代码与算法集锦-归并排序+树状数组+快排+深度优先搜索+01背包(动态规划)
归并排序
求逆序数
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
//将有序数组a[]和b[]合并到c[]中
void MemeryArray(int a[], int n, int b[], int m, int c[])
{
int i, j, k;
i = j = k = 0;
while (i < n && j < m)
{
if (a[i] < b[j])
c[k++] = a[i++];
else
c[k++] = b[j++];
}
while (i < n)
c[k++] = a[i++];
while (j < m)
c[k++] = b[j++];
}
可以看出合并有序数列的效率是比较高的,可以达到O(n)。
解决了上面的合并有序数列问题,再来看归并排序,其的基本思路就是将数组分成二组A,B,如果这二组组内的数据都是有序的,那么就可以很方便的将这二组数据进行排序。如何让这二组组内数据有序了?
可以将A,B组各自再分成二组。依次类推,当分出来的小组只有一个数据时,可以认为这个小组组内已经达到了有序,然后再合并相邻的二个小组就可以了。这样通过先递归的分解数列,再合并数列就完成了归并排序。
public class GuiBingPaiXu {
static int count;// 新增
/*
* 归并排序+逆序数
*
* 与归并排序比较 增加了两行核心代码
*
*
* 如果ia[j] 成为逆序数
*
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
// int[] a = { 26,5,77,1,61,11,59,15,48,19 };
// int[] a={4,3,6,5,1,2};
int[] a = { 2, 4, 3, 1 };
sop(a);
Guibing(a, 0, a.length - 1);
sop(a);
System.out.println(count);
}
public static void sop(int[] arr) {
for (int i = 0; i < arr.length; i++) {
System.out.print(arr[i] + "\t");
}
System.out.println();
}
public static void Guibing(int[] n, int first, int last) {
if (first < last) {
int mid = (first + last) / 2;
// 左边
Guibing(n, first, mid);
// 右边
Guibing(n, mid + 1, last);
// 左右归并
Mes(n, first, mid, last);
}
}
public static void Mes(int[] a, int first, int mid, int last) {
int[] temp = new int[a.length];
int i = first;
int j = mid + 1;
int m = mid, n = last;
int k = 0;
// 把较小的数先移到新数组中
while (i <= m && j <= n) {
if (a[i] <= a[j]) {
temp[k++] = a[i++];
} else {
temp[k++] = a[j++];
count += mid - i + 1;// 逆序数 核心代码
}
}
// 把左边剩余的数先移到新数组中
while (i <= m) {
temp[k++] = a[i++];
}
// 把右边剩余的数移到新数组中
while (j <= m) {
temp[k++] = a[j++];
}
// 把新数组中的元素 覆盖到 a数组中
for (int p = 0; p < k; p++) {
a[first + p] = temp[p];
}
}
}
树状数组
一、树状数组是干什么的?
平常我们会遇到一些对数组进行维护查询的操作,比较常见的如,修改某点的值、求某个区间的和,而这两种恰恰是树状数组的强项!当然,数据规模不大的时候,对于修改某点的值是非常容易的,复杂度是O(1),但是对于求一个区间的和就要扫一遍了,复杂度是O(N),如果实时的对数组进行M次修改或求和,最坏的情况下复杂度是O(M*N),当规模增大后这是划不来的!而树状数组干同样的事复杂度却是O(M*lgN),别小看这个lg,很大的数一lg就很小了,这个学过数学的都知道吧,不需要我说了。申明一下,看下面的文章一定不要急,只需要看懂每一步最后自然就懂了。
二、树状数组怎么干的?
先看两幅图(网上找的,如果雷同,不要大惊小怪~),下面的说明都是基于这两幅图的,左边的叫A图吧,右边的叫B图:

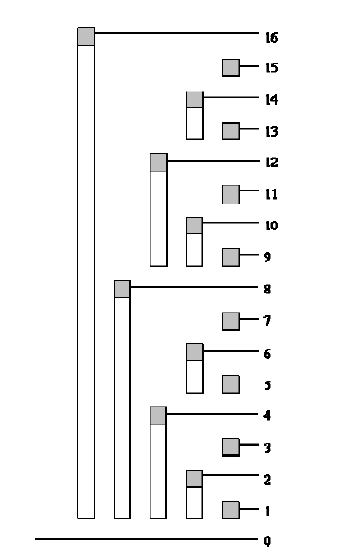
是不是很像一颗树?对,这就是为什么叫树状数组了~先看A图,a数组就是我们要维护和查询的数组,但是其实我们整个过程中根本用不到a数组,你可以把它当作一个摆设!c数组才是我们全程关心和操纵的重心。
先由图来看看c数组的规则,其中c8 = c4+c6+c7+a8,c6 = c5+a6……先不必纠结怎么做到的,我们只要知道c数组的大致规则即可,很容易知道c8表示a1~a8的和,但是c6却是表示a5~a6的和,为什么会产生这样的区别的呢?或者说发明她的人为什么这样区别对待呢?答案是,这样会使操作更简单!看到这相信有些人就有些感觉了,为什么复杂度被lg了呢?可以看到,c8可以看作a1~a8的左半边和+右半边和,而其中左半边和是确定的c4,右半边其实也是同样的规则把a5~a8一分为二……继续下去都是一分为二直到不能分,可以看看B图。怎么样?是不是有点二分的味道了?对,说白了树状数组就是巧妙的利用了二分,她并不神秘,关键是她的巧妙!
她又是怎样做到不断的一分为二呢?说这个之前我先说个叫lowbit的东西,lowbit(k)就是把k的二进制的高位1全部清空,只留下最低位的1,比如10的二进制是1010,则lowbit(k)=lowbit(1010)=0010(2进制),介于这个lowbit在下面会经常用到,这里给一个非常方便的实现方式,比较普遍的方法lowbit(k)=k&-k,这是位运算,我们知道一个数加一个负号是把这个数的二进制取反+1,如-10的二进制就是-1010=0101+1=0110,然后用1010&0110,答案就是0010了!明白了求解lowbit的方法就可以了,继续下面。介于下面讨论十进制已经没有意义(这个世界本来就是二进制的,人非要主观的构建一个十进制),下面所有的数没有特别说明都当作二进制。
上面那么多文字说lowbit,还没说它的用处呢,它就是为了联系a数组和c数组的!ck表示从ak开始往左连续求lowbit(k)个数的和,比如c[0110]=a[0110]+a[0101],就是从110开始计算了0010个数的和,因为lowbit(0110)=0010,可以看到其实只有低位的1起作用,因为很显然可以写出c[0010]=a[0010]+a[0001],这就为什么我们任何数都只关心它的lowbit,因为高位不起作用(基于我们的二分规则它必须如此!),除非除了高位其余位都是0,这时本身就是lowbit。
既然关系建立好了,看看如何实现a某一个位置数据跟改的,她不会直接改的(开始就说了,a根本不存在),她每次改其实都要维护c数组应有的性质,因为后面求和要用到。而维护也很简单,比如更改了a[0011],我们接着要修改c[0011],c[0100],c[1000],这是很容易从图上看出来的,但是你可能会问,他们之间有申明必然联系吗?每次求解总不能总要拿图来看吧?其实从0011——>0100——>1000的变化都是进行“去尾”操作,又是自己造的词–”,我来解释下,就是把尾部应该去掉的1都去掉转而换到更高位的1,记住每次变换都要有一个高位的1产生,所以0100是不能变换到0101的,因为没有新的高位1产生,这个变换过程恰好是可以借助我们的lowbit进行的,k +=lowbit(k)。
private static int lowbit(int x) {
// TODO Auto-generated method stub
return x & -x;
}
好吧,现在更新的次序都有了,可能又会产生新的疑问了:为什么它非要是这种关系啊?这就要追究到之前我们说c8可以看作a1~a8的左半边和+右半边和……的内容了,为什么c[0011]会影响到c[0100]而不会影响到c[0101],这就是之前说的c[0100]的求解实际上是这样分段的区间 c[0001]~c[0001] 和区间c[0011]~c[0011]的和,数字太小,可能这样不太理解,在比如c[0100]会影响c[1000],为什么呢?因为c[1000]可以看作0001~0100的和加上0101~1000的和,但是0101位置的数变化并会直接作用于c[1000],因为它的尾部1不能一下在跳两级在产生两次高位1,是通过c[0110]间接影响的,但是,c[0100]却可以跳一级产生一次高位1。
可能上面说的你比较绕了,那么此时你只需注意:c的构成性质(其实是分组性质)决定了c[0011]只会直接影响c[0100],而c[0100]只会直接影响[1000],而下表之间的关系恰好是也必须是k +=lowbit(k)。此时我们就写出跟新维护树的代码:
public static void update(int t, int x) {
for (int i = t; i < a + 1; i += lowbit(i)) {
treearray[i] += x;
}
}
求区间和
public static int getSum(int x) {
int temp = 0;
for (int j = x; j >= 1; j -= lowbit(j)) {
temp += treearray[j];
}
return temp;
}
树状数组求逆序数
以蓝桥杯小朋友排队为例:
import java.util.Scanner;
public class Main {
static int m;
static int[] aa;
static int[] bit;
static int[] hh;
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int huhu = sc.nextInt();
m = huhu + 1;
aa = new int[m];
for (int i = 1; i < m; i++) {
aa[i] = sc.nextInt();
}
//离散化操作这里没有进行离散化操作 小白在这里 还不懂离散化操作 求大神指教 联系 QQ:189281351
bit = new int[m];
hh = new int[m];
aa[0] = huhu;
sop(aa);
for (int i = 1; i < aa.length; i++) {
update(aa[i], 1);
hh[i] = i - getSum(aa[i]);//求左侧逆序数
}
System.out.println();
System.out.println("左侧的逆序数");
sop(hh);
//sop(bit);
bit=new int[m];//bit数组为过度,这句代码 是为了清零 bit数组,为了在下面的代码里面求 右侧的逆序数 数量 更准确!
//sop(bit);
for (int i = huhu; i >= 1; i--) {
update(aa[i], 1);
hh[i]=getSum(aa[i]-1);//求右侧逆序数
}
System.out.println("右侧的逆序数");
sop(hh);
}
public static void update(int t, int x) {
for (int i = t; i < m; i += lowbit(i)) {
bit[i] += x;
}
}
private static int lowbit(int x) {
// TODO Auto-generated method stub
return x & (-x);
}
public static int getSum(int x) {
int temp = 0;
for (int j = x; j >= 1; j -= lowbit(j)) {
temp += bit[j];
//sop(bit);
}
return temp;
}
public static void sop(int[] a) {
for (int i = 0; i < a.length; i++) {
System.out.print(a[i] + "\t");
}
System.out.println();
}
}
快速排序
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用,再加上快速排序思想—-分治法也确实实用,因此很多软件公司的笔试面试,包括像腾讯,微软等知名IT公司都喜欢考这个,还有大大小的程序方面的考试如软考,考研中也常常出现快速排序的身影。
总的说来,要直接默写出快速排序还是有一定难度的,因为本人就自己的理解对快速排序作了下白话解释,希望对大家理解有帮助,达到快速排序,快速搞定。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
- 先从数列中取出一个数作为基准数。
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 再对左右区间重复第二步,直到各区间只有一个数。
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 72 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 48 | 85 |
初始时,i = 0; j = 9; X = a[i] = 72
由于已经将a[0]中的数保存到X中,可以理解成在数组a[0]上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j–;
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 88 | 60 | 42 | 83 | 73 | 88 | 85 |
i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 48 | 6 | 57 | 42 | 60 | 72 | 83 | 73 | 88 | 85 |
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结
- i =L; j = R; 将基准数挖出形成第一个坑a[i]。
- j–由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
- i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
- 再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
照着这个总结很容易实现挖坑填数的代码:
/*
* 快速排序,快速搞定。
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
*/
public class quick_sort {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] n = new int[] { 25, 12, 36, 45, 2, 9, 39, 22, 98, 37 };
int l = 0;
int r=n.length-1;
quicke(n,l,r);
sop(n);
}
private static void quicke(int[] n, int l, int r) {
// TODO Auto-generated method stub
if (l < r) {
int i=l,j=r,x=n[l];
while(i < j)
{
while(i=x)//从右向左找第一个小于x的数
j--;
if (i < j)
n[i++]=n[j];
while(i DFS实现全排列
DFS深度优先搜索思想
不撞南墙不回头
import java.util.Scanner;
public class quanpailie_sousuo {
static int[] book;// 计数器
static int[] a;// 盒子
static int n;
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
a = new int[10];
book = new int[10];
n = sc.nextInt();
dfs(1);
}
private static void dfs(int step) {
// TODO Auto-generated method stub
if (step == n + 1) {
for (int i = 1; i <= n; i++) {
System.out.print(a[i]);
}
System.out.println();
return;// 返回之前的一步,最近一次调用dfs函数的地方
}
for (int i = 1; i <= n; i++) {
if (book[i] == 0) {// book[i]=0表示i号扑克牌仍然在手上
a[step] = i;// 将i号扑克牌放入第step个盒子中
book[i] = 1;// 将book[i]设为1 , 表示 i 号 扑克牌 已经不在手上了
dfs(step + 1);// 递归调用
book[i] = 0;// 这是非常重要的一步,一定要将刚才尝试的扑克收回,才能进行下一次尝试
}
}
}
}
这个简单的例子,核心代码不超过20行,却饱含深度优先搜索的基本模型。理解深度优先搜索的关键在于解决“当下该如何做”。至于“下一步如何做”则与“当下该如何做”是一样的。比如我们这里写的dfs函数的主要功能就是解决你在第step个盒子的时候你该怎么办。通常的方法就是把每一种可能都去尝试一遍(一般用for循环来遍历)。当前这一步解决后便进去下一步dfs(step+1)。下一步的解决方法和当前这一步的解决方法是完全一样的,下面的代码就是深度优先搜索的基本模型。
public static void dfs(int step)
{
判断边界
尝试每一种可能 for(i=1;i<= n;i++)
{
继续下一步 dfs(step+1);
}
返回
}
DFS走迷宫最短路径
迷宫由n行m列的单元格组成(n和m都小于等于50),每个单元格要么是空地,要么是障碍物,从起点到指定位置的最短路径,注意障碍物是不能走的。
import java.util.Scanner;
public class migong {
static int p;//终点x坐标
static int q;//终点y坐标
static int startx;//起点x坐标
static int starty;//起点y左边
static int[][] book;//标记数组,用来记录是否已经访问过该坐标
static int n;
static int m;
static int[][] a;
static int min = 99999999 ;
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
n = sc.nextInt();
m = sc.nextInt();
a = new int[51][51];
book=new int[51][51];
for (int i = 1; i <= n; i++) {//读入数组,舍弃0行0列 角标,从第一行第一列角标开始 读入数组中
for (int j = 1; j <= m; j++) {
a[i][j] = sc.nextInt();
}
}
//sop(a, m, n);
startx=sc.nextInt();
starty=sc.nextInt();
p = sc.nextInt();
q = sc.nextInt();
book[startx][starty]=1;//初始化起点为1,表示已经访问过了。
dfs(startx,starty,0);
System.out.println(min);
}
private static void dfs(int x, int y , int step) {
// TODO Auto-generated method stub
int[][] next=new int[][]{//用数组判断方向
{0,1},//向右
{1,0},//向下
{0,-1},//向左
{-1,0},//向上
};
if (x == p && y == q) {//判断是否已经找到终点
if (step < min)
min =step;
return;
}
int tx,ty;
//枚举四种走法
for (int k = 0; k <= 3; k++) {
//计算下一个点的坐标
tx=x+next[k][0];
ty=y+next[k][1];
//判断是否越界
if (tx < 1 || tx > n || ty < 1 ||ty > m) {
continue ;
}
if (a[tx][ty] == 0 && book[tx][ty] ==0) {
book[tx][ty]=1;
dfs(tx, ty, step+1);
book[tx][ty]=0;
}
}
}
public static void sop(int[][] a, int n, int m) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
System.out.print(a[i][j] + "\t");
}
System.out.println();
}
}
}
动态规划
一直没理解动态规划,那就从它的定义看,帮助自己理解。
下面摘自百度百科,知道前因后果就容易理解哪些属于动态规划了。
动态规划(dynamic programming)是运筹学的一个分支,是求解决策过程(decision process)最优化的数学方法。20世纪50年代初美国数学家R.E.Bellman等人在研究多阶段决策过程(multistep decision process)的优化问题时,提出了著名的最优化原理(principle of optimality),把多阶段过程转化为一系列单阶段问题,利用各阶段之间的关系,逐个求解,创立了解决这类过程优化问题的新方法——动态规划。1957年出版了他的名著Dynamic Programming,这是该领域的第一本著作。
分类:
动态规划一般可分为线性动规,区域动规,树形动规,背包动规四类。
举例:
线性动规:拦截导弹,合唱队形,挖地雷,建学校,剑客决斗等
区域动规:石子合并, 加分二叉树,统计单词个数,炮兵布阵等
树形动规:贪吃的九头龙,二分查找树,聚会的欢乐,数字三角形等
背包问题:01背包问题,完全背包问题,分组背包问题,二维背包,装箱问题,挤牛奶(同济ACM第1132题)等
概念意义:
动态规划程序设计是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。不像搜索或数值计算那样,具有一个标准的数学表达式和明确清晰的解题方法。动态规划程序设计往往是针对一种最优化问题,由于各种问题的性质不同,确定最优解的条件也互不相同,因而动态规划的设计方法对不同的问题,有各具特色的解题方法,而不存在一种万能的动态规划算法,可以解决各类最优化问题。
基本结构:
多阶段决策问题中,各个阶段采取的决策,一般来说是与时间有关的,决策依赖于当前状态,又随即引起状态的转移,一个决策序列就是在变化的状态中产生出来的,故有“动态”的含义,称这种解决多阶段决策最优化问题的方法为动态规划方法。
基本模型:
多阶段决策过程的最优化问题。含有递推的思想以及各种数学原理(加法原理,乘法原理等等)。
在现实生活中,有一类活动的过程,由于它的特殊性,可将过程分成若干个互相联系的阶段,在它的每一阶段都需要作出决策,从而使整个过程达到最好的活动效果。当然,各个阶段决策的选取不是任意确定的,它依赖于当前面临的状态,又影响以后的发展,当各个阶段决策确定后,就组成一个决策序列,因而也就确定了整个过程的一条活动路线。
它包含了以下几种基本模型:
(1)确定问题的决策对象。
(2)对决策过程划分阶段。 (3)对各阶段确定状态变量。 (4)根据状态变量确定费用函数和目标函数。 (5)建立各阶段状态变量的转移过程,确定状态转移方程。
状态转移方程的一般形式:
一般形式: U:状态; X:策略
顺推:f[Uk]=opt{f[Uk-1]+L[Uk-1,Xk-1]} 其中, L[Uk-1,Xk-1]: 状态Uk-1通过策略Xk-1到达状态Uk 的费用 初始f[U1];结果:f[Un]。
倒推:
f[Uk]=opt{f[Uk+1]+L[Uk,Xk]}
L[Uk,Xk]: 状态Uk通过策略Xk到达状态Uk+1 的费用
初始f[Un];结果:f(U1)
解决的常见的问题:
在编程中常用解决最长公共子序列问题、矩阵连乘问题、凸多边形最优三角剖分问题、电路布线等问题
01背包问题
import java.util.Scanner;
public class Main {
static int[] weight = new int[] { 0, 2, 2, 6, 5, 4 };// 每个物品的重量
static int[] value = new int[] { 0, 6, 3, 5, 4, 6 };// 每个物品的价值
// static int[][] values;// 存放价值
static int maxweight;// 背包的最大承重
public static void main(String[] args) {
// TODO Auto-generated method stub
Scanner sc = new Scanner(System.in);
maxweight = sc.nextInt();
int[][] values = new int[value.length][maxweight + 1];
for (int i = 0; i < value.length; i++) {
values[i][0] = 0;
}
for (int i = 0; i <= maxweight; i++) {
values[0][i] = 0;
}
for ( int i = 1; i <= 5; i++){
for ( int j = 1; j<=maxweight; j++){
if(weight[i]>j){
values[i][j]=values[i-1][j];
}else {
values[i][j]=Math.max(values[i-1][j-weight[i]]+value[i], values[i-1][j]);
}
}
}
}
}
另一个动态规划的例子
//最大子段和的问题,用动态规划。
/*给定一个长度为n的一维数组a,请找出此数组的一个子数组,使得此子数组的和sum 最大,其中 i>=0 ,
* i=i,jmaxsofar) {
maxsofar=sum;
}
}
}
System.out.print("带记忆的递推法");
System.out.println(maxsofar);
}
private static void first(int[] array) {
// TODO Auto-generated method stub
int b=0,sum=-10000000;
for (int i = 0; i < array.length; i++) {
if (b > 0) {
b+=array[i];
}else {
b=array[i];
}
if (b > sum) {
sum = b;
}
}
System.out.print("DP");
System.out.println(sum);
}
}