波器
# bias_filter:偏置铝箔,一般设为常数
def conv_relu(bottom, ks, nout, stride=1, pad=0, group=1,
param=learned_param,
weight_filler=dict(type='gaussian', std=0.01),
bias_filler=dict(type='constant', value=0.1)):
conv = L.Convolution(bottom, kernel_size=ks, stride=stride,
num_output=nout, pad=pad, group=group,
param=param, weight_filler=weight_filler,
bias_filler=bias_filler)
return conv, L.ReLU(conv, in_place=True)
#全连接层
def fc_relu(bottom, nout, param=learned_param,
weight_filler=dict(type='gaussian', std=0.005),
bias_filler=dict(type='constant', value=0.1)):
fc = L.InnerProduct(bottom, num_output=nout, param=param,
weight_filler=weight_filler,
bias_filler=bias_filler)
return fc, L.ReLU(fc, in_place=True)
#MAX池化层
def max_pool(bottom, ks, stride=1):
return L.Pooling(bottom, pool=P.Pooling.MAX, kernel_size=ks, stride=stride)
#CaffeNet网络结构
def caffenet(data, label=None, train=True, num_classes=1000,
classifier_name='fc8', learn_all=False):
"""Returns a NetSpec specifying CaffeNet, following the original proto text
specification (./models/bvlc_reference_caffenet/train_val.prototxt)."""
n = caffe.NetSpec()
n.data = data
param = learned_param if learn_all else frozen_param
n.conv1, n.relu1 = conv_relu(n.data, 11, 96, stride=4, param=param)
n.pool1 = max_pool(n.relu1, 3, stride=2)
n.norm1 = L.LRN(n.pool1, local_size=5, alpha=1e-4, beta=0.75)
n.conv2, n.relu2 = conv_relu(n.norm1, 5, 256, pad=2, group=2, param=param)
n.pool2 = max_pool(n.relu2, 3, stride=2)
n.norm2 = L.LRN(n.pool2, local_size=5, alpha=1e-4, beta=0.75)
n.conv3, n.relu3 = conv_relu(n.norm2, 3, 384, pad=1, param=param)
n.conv4, n.relu4 = conv_relu(n.relu3, 3, 384, pad=1, group=2, param=param)
n.conv5, n.relu5 = conv_relu(n.relu4, 3, 256, pad=1, group=2, param=param)
n.pool5 = max_pool(n.relu5, 3, stride=2)
n.fc6, n.relu6 = fc_relu(n.pool5, 4096, param=param)
if train:
n.drop6 = fc7input = L.Dropout(n.relu6, in_place=True)
else:
fc7input = n.relu6
n.fc7, n.relu7 = fc_relu(fc7input, 4096, param=param)
if train:
n.drop7 = fc8input = L.Dropout(n.relu7, in_place=True)
else:
fc8input = n.relu7
# always learn fc8 (param=learned_param)
fc8 = L.InnerProduct(fc8input, num_output=num_classes, param=learned_param)
# give fc8 the name specified by argument `classifier_name`
n.__setattr__(classifier_name, fc8)
if not train:
n.probs = L.Softmax(fc8)
if label is not None:
n.label = label
n.loss = L.SoftmaxWithLoss(fc8, n.label)
n.acc = L.Accuracy(fc8, n.label)
# write the net to a temporary file and return its filename
with tempfile.NamedTemporaryFile(delete=False) as f:
f.write(str(n.to_proto()))
return f.name
#创建一个“dummy data”(虚拟数据)作为CaffeNet的输入,允许在外部设置输入图像,查看预测类别
dummy_data = L.DummyData(shape=dict(dim=[1, 3, 227, 227]))
imagenet_net_filename = caffenet(data=dummy_data, train=False)
imagenet_net = caffe.Net(imagenet_net_filename, weights, caffe.TEST)
#定义一个函数Style_net调用caffenet,输入数据参数为Flicker style数据集
# 网络的输入是下载的Fliker style 数据集,层类型为ImageData
# 输出是20个类别
# 分类层重命名为fc8_flicker以告诉caffe不要加载原始分类的那一层的权值
def style_net(train=True, learn_all=False, subset=None):
if subset is None:
subset = 'train' if train else 'test'
source = caffe_root + 'data/flickr_style/%s.txt' % subset
transform_param = dict(mirror=train, crop_size=227,
mean_file=caffe_root + 'data/ilsvrc12/imagenet_mean.binaryproto')
style_data, style_label = L.ImageData(
transform_param=transform_param, source=source,
batch_size=50, new_height=256, new_width=256, ntop=2)
return caffenet(data=style_data, label=style_label, train=train,
num_classes=NUM_STYLE_LABELS,
classifier_name='fc8_flickr',
learn_all=learn_all)
#使用style_net初始化未训练的网络, 这个caffeNet的输入图像数据来自于style数据集而其权值来自于之前已经训练好的ImageNet模型
#定义untrained_style_net变量调用前向传播函数获取一批训练数据
untrained_style_net = caffe.Net(style_net(train=False, subset='train'),
weights, caffe.TEST)
untrained_style_net.forward()
style_data_batch = untrained_style_net.blobs['data'].data.copy()
style_label_batch = np.array(untrained_style_net.blobs['label'].data, dtype=np.int32)
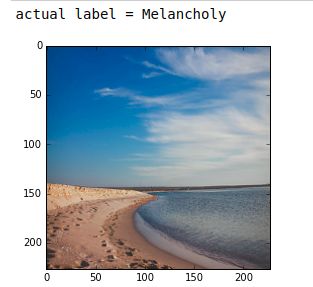
#从第一批训练数据的50张图像中选择一张(这里选择第8张)显示该图片,然后在imagenet_net上运行,ImageNet预训练网络给出前5个得分最高的类别
#下面我们选择一张网络可以给出合理预测的图片,因为该图片为一张海滩图片,而沙洲和海岸这两个类别是存于ImageNet的1000个类别中的,对于其他的图片,预测结果未必好,有些是由于网络识别物体错误,但是跟有可能是由于ImageNet的1000个类别中没有被识别图片的类别,修改batch_index的值将默认的9 改为0-49中的任意一个数字,观察其他图像的预测结果
def disp_preds(net, image, labels, k=5, name='ImageNet'):
input_blob = net.blobs['data']
net.blobs['data'].data[0, ...] = image
probs = net.forward(start='conv1')['probs'][0]
top_k = (-probs).argsort()[:k]
print 'top %d predicted %s labels =' % (k, name)
print '\n'.join('\t(%d) %5.2f%% %s' % (i+1, 100*probs[p], labels[p])
for i, p in enumerate(top_k))
def disp_imagenet_preds(net, image):
disp_preds(net, image, imagenet_labels, name='ImageNet')
def disp_style_preds(net, image):
disp_preds(net, image, style_labels, name='style')
batch_index = 8
image = style_data_batch[batch_index]
plt.imshow(deprocess_net_image(image))
print 'actual label =', style_labels[style_label_batch[batch_index]] 输出:
在这里我换了张图片做了测试
batch_index = 7输出:

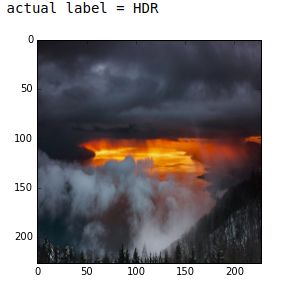
这些图片都不是很准确是因为ImageNet没有相似的图片,所有我试了基本上有将近
20张图片,80%都是HDR,Detailed,Noiry
因此我们继续用第一张做测试
disp_imagenet_preds(imagenet_net, image) 输出:
top 5 predicted ImageNet labels =
(1) 69.89% n09421951 sandbar, sand bar
(2) 21.75% n09428293 seashore, coast, seacoast, sea-coast
(3) 3.22% n02894605 breakwater, groin, groyne, mole, bulwark, seawall, jetty
(4) 1.89% n04592741 wing
(5) 1.23% n09332890 lakeside, lakeshore我们也可以看看untrained_style_net的预测,但是肯定的不到你感兴趣的结果,因为它还没有开始训练
实际上,因为我们的分类器初始化为0(观察caffenet,没有权值滤波其经过最后的内积层),softmax的输入应当全部为0,因此,我们看到每个标签的预测结果为1/N,这里n为5,因此所有的预测结果都为20%。
disp_style_preds(untrained_style_net, image) 输出:
top 5 predicted style labels =
(1) 20.00% Detailed
(2) 20.00% Pastel
(3) 20.00% Melancholy
(4) 20.00% Noir
(5) 20.00% HDR可以验证在分类层之前的fc7的激励与ImageNet的预训练模型相同(或者十分相似),因为两个模型在conv1到fc7中使用相同的预训练权值
diff = untrained_style_net.blobs['fc7'].data[0] - imagenet_net.blobs['fc7'].data[0]
error = (diff ** 2).sum()
assert error < 1e-8 删除untrained_style_net
del untrained_style_net 第四步:训练style 分类器
定义solver函数创建caffe的solver文件中的参数,用于训练网络(学习权值),在这个函数中,我们会设置各种参数的值用于学习,显示,和“快照”。[注]这里也将GPU->CPU
from caffe.proto import caffe_pb2
def solver(train_net_path, test_net_path=None, base_lr=0.001):
s = caffe_pb2.SolverParameter()
# Specify locations of the train and (maybe) test networks.
s.train_net = train_net_path
if test_net_path is not None:
s.test_net.append(test_net_path)
s.test_interval = 1000 # Test after every 1000 training iterations.
s.test_iter.append(100) # Test on 100 batches each time we test.
# The number of iterations over which to average the gradient.
# Effectively boosts the training batch size by the given factor, without
# affecting memory utilization.
s.iter_size = 1
s.max_iter = 100000 # # of times to update the net (training iterations)
# Solve using the stochastic gradient descent (SGD) algorithm.
# Other choices include 'Adam' and 'RMSProp'.
s.type = 'SGD'
# Set the initial learning rate for SGD.
s.base_lr = base_lr
# Set `lr_policy` to define how the learning rate changes during training.
# Here, we 'step' the learning rate by multiplying it by a factor `gamma`
# every `stepsize` iterations.
s.lr_policy = 'step'
s.gamma = 0.1
s.stepsize = 20000
# Set other SGD hyperparameters. Setting a non-zero `momentum` takes a
# weighted average of the current gradient and previous gradients to make
# learning more stable. L2 weight decay regularizes learning, to help prevent
# the model from overfitting.
s.momentum = 0.9
s.weight_decay = 5e-4
# Display the current training loss and accuracy every 1000 iterations.
s.display = 1000
# Snapshots are files used to store networks we've trained. Here, we'll
# snapshot every 10K iterations -- ten times during training.
s.snapshot = 10000
s.snapshot_prefix = caffe_root + 'models/finetune_flickr_style/finetune_flickr_style'
# Train on the GPU. Using the CPU to train large networks is very slow.
s.solver_mode = caffe_pb2.SolverParameter.CPU
# Write the solver to a temporary file and return its filename.
with tempfile.NamedTemporaryFile(delete=False) as f:
f.write(str(s))
return f.name现在,我们调用solver函数训练style_net的分类层
注:因为这里没有用GPU,所以并没有训练100000次,后面的数据都是训练10000次的结果(毕竟太慢了…..),但是我会把100000次的数据也展示出来~
这里注意下,如果你想使用命令工具训练网络,命令如下:
build/tools/caffe train \
-solver models/finetune_flickr_style/solver.prototxt \
-weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel \
-gpu 0 在这里,我们使用python训练这个例子
首先定义run_solvers函数,在这个函数中,给定solvers的列表和步骤的循环。在每一步迭代中记录正确率和损失,最后将学习到的权值保存在一个文件中
def run_solvers(niter, solvers, disp_interval=10):
"""Run solvers for niter iterations,
returning the loss and accuracy recorded each iteration.
`solvers` is a list of (name, solver) tuples."""
blobs = ('loss', 'acc')
loss, acc = ({name: np.zeros(niter) for name, _ in solvers}
for _ in blobs)
for it in range(niter):
for name, s in solvers:
s.step(1) # run a single SGD step in Caffe
loss[name][it], acc[name][it] = (s.net.blobs[b].data.copy()
for b in blobs)
if it % disp_interval == 0 or it + 1 == niter:
loss_disp = '; '.join('%s: loss=%.3f, acc=%2d%%' %
(n, loss[n][it], np.round(100*acc[n][it]))
for n, _ in solvers)
print '%3d) %s' % (it, loss_disp)
# Save the learned weights from both nets.
weight_dir = tempfile.mkdtemp()
weights = {}
for name, s in solvers:
filename = 'weights.%s.caffemodel' % name
weights[name] = os.path.join(weight_dir, filename)
s.net.save(weights[name])
return loss, acc, weights 创建和运行solvers训练网络,我们将创建两个方案,一个使用ImageNet的预训练权值初始化(style_solver),另一个使用随机初始化(scratch_style_solver).
在训练过程中,将发现使用预训练的模型更快且有更高的准确率
niter = 200 # number of iterations to train
# Reset style_solver as before.
style_solver_filename = solver(style_net(train=True))
style_solver = caffe.get_solver(style_solver_filename)
style_solver.net.copy_from(weights)
# For reference, we also create a solver that isn't initialized from
# the pretrained ImageNet weights.
scratch_style_solver_filename = solver(style_net(train=True))
scratch_style_solver = caffe.get_solver(scratch_style_solver_filename)
print 'Running solvers for %d iterations...' % niter
solvers = [('pretrained', style_solver),
('scratch', scratch_style_solver)]
loss, acc, weights = run_solvers(niter, solvers)
print 'Done.'
train_loss, scratch_train_loss = loss['pretrained'], loss['scratch']
train_acc, scratch_train_acc = acc['pretrained'], acc['scratch']
style_weights, scratch_style_weights = weights['pretrained'], weights['scratch']
# Delete solvers to save memory.
del style_solver, scratch_style_solver, solvers 输出:
Running solvers for 200 iterations...
0) pretrained: loss=1.609, acc=28%; scratch: loss=1.609, acc=28%
10) pretrained: loss=1.341, acc=46%; scratch: loss=1.626, acc=14%
20) pretrained: loss=1.158, acc=58%; scratch: loss=1.641, acc=12%
30) pretrained: loss=0.869, acc=68%; scratch: loss=1.616, acc=22%
40) pretrained: loss=0.988, acc=64%; scratch: loss=1.591, acc=24%
50) pretrained: loss=1.174, acc=62%; scratch: loss=1.610, acc=32%
60) pretrained: loss=0.871, acc=66%; scratch: loss=1.622, acc=16%
70) pretrained: loss=1.011, acc=64%; scratch: loss=1.590, acc=30%
80) pretrained: loss=0.845, acc=66%; scratch: loss=1.593, acc=34%
90) pretrained: loss=1.090, acc=66%; scratch: loss=1.605, acc=24%
100) pretrained: loss=0.990, acc=64%; scratch: loss=1.589, acc=30%
110) pretrained: loss=1.127, acc=62%; scratch: loss=1.592, acc=30%
120) pretrained: loss=0.886, acc=62%; scratch: loss=1.596, acc=26%
130) pretrained: loss=0.752, acc=70%; scratch: loss=1.586, acc=28%
140) pretrained: loss=0.913, acc=68%; scratch: loss=1.608, acc=18%
150) pretrained: loss=0.493, acc=84%; scratch: loss=1.609, acc=20%
160) pretrained: loss=0.898, acc=70%; scratch: loss=1.597, acc=26%
170) pretrained: loss=1.155, acc=64%; scratch: loss=1.623, acc=20%
180) pretrained: loss=0.904, acc=68%; scratch: loss=1.634, acc=10%
190) pretrained: loss=0.674, acc=74%; scratch: loss=1.610, acc=20%
199) pretrained: loss=0.866, acc=70%; scratch: loss=1.613, acc=14%
Done.可以看到两种训练过程的正确率和损失。蓝色线条表示使用预训练模型的损失,绿色表示随机初始化的损失。
plot(np.vstack([train_loss, scratch_train_loss]).T)
xlabel('Iteration #')
ylabel('Loss') 输出:
text.Text at 0x7f75d49e1090> 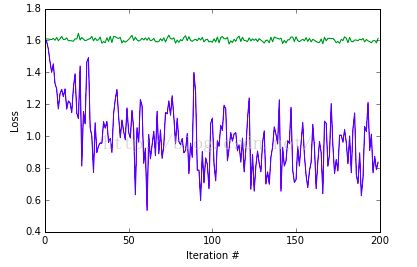
正确率曲线:
plot(np.vstack([train_acc, scratch_train_acc]).T)
xlabel('Iteration #')
ylabel('Accuracy') 
查看这200次迭代的结果,可以看出,预训练的结果要好于随机初始化的结果
def eval_style_net(weights, test_iters=10):
test_net = caffe.Net(style_net(train=False), weights, caffe.TEST)
accuracy = 0
for it in xrange(test_iters):
accuracy += test_net.forward()['acc']
accuracy /= test_iters
return test_net, accuracy
test_net, accuracy = eval_style_net(style_weights)
print 'Accuracy, trained from ImageNet initialization: %3.1f%%' % (100*accuracy, )
scratch_test_net, scratch_accuracy = eval_style_net(scratch_style_weights)
print 'Accuracy, trained from random initialization: %3.1f%%' % (100*scratch_accuracy, ) 输出:
Accuracy, trained from ImageNet initialization: 50.0%
Accuracy, trained from random initialization: 23.6%第五步:重新训练两个网络
从刚才学习到的权值开始,唯一不同的是,这次权值的学习过程是“end-to-end”的,从RGB conv1滤波器开始,微调网络的所有层。将learn_all参数设为True,这个参数告诉网络将所有层的lr_mult设为一个正数。需要说明的是,可以从前面的代码观察到,tearn_all参数默认值为False,当其为False时,意味着预训练的层(conv1到fc7)的lr_mult=0,我们仅仅学习了最后一层。
end-to-end的训练由显著的提高
end_to_end_net = style_net(train=True, learn_all=True)
# Set base_lr to 1e-3, the same as last time when learning only the classifier.
# You may want to play around with different values of this or other
# optimization parameters when fine-tuning. For example, if learning diverges
# (e.g., the loss gets very large or goes to infinity/NaN), you should try
# decreasing base_lr (e.g., to 1e-4, then 1e-5, etc., until you find a value
# for which learning does not diverge).
base_lr = 0.001
style_solver_filename = solver(end_to_end_net, base_lr=base_lr)
style_solver = caffe.get_solver(style_solver_filename)
style_solver.net.copy_from(style_weights)
scratch_style_solver_filename = solver(end_to_end_net, base_lr=base_lr)
scratch_style_solver = caffe.get_solver(scratch_style_solver_filename)
scratch_style_solver.net.copy_from(scratch_style_weights)
print 'Running solvers for %d iterations...' % niter
solvers = [('pretrained, end-to-end', style_solver),
('scratch, end-to-end', scratch_style_solver)]
_, _, finetuned_weights = run_solvers(niter, solvers)
print 'Done.'
style_weights_ft = finetuned_weights['pretrained, end-to-end']
scratch_style_weights_ft = finetuned_weights['scratch, end-to-end']
# Delete solvers to save memory.
del style_solver, scratch_style_solver, solvers 输出:
Running solvers for 200 iterations...
0) pretrained, end-to-end: loss=0.756, acc=76%; scratch, end-to-end: loss=1.585, acc=28%
10) pretrained, end-to-end: loss=1.286, acc=54%; scratch, end-to-end: loss=1.635, acc=14%
20) pretrained, end-to-end: loss=1.026, acc=62%; scratch, end-to-end: loss=1.626, acc=12%
30) pretrained, end-to-end: loss=0.937, acc=68%; scratch, end-to-end: loss=1.597, acc=22%
40) pretrained, end-to-end: loss=0.745, acc=74%; scratch, end-to-end: loss=1.578, acc=24%
50) pretrained, end-to-end: loss=0.943, acc=62%; scratch, end-to-end: loss=1.599, acc=34%
60) pretrained, end-to-end: loss=0.727, acc=74%; scratch, end-to-end: loss=1.555, acc=26%
70) pretrained, end-to-end: loss=0.625, acc=74%; scratch, end-to-end: loss=1.550, acc=36%
80) pretrained, end-to-end: loss=0.572, acc=80%; scratch, end-to-end: loss=1.488, acc=48%
90) pretrained, end-to-end: loss=0.731, acc=68%; scratch, end-to-end: loss=1.497, acc=34%
100) pretrained, end-to-end: loss=0.481, acc=86%; scratch, end-to-end: loss=1.503, acc=32%
110) pretrained, end-to-end: loss=0.512, acc=76%; scratch, end-to-end: loss=1.624, acc=26%
120) pretrained, end-to-end: loss=0.437, acc=82%; scratch, end-to-end: loss=1.534, acc=34%
130) pretrained, end-to-end: loss=0.765, acc=68%; scratch, end-to-end: loss=1.513, acc=30%
140) pretrained, end-to-end: loss=0.439, acc=82%; scratch, end-to-end: loss=1.491, acc=28%
150) pretrained, end-to-end: loss=0.379, acc=84%; scratch, end-to-end: loss=1.489, acc=34%
160) pretrained, end-to-end: loss=0.479, acc=88%; scratch, end-to-end: loss=1.437, acc=30%
170) pretrained, end-to-end: loss=0.467, acc=80%; scratch, end-to-end: loss=1.610, acc=34%
180) pretrained, end-to-end: loss=0.444, acc=82%; scratch, end-to-end: loss=1.471, acc=40%
190) pretrained, end-to-end: loss=0.431, acc=82%; scratch, end-to-end: loss=1.435, acc=42%
199) pretrained, end-to-end: loss=0.483, acc=78%; scratch, end-to-end: loss=1.384, acc=46%
Done.测试微调后的模型,因为所有的网络参与了识别任务,所以两个网络的结果要好于之前的结果。
test_net, accuracy = eval_style_net(style_weights_ft)
print 'Accuracy, finetuned from ImageNet initialization: %3.1f%%' % (100*accuracy, )
scratch_test_net, scratch_accuracy = eval_style_net(scratch_style_weights_ft)
print 'Accuracy, finetuned from random initialization: %3.1f%%' % (100*scratch_accuracy, ) 输出:
Accuracy, finetuned from ImageNet initialization: 53.6%
Accuracy, finetuned from random initialization: 39.2%看一下对一开始的图像的预测
plt.imshow(deprocess_net_image(image))
disp_style_preds(test_net, image) 输出:
top 5 predicted style labels =
(1) 55.67% Melancholy
(2) 27.21% HDR
(3) 16.46% Pastel
(4) 0.63% Detailed
(5) 0.03% Noir看起来要比之前的好,但是,这张图像在测试集中,网络知道这张图片的标签
最后,我们选一张测试集中的图片
batch_index = 1
image = test_net.blobs['data'].data[batch_index]
plt.imshow(deprocess_net_image(image))
print 'actual label =', style_labels[int(test_net.blobs['label'].data[batch_index])] 输出:
actual label = Pastel
disp_style_preds(test_net, image) 输出
top 5 predicted style labels =
(1) 99.76% Pastel
(2) 0.13% HDR
(3) 0.11% Detailed
(4) 0.00% Melancholy
(5) 0.00% Noir看一下随机出事化的网络的结果:
disp_style_preds(scratch_test_net, image) 输出:
top 5 predicted style labels =
(1) 49.81% Pastel
(2) 19.76% Detailed
(3) 17.06% Melancholy
(4) 11.66% HDR
(5) 1.72% Noir最后,看一下ImageNet的预测结果
disp_imagenet_preds(imagenet_net, image) 输出:
top 5 predicted ImageNet labels =
(1) 34.90% n07579787 plate
(2) 21.63% n04263257 soup bowl
(3) 17.75% n07875152 potpie
(4) 5.72% n07711569 mashed potato
(5) 5.27% n07584110 consomme第四步生成的网络结构中,我们可以看到,所有已经预训练的层(conv1-fc7层)lr_mult(学习率的倍数)均为0,而在end-to-end中均是非0正数。
新的网络结构与原始的caffenet是有不同的,新的网络中,最后的分类层的学习率的值是原始的caffenet网络的10倍,这个也是网络微调要关注的地方,在我们用已经训练好的模型微调自己的网络结构时,我们只需将变动过的层的学习率调大,关注于训练改动过的那些层。
调整参数测试
(本来想跑出来10000个数据,自己执行以下看看结果,电脑不给力,估计跑不出来了)
于是把solver调整了一下
from caffe.proto import caffe_pb2
def solver(train_net_path, test_net_path=None, base_lr=0.001):
s = caffe_pb2.SolverParameter()
s.train_net = train_net_path
if test_net_path is not None:
s.test_net.append(test_net_path)
s.test_interval = 1000 # Test after every 1000 training iterations.
s.test_iter.append(100) # Test on 100 batches each time we test.
s.iter_size = 1
s.max_iter = 2000 # # of times to update the net (training iterations)
s.type = 'SGD'
s.base_lr = base_lr
s.lr_policy = 'step'
s.gamma = 0.1
s.stepsize = 200
s.momentum = 0.9
s.weight_decay = 5e-4
s.display = 100
s.snapshot = 2000
s.snapshot_prefix = caffe_root + 'models/finetune_flickr_style/finetune_flickr_style'
s.solver_mode = caffe_pb2.SolverParameter.CPU
with tempfile.NamedTemporaryFile(delete=False) as f:
f.write(str(s))
return f.name输出:
Running solvers for 200 iterations...
0) pretrained: loss=1.609, acc= 0%; scratch: loss=1.609, acc= 0%
10) pretrained: loss=1.353, acc=48%; scratch: loss=1.625, acc=14%
20) pretrained: loss=1.169, acc=54%; scratch: loss=1.641, acc=12%
30) pretrained: loss=0.967, acc=64%; scratch: loss=1.615, acc=22%
40) pretrained: loss=0.953, acc=60%; scratch: loss=1.591, acc=24%
50) pretrained: loss=1.142, acc=54%; scratch: loss=1.610, acc=32%
60) pretrained: loss=0.947, acc=58%; scratch: loss=1.621, acc=16%
70) pretrained: loss=0.890, acc=66%; scratch: loss=1.589, acc=30%
80) pretrained: loss=0.837, acc=76%; scratch: loss=1.593, acc=34%
90) pretrained: loss=1.157, acc=56%; scratch: loss=1.606, acc=24%
100) pretrained: loss=1.098, acc=60%; scratch: loss=1.587, acc=30%
110) pretrained: loss=1.040, acc=60%; scratch: loss=1.593, acc=30%
120) pretrained: loss=0.928, acc=70%; scratch: loss=1.596, acc=26%
130) pretrained: loss=0.759, acc=72%; scratch: loss=1.584, acc=28%
140) pretrained: loss=0.965, acc=64%; scratch: loss=1.609, acc=18%
150) pretrained: loss=0.611, acc=84%; scratch: loss=1.612, acc=20%
160) pretrained: loss=0.914, acc=64%; scratch: loss=1.599, acc=26%
170) pretrained: loss=1.035, acc=60%; scratch: loss=1.620, acc=20%
180) pretrained: loss=0.935, acc=56%; scratch: loss=1.631, acc=10%
190) pretrained: loss=1.088, acc=56%; scratch: loss=1.613, acc=20%
199) pretrained: loss=0.765, acc=76%; scratch: loss=1.614, acc=14%
Done.损失值:
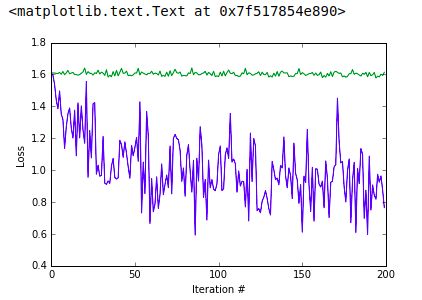
准确率:
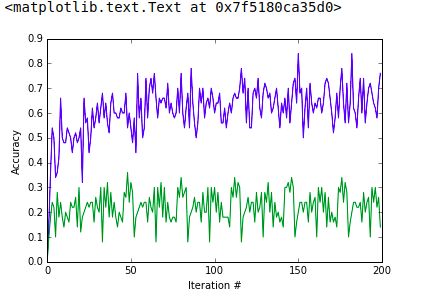
准确率计算:
Accuracy, trained from ImageNet initialization: 52.6%
Accuracy, trained from random initialization: 23.6%end-to-end跑了两个小时…
在这个网络中,和原始网络唯一的不同就是,这次权值的学习过程是’end-to-end’的,从RGB conv1滤波器开始,微调网络的所有层,将learn_all参数调整为True,这个参数告诉神经网络,将所有层的lr_mult设为一个正数
看一下结果:
Running solvers for 200 iterations...
0) pretrained, end-to-end: loss=0.721, acc=76%; scratch, end-to-end: loss=1.586, acc=28%
10) pretrained, end-to-end: loss=1.123, acc=58%; scratch, end-to-end: loss=1.636, acc=14%
20) pretrained, end-to-end: loss=1.048, acc=52%; scratch, end-to-end: loss=1.626, acc=14%
30) pretrained, end-to-end: loss=1.002, acc=62%; scratch, end-to-end: loss=1.597, acc=22%
40) pretrained, end-to-end: loss=0.751, acc=72%; scratch, end-to-end: loss=1.573, acc=26%
50) pretrained, end-to-end: loss=0.727, acc=66%; scratch, end-to-end: loss=1.599, acc=28%
60) pretrained, end-to-end: loss=0.702, acc=72%; scratch, end-to-end: loss=1.555, acc=28%
70) pretrained, end-to-end: loss=0.614, acc=76%; scratch, end-to-end: loss=1.540, acc=36%
80) pretrained, end-to-end: loss=0.812, acc=70%; scratch, end-to-end: loss=1.489, acc=46%
90) pretrained, end-to-end: loss=0.561, acc=78%; scratch, end-to-end: loss=1.527, acc=26%
100) pretrained, end-to-end: loss=0.553, acc=74%; scratch, end-to-end: loss=1.487, acc=34%
110) pretrained, end-to-end: loss=0.593, acc=78%; scratch, end-to-end: loss=1.570, acc=28%
120) pretrained, end-to-end: loss=0.611, acc=78%; scratch, end-to-end: loss=1.557, acc=34%
130) pretrained, end-to-end: loss=0.591, acc=74%; scratch, end-to-end: loss=1.506, acc=24%
140) pretrained, end-to-end: loss=0.738, acc=76%; scratch, end-to-end: loss=1.511, acc=28%
150) pretrained, end-to-end: loss=0.421, acc=82%; scratch, end-to-end: loss=1.516, acc=32%
160) pretrained, end-to-end: loss=0.477, acc=84%; scratch, end-to-end: loss=1.420, acc=30%
170) pretrained, end-to-end: loss=0.444, acc=80%; scratch, end-to-end: loss=1.602, acc=36%
180) pretrained, end-to-end: loss=0.495, acc=72%; scratch, end-to-end: loss=1.494, acc=36%
190) pretrained, end-to-end: loss=0.364, acc=84%; scratch, end-to-end: loss=1.446, acc=38%
199) pretrained, end-to-end: loss=0.450, acc=88%; scratch, end-to-end: loss=1.375, acc=42%
Done.明显有提高
Accuracy, finetuned from ImageNet initialization: 53.6%
Accuracy, finetuned from random initialization: 40.6%再来看一下之前图片的预测
top 5 predicted style labels =
(1) 89.31% Melancholy
(2) 9.16% HDR
(3) 1.46% Pastel
(4) 0.07% Detailed
(5) 0.01% Noir
换一张图片进行测试
batch_index = 14
image = test_net.blobs['data'].data[batch_index]
plt.imshow(deprocess_net_image(image))
print 'actual label =', style_labels[int(test_net.blobs['label'].data[batch_index])]
end-to-end
top 5 predicted style labels =
(1) 99.82% Pastel
(2) 0.17% Melancholy
(3) 0.01% HDR
(4) 0.00% Detailed
(5) 0.00% Noirrandom
top 5 predicted style labels =
(1) 43.01% Pastel
(2) 23.14% Melancholy
(3) 17.86% Detailed
(4) 12.90% HDR
(5) 3.08% Noirimagenet
top 5 predicted ImageNet labels =
(1) 28.13% n04275548 spider web, spider's web
(2) 7.97% n07714990 broccoli
(3) 6.01% n02219486 ant, emmet, pismire
(4) 5.24% n02206856 bee
(5) 4.23% n04209239 shower curtain参考文章:
http://blog.csdn.net/thystar/article/details/51258613
http://blog.csdn.net/sinat_26917383/article/details/54999868