CGAN minist上的简单实现
CGAN的超简单实现,基于pytorch 0.4。
刚开始搭建了一个原始GAN网络,没多久就遇到模型崩溃的问题,生成的样本丰富性很少,所以索性直接改成CGAN ,整个原理还是很简单的,改起来很快,主要是参数调整真的让人头大。
GAN 训练了35个epoch的效果,几乎只生成3和5的样本。

#CGAN训练效果,第8个epoch , 可以看到生成样本丰富性很高,而且质量很不错。
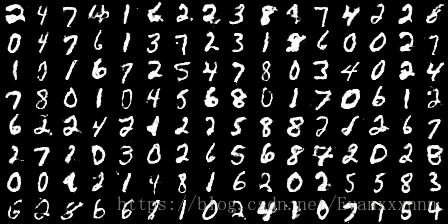
代码
代码有点点乱,将就能用就行~
#CGANnets
import torch
import torch.nn as nn
import torch.functional as F
#变成CGAN 在fc层嵌入 one-ho编码
class discriminator(nn.Module):
def __init__(self):
super(discriminator,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1,32,5),
nn.LeakyReLU(0.2,True),
nn.MaxPool2d(2,stride = 2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5,padding=2),
nn.LeakyReLU(0.2, True),
nn.MaxPool2d(2, stride=2),
)
self.fc = nn.Sequential(
nn.Linear(64*6*6+10,1024),
nn.LeakyReLU(0.2,True),
nn.Linear(1024,1),
nn.Sigmoid()
)
def forward(self, x,labels):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1)
x = torch.cat((x,labels),1)
x = self.fc(x)
return x
class generator(nn.Module):
def __init__(self, input_size, num_feature):
super(generator, self).__init__()
self.fc = nn.Linear(input_size+10, num_feature) # batch, 3136=1x56x56
self.br = nn.Sequential(
nn.BatchNorm2d(1),
nn.ReLU(True)
)
self.downsample1 = nn.Sequential(
nn.Conv2d(1,50,3,stride=1,padding=1),
nn.BatchNorm2d(50),
nn.ReLU(True)
)
self.downsample2 = nn.Sequential(
nn.Conv2d(50,25,3,stride=1,padding=1),
nn.BatchNorm2d(25),
nn.ReLU(True)
)
self.downsample3 = nn.Sequential(
nn.Conv2d(25,1,2,stride = 2),
nn.Tanh()
)
def forward(self,z,labels):
'''
:param x: (batchsize,100)的随机噪声
:param label: (batchsize,10) 的one-hot 标签编码
:return:
'''
x = torch.cat((z,labels),1) #沿1维拼接
x = self.fc(x)
x = x.view(x.size(0),1,56,56)
x = self.br(x)
x = self.downsample1(x)
x = self.downsample2(x)
x = self.downsample3(x)
return x
##train.py
import torch
import torch.nn as nn
import torch.functional as F
import os
from tensorboardX import SummaryWriter
import torchvision
from torchvision import datasets
from torchvision import transforms
import numpy as np
from torchvision.utils import save_image,make_grid
import cGANnets
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#超参数
batchsize = 128
z_dimension = 100
num = 25
epoch_num = 100
scale = 1
criterion = nn.BCELoss()
writer = SummaryWriter()
def train_1(d_optimizer, g_optimizer, dataloader, epoch_num, G, D, criterion):
'''
#这个策略训练失败
:param d_optimizer:
:param g_optimizer:
:param dataloader:
:param epoch_num:
:param G:
:param D:
:param criterion:
:return:
'''
G.to(device)
D.to(device)
# g_optimizer.to(device)
# d_optimizer.to(device)
# criterion.to(device)
step = 0
for epoch in range(epoch_num):
for i, (imgs, real_labels) in enumerate(dataloader):
num_img = imgs.size(0)
real_label = torch.Tensor(torch.ones(num_img)).to(device)
fake_label = torch.Tensor(torch.zeros(num_img)).to(device)
real_labels = generatelabels(batchsize, real_labels) # 产生对应的one-hot编码标签
real_labels.requires_grad = True
imgs = imgs.to(device)
num_img = imgs.size(0)
real_out = D(imgs, real_labels) # 输入真实图片得到结果
real_scores = real_out
d_loss_real = criterion(real_out, real_label)
z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
fake_labels = generatelabels(batchsize) # 生成编码标签
fake_labels.requires_grad = True
z.requires_grad = True
fake_img = G(z, fake_labels)
fake_out = D(fake_img, fake_labels)
d_loss_fake = criterion(fake_out, fake_label)
fake_scores = fake_out #
# 先更新判别器参数 然后再更新生成器参数
d_loss = d_loss_real + d_loss_fake
writer.add_scalar('d_loss', scale * d_loss, step)
# 第一个epoch先充分训练判别器 所以每十次迭代才更新一次生成器
if epoch == 0:
d_optimizer.zero_grad() # 梯度清零
d_loss.backward() # 计算梯度
d_optimizer.step() # 更新参数
# 更新生成器
if i % 10 == 0:
z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
z.requires_grad = True
fake_img = G(z, fake_labels)
fake_out = D(fake_img, fake_labels)
g_loss = criterion(fake_out, real_label)
writer.add_scalar('g_loss', scale * g_loss, step)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
else: # 后面的迭代每隔25次迭代才更新一次判别器
if i % num == 0:
d_optimizer.zero_grad() # 梯度清零
d_loss.backward() # 计算梯度
d_optimizer.step() # 更新参数
# 更新生成器
z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
z.requires_grad = True
fake_labels = generatelabels(batchsize)
fake_labels.requires_grad = True
fake_img = G(z, fake_labels)
fake_out = D(fake_img, fake_labels)
g_loss = criterion(fake_out, real_label)
writer.add_scalar('g_loss', scale * g_loss, step)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % 50 == 0:
print('Epoch[{}/{}],d_loss: {:.6f},g_loss: {:.6f}'
'D real: {:.6f}, D fake: {:.6f}'.format(
epoch, epoch_num, d_loss * scale, g_loss * scale,
real_scores.data.mean(), fake_scores.data.mean()
)
)
step += 1
if epoch == 0:
real_images = to_img(imgs.cpu().data)
save_image(real_images, './img/real_images.png', nrow=16, padding=0)
fake_images = to_img(fake_img.cpu().data)
grid = make_grid(fake_images, nrow=16, padding=0)
writer.add_image('image', grid, epoch)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1), nrow=16, padding=0)
# 训练完成后保存模型文件
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
def train_2(d_optimizer, g_optimizer, dataloader, epoch_num, G, D, criterion):
'''
:param d_optimizer:
:param g_optimizer:
:param dataloader:
:param epoch_num:
:param G:
:param D:
:param criterion:
:return:
'''
G.to(device)
D.to(device)
# g_optimizer.to(device)
# d_optimizer.to(device)
# criterion.to(device)
step = 0
for epoch in range(epoch_num):
for i, (imgs, real_labels) in enumerate(dataloader):
num_img = imgs.size(0)
real_label = torch.Tensor(torch.ones(num_img)).to(device)
fake_label = torch.Tensor(torch.zeros(num_img)).to(device)
real_labels = generatelabels(batchsize, real_labels) # 产生对应的one-hot编码标签
real_labels.requires_grad = True
imgs = imgs.to(device)
num_img = imgs.size(0)
real_out = D(imgs, real_labels) # 输入真实图片得到结果
real_scores = real_out
d_loss_real = criterion(real_out, real_label)
z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
fake_labels = generatelabels(batchsize) # 生成编码标签
fake_labels.requires_grad = True
z.requires_grad = True
fake_img = G(z, fake_labels)
fake_out = D(fake_img, fake_labels)
d_loss_fake = criterion(fake_out, fake_label)
fake_scores = fake_out #
# 先更新判别器参数 然后再更新生成器参数
d_loss = d_loss_real + d_loss_fake
writer.add_scalar('d_loss', scale * d_loss, step)
# 第一个epoch先充分训练判别器 所以每十次迭代才更新一次生成器
# if epoch == 0:
d_optimizer.zero_grad() # 梯度清零
d_loss.backward() # 计算梯度
d_optimizer.step() # 更新参数
# # 更新生成器
# if i % 10 == 0:
z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
z.requires_grad = True
fake_img = G(z, fake_labels)
fake_out = D(fake_img, fake_labels)
g_loss = criterion(fake_out, real_label)
writer.add_scalar('g_loss', scale * g_loss, step)
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# else: # 后面的迭代每隔25次迭代才更新一次判别器
# if i % num == 0:
# d_optimizer.zero_grad() # 梯度清零
# d_loss.backward() # 计算梯度
# d_optimizer.step() # 更新参数
#
# # 更新生成器
# z = torch.Tensor(torch.randn(num_img, z_dimension)).to(device)
# z.requires_grad = True
# fake_labels = generatelabels(batchsize)
# fake_labels.requires_grad = True
#
# fake_img = G(z, fake_labels)
# fake_out = D(fake_img, fake_labels)
# g_loss = criterion(fake_out, real_label)
#
# writer.add_scalar('g_loss', scale * g_loss, step)
#
# g_optimizer.zero_grad()
# g_loss.backward()
# g_optimizer.step()
if (i + 1) % 50 == 0:
print('Epoch[{}/{}],d_loss: {:.6f},g_loss: {:.6f}'
'D real: {:.6f}, D fake: {:.6f}'.format(
epoch, epoch_num, d_loss * scale, g_loss * scale,
real_scores.data.mean(), fake_scores.data.mean()
)
)
step += 1
if epoch == 0:
real_images = to_img(imgs.cpu().data)
save_image(real_images, './img/real_images.png', nrow=16, padding=0)
fake_images = to_img(fake_img.cpu().data)
grid = make_grid(fake_images, nrow=16, padding=0)
writer.add_image('image', grid, epoch)
save_image(fake_images, './img/fake_images-{}.png'.format(epoch + 1), nrow=16, padding=0)
# 训练完成后保存模型文件
torch.save(G.state_dict(), './generator.pth')
torch.save(D.state_dict(), './discriminator.pth')
def generatelabels(batchsize,real_labels =None):
x = torch.Tensor(torch.zeros(batchsize,10)).to(device)
if real_labels is None: #生成随机标签
y = [np.random.randint(0, 9) for i in range(batchsize)]
x[np.arange(batchsize), y] = 1
else:
x[np.arange(batchsize),real_labels] = 1
return x
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
#main.py
import torch
import torch.nn as nn
import torch.functional as F
import os
from tensorboardX import SummaryWriter
import torchvision
from torchvision import datasets
from torchvision import transforms
import numpy as np
from torchvision.utils import save_image,make_grid
import GANnet
from train import train_1,train_2
batchsize = 128
z_dimension = 100
num = 25
epoch_num = 100
scale = 1
criterion = nn.BCELoss()
if __name__ =="__main__":
if not os.path.exists('./img'):
os.mkdir('./img')
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean = (0.5,0.5,0.5),std = (0.5,0.5,0.5))
])
minist = datasets.MNIST(root='./data/',train = True,transform = img_transform,download=True)
dataloader = torch.utils.data.DataLoader(
dataset = minist,batch_size = batchsize,shuffle =True,
drop_last = True
)
G = GANnet.generator(z_dimension,3136)
D = GANnet.discriminator()
g_optimizer = torch.optim.Adam(G.parameters(),lr = 0.001)
d_optimizer = torch.optim.Adam(D.parameters(),lr = 0.001)
train_2(d_optimizer=d_optimizer,g_optimizer = g_optimizer,
dataloader = dataloader, epoch_num = epoch_num,
G=G,D=D,criterion = criterion)
参考博客
论文链接