PFLD论文解析及复现
PFLD论文解析及复现《一》:论文解析
PFLD:简单、快速、超高精度人脸特征点检测算法
刚好,这两天解决了前面文章关于Mobilenet-ssd物体检测的一些问题,借用训练机跑Mobilenet-ssd模型的空余时间,就前一段时间发布并自己进行复现的文章《PFLD: A Practical Facial Landmark Detector》进行一些说明,而这也是自己入手DP以来,第一次面向企业进行人脸相关研究的项目之一,将其核心思想进行实现以供后续加入公司产品,这篇文章先将PFLD论文的核心思想进行一些分析和总结,下一篇将会就自己的实现做一些分享。
总之,PFLD成为实用人脸特征点检测算法的典范,其中损失函数的设计是整个网络的核心要素,论文实现了三个目标:精度高、速度快、模型小!这里先给出论文地址:https://arxiv.org/pdf/1902.10859.pdf

PFLD算法,目前主流数据集上达到最高精度、ARM安卓机140fps,模型大小仅2.1M!
这篇今天新出的论文,必将成为人脸特征点检测领域的重要文献,今天我们就一起来探究一下,PFLD算法到底有什么黑科技。
作者信息

作者分别来自天津大学、武汉大学、腾讯AI实验室、美国天普大学。
感谢各位大牛!
人脸特征点检测的挑战
作者首先从算法实用性角度讨论了人脸特征点检测问题的面临的挑战。
Challenge #1 - Local Variation
人脸表情变化很大,真实环境光照复杂,而且现实中大量存在人脸局部被遮挡的情况等。
Challenge #2 - Global Variation
人脸是3D的,位姿变化多样,另外因拍摄设备和环境影响,成像质量也有好有坏。
Challenge #3 - Data Imbalance
现有训练样本各个类别存在不平衡的问题。
Challenge #4 - Model Efficiency
在计算受限的设备比如手机终端,必须要考虑计算速度和模型文件大小问题。
算法思想
作者使用的网络结构如下:
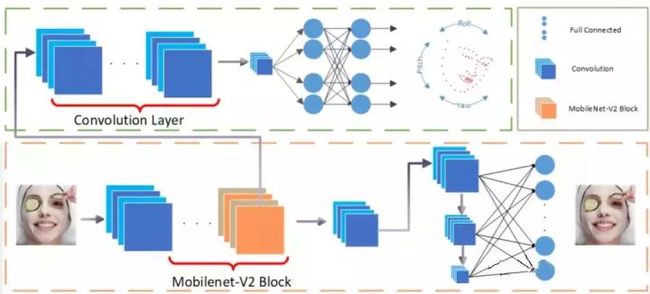
其中,
黄色曲线包围的是主网络,用于预测特征点的位置;
绿色曲线包围的部分为辅网络,在训练时预测人脸姿态(有文献表明给网络加这个辅助任务可以提高定位精度,具体参考原论文),这部分在测试时不需要。
作者主要用两种方法,解决上述问题。
对于上述影响精度的挑战,修改loss函数在训练时关注那些稀有样本,而提高计算速度和减小模型size则是使用轻量级模型。
Loss函数设计
Loss函数用于神经网络在每次训练时预测的形状和标注形状的误差。
考虑到样本的不平衡,作者希望能对那些稀有样本赋予更高的权重,这种加权的Loss函数被表达为:
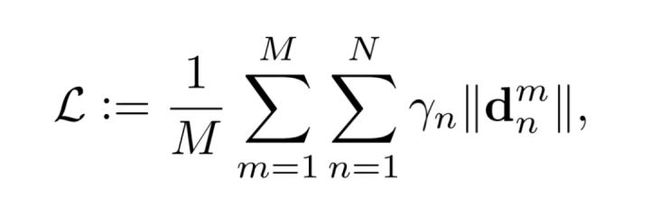
M为样本个数,N为特征点个数,Yn为不同的权重,|| * ||为特征点的距离度量(L1或L2距离)。(以Y代替公式里的希腊字母)
进一步细化Yn:

其中
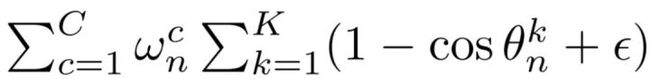
即为最终的样本权重。
K=3,这一项代表着人脸姿态的三个维度,即yaw, pitch, roll 角度,可见角度越高,权重越大。
C为不同的人脸类别数,作者将人脸分成多个类别,比如侧脸、正脸、抬头、低头、表情、遮挡等,w为与类别对应的给定权重,如果某类别样本少则给定权重大。
主网络
作者使用轻量级的MobileNet,其参数如下:

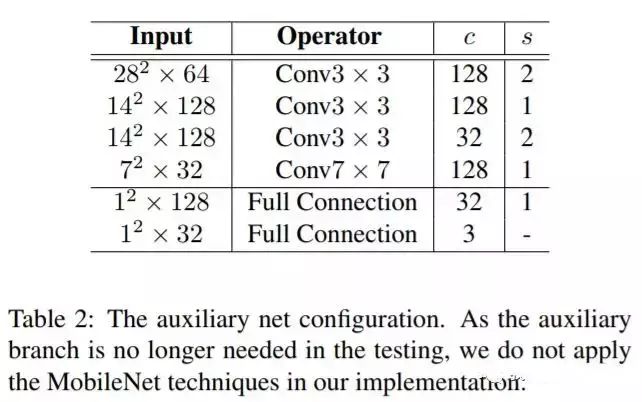
辅网络
参数如下:
实验结果
作者在主流人脸特征点数据集300W,AFLW上测试了精度,尽管看起来上述模型很简单,但超过了以往文献的最高精度!
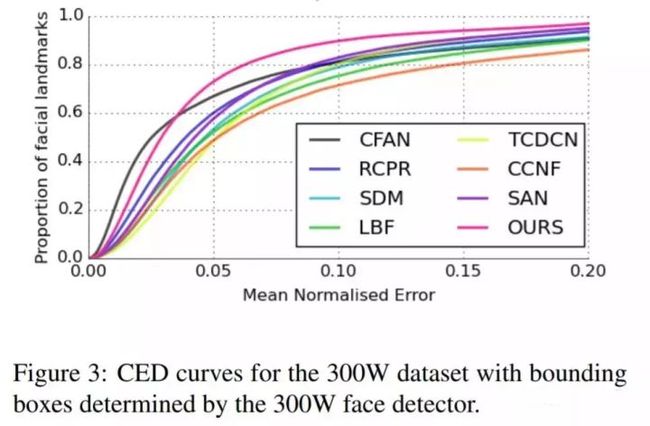
下图是在300W上的CED,完美将其他算法的曲线压在下面。
下图为在300W数据集上不同评价标准IPN\IOP精度比较结果,依然是最棒的。

其中PFLD 1X是标准网络,PFLD 0.25X是MobileNet blocks width 参数设为0.25的压缩网络,PFLD 1X+是在WFLW数据集上预训练的网络。
值得一提的是表格中LAB算法,是CVPR2018上出现的优秀算法,之前一直是state-of-the-art。感兴趣的朋友可以参考52CV当时的报道:重磅!清华&商汤开源CVPR2018超高精度人脸对齐算法LAB 。
下图是该算法在AFLW数据集上与其他算法的精度比较:

同样是达到了新高度!
下面来看一下算法处理速度和模型大小,图中C代表i7-6700K CPU,G代表080 Ti GPU,G*代表Titan X GPU,A代表移动平台Qualcomm ARM 845处理器。

PFDL同样是异乎优秀!与精度差别很小的LAB算法相比,CPU上的速度提高了2000倍!
下面是一些特征点检测示例,尽管很多样本难度很大,但PFLD依然给出了可以接受的结果。


这里再次给出论文地址:
https://arxiv.org/pdf/1902.10859.pdf
PFLD算法看起来简单,但精度却很高,这无疑来自作者设计的Loss函数很好的处理了样本类别不平衡的问题。上述就是PFLD论文的一些大致情况,后面我会就自己对其的实现进行分享。