Logistic regression逻辑回归·二分类算法【知识整理】
Logistic regression逻辑回归·二分类算法(分析基础)
- 综述
- 原理介绍
- 逻辑回归
- Sigmoid函数(核心)
- 决策边界
- 似然函数求解
- 逻辑回归的实现
- 代码模块
- 绘制散点图观察数据
- logistic regression
- sigmoid
- model
- cost
- gradient
- 停止策略及洗牌
- descent
- 分析不同的停止策略
- 设置迭代次数
- 根据损失值停止
- 根据梯度变化停止
- 不同梯度下降方法
- Stochastic descent
- Mini-batch descent
- accuracy
- 小结
综述
学生党整理一些关于数据分析的知识:逻辑回归二分类算法的介绍及如何使用python完成该回归方法。
原理介绍
逻辑回归
逻辑回归是经典的二分类算法,非常常用。在机器学习算法选择上,考虑先使用逻辑回归算法再采用其他复杂的算法,能用简单的就用简单的。逻辑回归的决策边界可以是非线性的。
Sigmoid函数(核心)
- 公式: g ( x ) = 1 1 + e − z g(x)=\frac{1}{1+e^{-z}} g(x)=1+e−z1
- 函数图像:
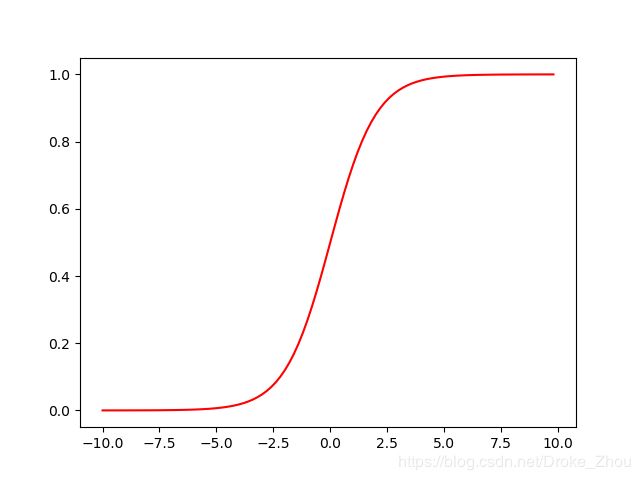
- 自变量为 ( − ∞ , + ∞ ) (-\infty,+\infty ) (−∞,+∞),值域为 ( 0 , 1 ) (0,1) (0,1)
- 函数意义:将任意的输入映射到 ( 0 , 1 ) (0,1) (0,1)区间。我们在线性回归中可以得到一个预测值,再将该值映射到Sigmoid函数中这样就完成了由值到概率的转换,就实现了分类目的。
决策边界
-
边界示意图
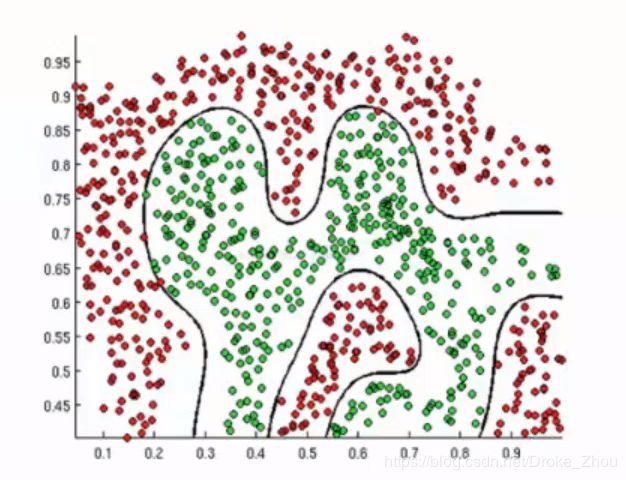
-
预测函数: h θ ( x ) = g ( θ T x ) = 1 1 + e − θ T x h_\theta(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}} hθ(x)=g(θTx)=1+e−θTx1
其中 θ 0 + θ 1 x 1 + . . . + θ n x n = ∑ i = 0 n θ i x i = θ T x \theta_0+\theta_1x_1+...+\theta_nx_n= \sum^{n}_{i = 0}\theta_ix_i=\theta^Tx θ0+θ1x1+...+θnxn=i=0∑nθixi=θTx -
分类任务: P ( y = 1 ∣ x ; θ ) = h θ ( x ) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) P(y=1|x;\theta)=h_\theta(x)\\P(y=0|x;\theta)=1-h_\theta(x) P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
整合: P ( y = 1 ∣ x ; θ ) = ( h θ ( x ) ) y ( 1 − h θ ( x ) ) 1 − y P(y=1|x;\theta)=(h_\theta(x))^y(1-h_\theta(x))^{1-y} P(y=1∣x;θ)=(hθ(x))y(1−hθ(x))1−y -
解释:对于二分类任务 ( 0 , 1 ) (0,1) (0,1),整合后 y = 0 y=0 y=0只保留 ( 1 − h θ ( x ) ) 1 − y (1-h_\theta(x))^{1-y} (1−hθ(x))1−y, y = 1 y=1 y=1只保留 ( h θ ( x ) ) y (h_\theta(x))^{y} (hθ(x))y。
似然函数求解
似然函数求解过程和线性回归的使用方式类似:
- 似然函数: L ( θ ) = ∏ i = 1 m p ( y i ∣ x i ; θ ) = ∏ i = 1 m ( h θ ( x i ) ) y i ( 1 − h θ ( x i ) ) 1 − y i L(\theta)=\prod_{i=1}^{m}p(y_i|x_i;\theta)=\prod_{i=1}^{m}(h_\theta(x_i))^{y_i}(1-h_\theta(x_i))^{1-y_i} L(θ)=i=1∏mp(yi∣xi;θ)=i=1∏m(hθ(xi))yi(1−hθ(xi))1−yi
- 似然函数取对数: l ( θ ) = l o g ( L ( θ ) ) = ∑ i = 1 m ( p ( y i ∣ x i ; θ ) = ∑ i = 1 m ( y i l o g h θ ( x i ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ) l(\theta)=log(L(\theta))=\sum_{i=1}^{m}(p(y_i|x_i;\theta)=\sum_{i=1}^{m}(y_ilogh_\theta(x_i)+(1-y_i)log(1-h_\theta(x_i))) l(θ)=log(L(θ))=i=1∑m(p(yi∣xi;θ)=i=1∑m(yiloghθ(xi)+(1−yi)log(1−hθ(xi)))
- 此时应用梯度上升求最大值,我们采用 J ( θ ) = − 1 m l ( θ ) J(\theta)=-\frac{1}{m}l(\theta) J(θ)=−m1l(θ)转换为梯度下降任务。
- 对 θ \theta θ求偏导后得到: ∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i j \frac{\partial{J(\theta)}}{\partial{\theta}_j}=\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x_i)-y_i)x_i^j ∂θj∂J(θ)=m1i=1∑m(hθ(xi)−yi)xij
- 参数更新: θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x i ) − y i ) x i j \theta_j:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_\theta(x_i)-y_i)x^j_i θj:=θj−αm1i=1∑m(hθ(xi)−yi)xij
逻辑回归的实现
- 任务:我们将建立一个逻辑回归模型来预测一个学生是否被大学录取。根据两次考试的结果来决定每个人的录取情况。
代码模块
调用库并读取LogiReg_data.txt中的数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
#读取txt文件中的数据
path ='LogiReg_data.txt'
pdData = pd.read_csv(path,header = None,names =['Exam 1','Exam 2','Admitted'])
print(pdData.head(2))
| Exam 1 | Exam 2 | Admitted | |
|---|---|---|---|
| 0 | 34.623660 | 78.024693 | 0 |
| 1 | 30.286711 | 43.894998 | 0 |
绘制散点图观察数据
通常可以绘制散点图,观察数据的分布情况
positive = pdData[pdData['Admitted']==1]
negative = pdData[pdData['Admitted']==0]
fig, ax = plt.subplots()
ax.scatter(positive['Exam 1'],positive['Exam 2'],s=15,c = 'b',marker = 'o', label = 'Admitted')
ax.scatter(negative['Exam 1'],negative['Exam 2'],s=15,c = 'r',marker = 'x', label = 'Not Admitted')
ax.legend()
ax.set_xlabel ('Exam 1 Score')
ax.set_ylabel ('Exam 2 Score')
plt.show()
通过图片观察,录取与不录取的边界明显
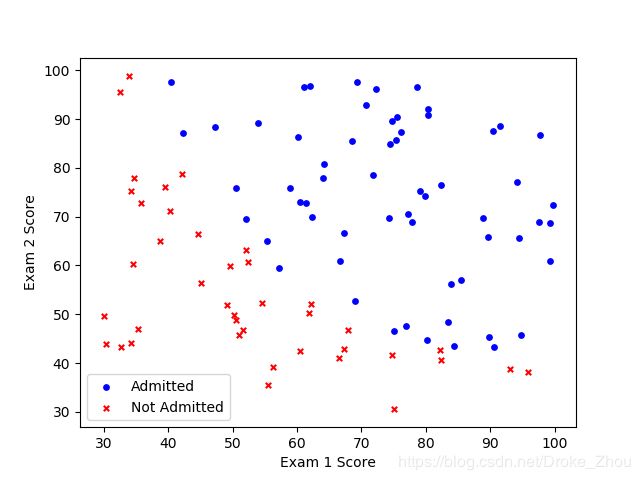
logistic regression
- 目标:建立分类器(求出对于的三个参数 θ 0 θ 1 θ 2 \theta_0\theta_1\theta_2 θ0θ1θ2)
- 设置阈值:根据阈值判断录取结果
需要完成的模块
- sigmoid:映射到概率的函数
- model:返回预测结果值
- cost:根据参数计算损失
- gradient:计算每个参数的梯度方向
- descent:进行参数更新
- accuracy:计算精度
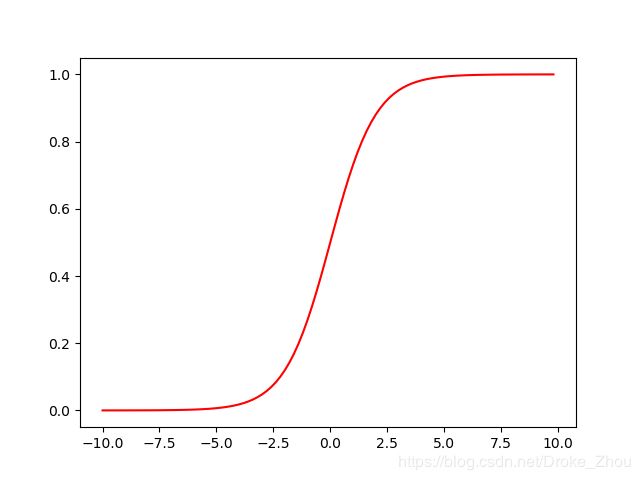
sigmoid
def sigmoid(z):
return 1/(1+np.exp(-z))
nums = np.arange(-10,10,step = 0.2)
fig, ax = plt.subplots()
ax.plot(nums, sigmoid(nums),'r')
plt.show()
model
( θ 0 θ 1 θ 2 ) × ( 1 x 1 x 2 ) T = θ 0 + θ 1 x 1 + θ 2 x 2 (\theta_0\quad \theta_1\quad \theta_2)\times(1\quad x_1\quad x_2)^ T=\theta_0+\theta_1x_1+ \theta_2x_2 (θ0θ1θ2)×(1x1x2)T=θ0+θ1x1+θ2x2
def model(x, theta):
return sigmoid(np.dot(x, theta.T))
#增加常数项
pdData.insert(0, 'Ones', 1)
#将数据分成x,y
orig_data = pdData.values
cols = orig_data.shape[1]
X = orig_data[:,0:cols - 1]
y = orig_data[:,cols - 1:cols]
theta = np.zeros([1,3]) #参数 1行3列
cost
损失函数
- 将对数似然函数加负号: D ( h θ ( x ) , y ) = − y l o g h θ ( x ) − ( 1 − y ) l o g ( 1 − h θ ( x ) ) D(h_\theta(x),y)=-ylogh_\theta(x)-(1-y)log(1-h_\theta(x)) D(hθ(x),y)=−yloghθ(x)−(1−y)log(1−hθ(x))
- 求平均损失: J ( θ ) = 1 n ∑ i = 1 n D ( h θ ( x ) , y ) J(\theta)=\frac{1}{n}\sum_{i=1}^{n}D(h_\theta(x),y) J(θ)=n1i=1∑nD(hθ(x),y)
- 计算梯度: ∂ J ( θ ) ∂ θ j = − 1 m ∑ i = 1 m ( y i − h θ ( x i ) ) x i j \frac{\partial{J(\theta)}}{\partial{\theta}_j}=-\frac{1}{m}\sum_{i=1}^{m}(y_i-h_\theta(x_i))x_i^j ∂θj∂J(θ)=−m1i=1∑m(yi−hθ(xi))xij
def cost(X,y,theta):
left = np.multiply(-y,np.log(model(X,theta)))
right = np.multiply((1-y),np.log(1-model(X,theta)))
return np.sum(left - right) / (len(X))
print(cost(X,y,theta))
返回的cost值:0.6931471805599453
gradient
计算梯度
def gradient(X,y,theta):
grad = np.zeros(theta.shape)
error = (model(X,theta)-y).ravel()
for j in range(len(theta.ravel())):
term = np.multiply(error, X[:,j])
grad[0,j] = np.sum(term)/len(X)
return grad
print(gradient(X,y,theta))
返回的grad为:[[ -0.1 -12.00921659 -11.26284221]]
停止策略及洗牌
停止策略分为3种:
- 训练次数
- 两次损失度差值
- 梯度
def stopCriterion(type, value, threshold):
if type == STOP_ITER:
return value > threshold
elif type == STOP_COST:
return abs(value[-1]-value[-2])< threshold
elif type == STOP_GRAD:
return np.linalg.norm(value) < threshold
def shuffleData(data):
np.random.shuffle(data)
cols = data.shape[1]
X = data[:,0:cols-1]
y = data[:,cols-1:]
return X,y
descent
程序核心部分,调用上面的模块实现梯度下降求解系数
import time
#梯度下降求解
def descent(data, theta,batchSize, stopType,thresh, alpha):
#batchSize = 样本总量,1,或者指定量,对于3种下降方式
init_time = time.time()
i = 0 #迭代次数
k = 0 #batch
X,y = shuffleData(data)
grad = np.zeros(theta.shape) #梯度向量
costs = [cost(X,y,theta)] #损失值
while True:
grad = gradient(X[k:k+batchSize],y[k:k+batchSize],theta)
k += batchSize
n = batchSize #自己加的
if k >= n:
k = 0
X,y = shuffleData(data) #重新洗牌
theta = theta - alpha*grad
costs.append(cost(X,y,theta))
i += 1
if stopType == STOP_ITER:
value = i
elif stopType == STOP_COST:
value = costs
elif stopType == STOP_GRAD:
value = grad
if stopCriterion(stopType,value,thresh):
break
return theta,i-1,costs,grad,time.time()-init_time
外包绘图模块
def runExpe(data, theta,batchSize, stopType,thresh, alpha):
theta,iter,costs,grad,dur = descent(data, theta,batchSize, stopType,thresh, alpha)
name = 'Original' if (data[:,1]>2).sum()>1 else "Scaled"
name += " data - learning rate: {} - ".format(alpha)
n = data.shape[0]#教程中为n
if batchSize == n:#pdData.shape[0] = n 教程中为n
strDescType = "Gradient"
elif batchSize == 1:
strDescType = "Stochastic"
else:
strDescType = "Mini-batch ({})".format(batchSize)
name += strDescType + " descent - Stop: "
if stopType == STOP_ITER:
strStop = "{} iterations".format(thresh)
elif stopType == STOP_COST:
strStop = "costs change < {}".format(thresh)
else:
strStop = "gradient norm < {}".format(thresh)
name += strStop
print("***{}\nTheta: {} - Iter: {} - Last cost: {:03.2f} - Duration: {:03.2f}s".format(
name, theta, iter, costs[-1], dur))
fig, ax = plt.subplots(figsize=(12, 4))
ax.plot(np.arange(len(costs)), costs, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title(name.upper() + ' - Error vs. Iteration')
plt.show()
return theta
最后只返回参数
分析不同的停止策略
不同的停止策略会导致最后得出的结果完全不同
设置迭代次数
n = 100
runExpe(orig_data,theta,n,STOP_ITER,thresh=5000,alpha= 0.000001)
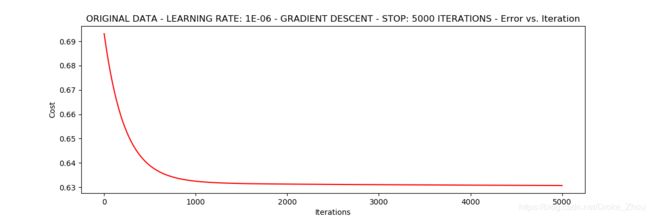
根据损失值停止
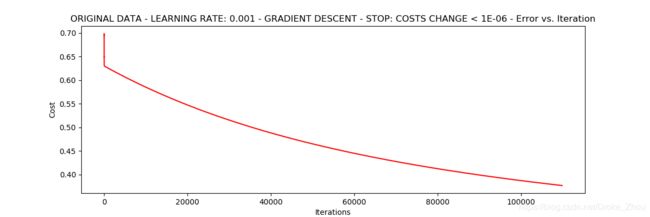
设定阈值1E-6,差不多需要110,000次迭代
runExpe(orig_data,theta,n,STOP_COST,thresh=0.000001,alpha=0.001)
根据梯度变化停止
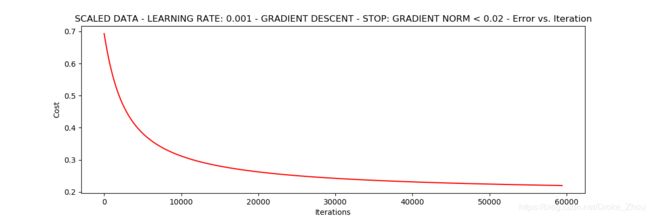
设定阈值0.05,差不多需要40000次迭代
runExpe(orig_data,theta,n,STOP_GRAD,thresh=0.05,alpha=0.001)

不同梯度下降方法
Stochastic descent
runExpe(orig_data,theta,1,STOP_ITER,thresh=5000,alpha=0.001)
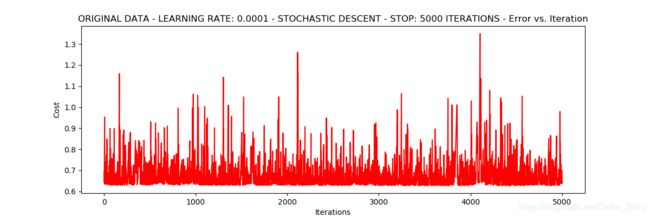
优化
runExpe(orig_data,theta,1,STOP_ITER,thresh=10000,alpha=0.000005)

明显在增加迭代次数后,结果有收敛趋势了。
Mini-batch descent
runExpe(orig_data,theta,16,STOP_ITER,thresh=5000,alpha=0.001)
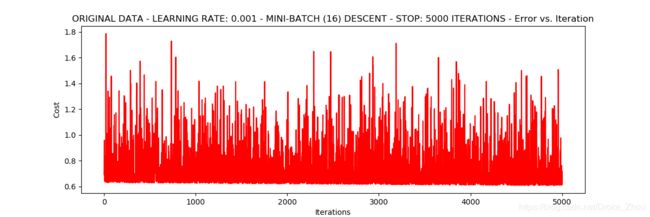
优化:将数据进行标准化操作
# 数据标准化[-1,1] 将数据按其属性(按列进行减去其均值,再除以方差。最后得到的结果为均值为0,方差为1的数据
from sklearn import preprocessing as pp
scaled_data = orig_data.copy()
scaled_data[:,1:3] = pp.scale(orig_data[:,1:3])
runExpe(scaled_data,theta,16,STOP_ITER,thresh=5000,alpha=0.001)
# 结论,数据预处理十分重要
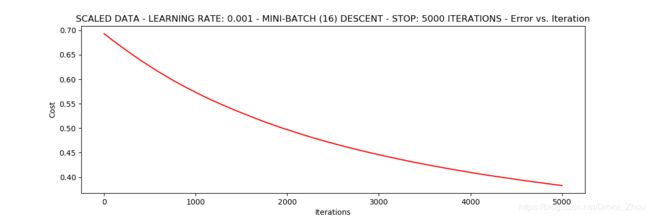
可见,在相同训练次数,学习率的情况下,对数据进行标准化后得到的结果更加准确。
accuracy
# 设定阈值为0.5 大于0.5可以录取否则不行
def predict(X,theta):
return [1 if x >= 0.5 else 0 for x in model(X,theta)]
theta = runExpe(scaled_data,theta,100,STOP_GRAD,0.02,alpha=0.001)
print(theta)
scaled_X = scaled_data[:,:3]
y = scaled_data[:,3]
print(y)
#runExpe(scaled_data,theta,100,STOP_GRAD,thresh=0.01,alpha=0.001)
predictions = predict(scaled_X,theta)
correct = [1 if (a == 1 and b == 1) or (a == 0 and b == 0) else 0 for (a,b) in zip(predictions,y)]
accuracy = (sum(map(int,correct)) % len(correct))
print("accuracy = {}%".format(accuracy))
accuracy = 89%
最后模型得到的结果和实际值吻合度较高。
小结
通过该章的介绍,基本可以实现逻辑回归。通过对该方法的学习,发现相同的模型在不同的终止方式、不同的训练次数、损失、梯度的情况下有不同的效果。特别是数据标准化前和标准化后的处理有很大的差异,所以要多尝试不同的指定参数。详细的分析方式在之后的内容中介绍。